













第1部では、いくつかの重要なトピックを取り上げました。ぜひ読んでみてください、次の部分はそれを基盤としています。
簡単な復習として、第1部では、データを大まかな視点で捉え、内部のデータと外部のデータを区別しました。また、スキーマとデータ契約についても議論し、それがどうやってストリームを時間とともに交渉、変更、進化させる手段を提供するかを説明しました。最後に、Fact(状態)およびDeltaイベントタイプについても触れました。Factイベントは状態のコミュニケーションとシステムの分離に最適であり、Deltaイベントは内部のデータ、例えばイベントソーシングや他の密接に結合されたユースケースに使用される傾向があります。
正規化されたテーブルは正規化されたストリームを作る
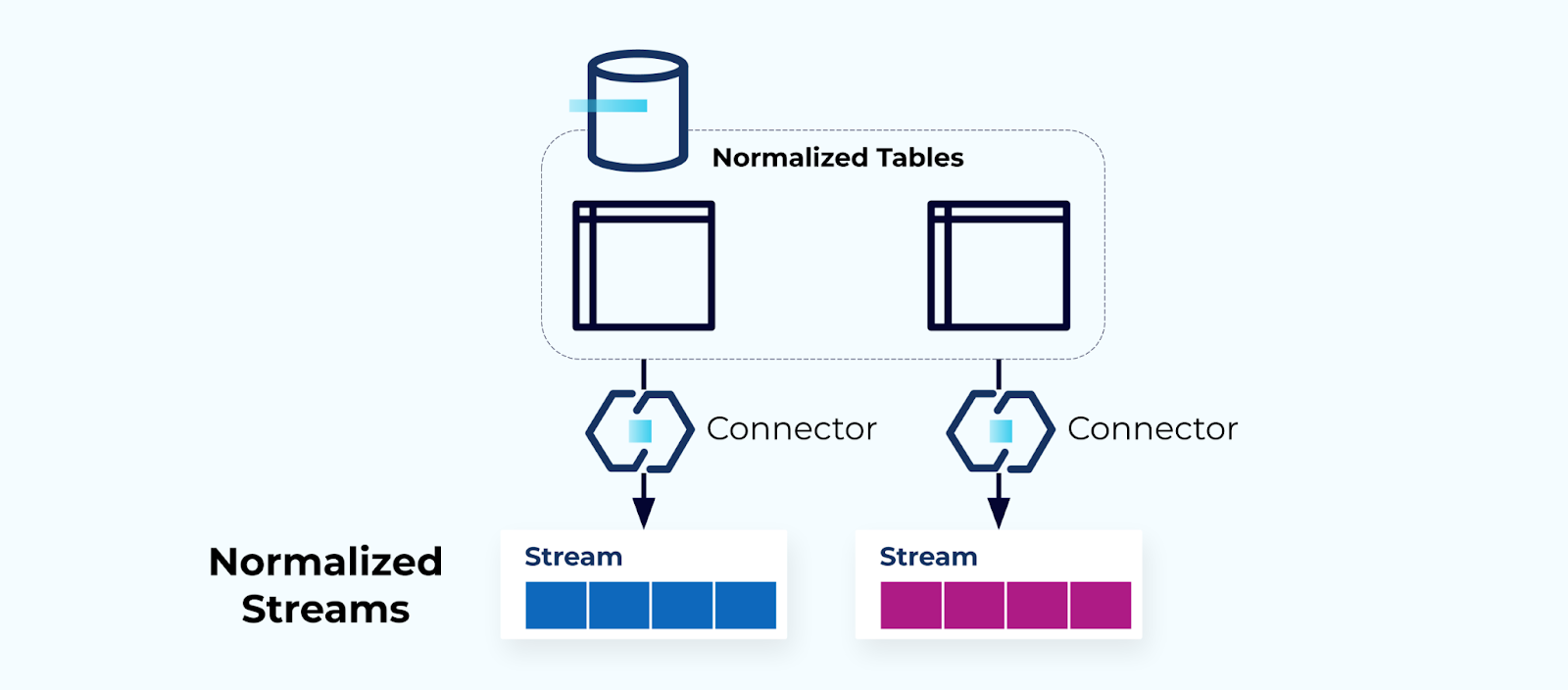
正規化されたテーブルは正規化されたイベントストリームにつながります。コネクタ(例:CDC)はデータベースから直接データを引き出し、ミラーされたイベントストリームのセットに取り込みます。これは理想的ではなく、内部のデータベーステーブルと外部のイベントストリームの間に強い結合を作り出します。
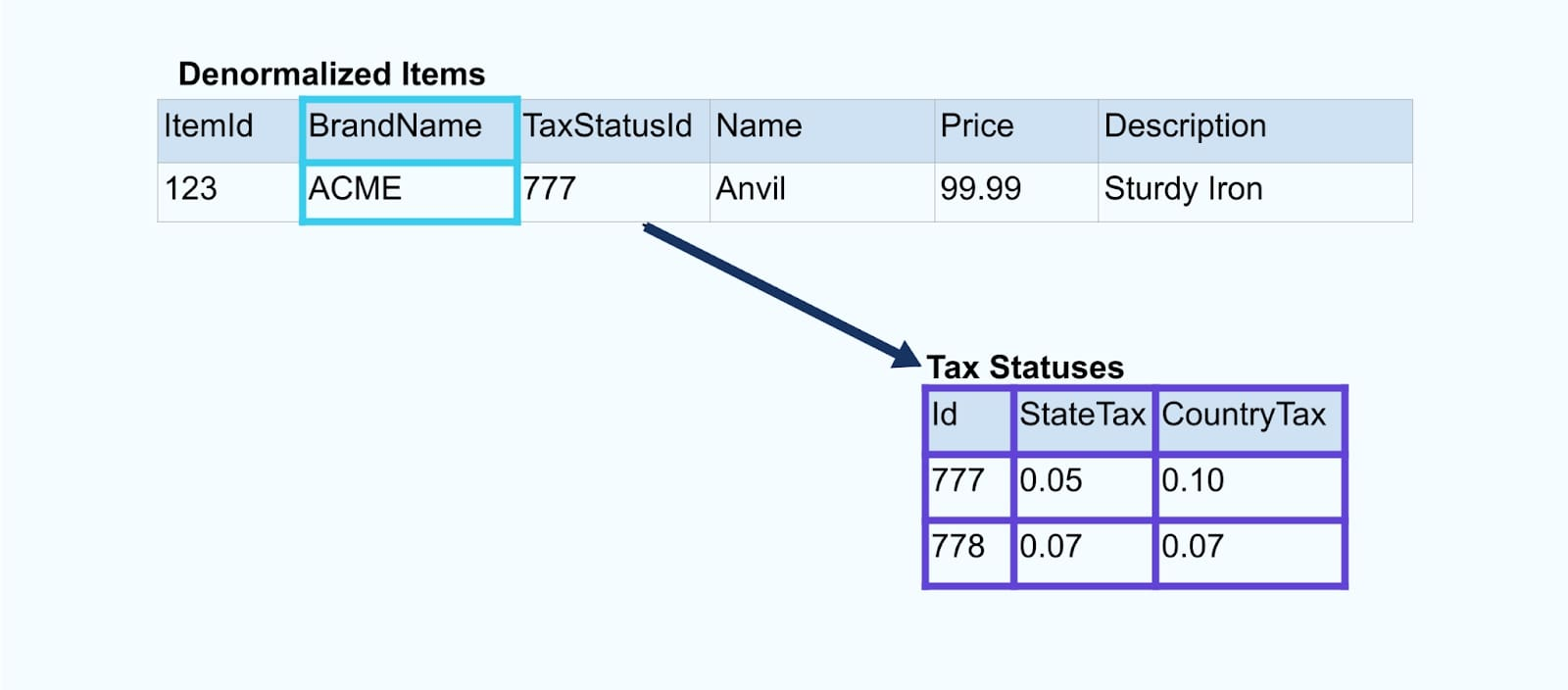
シンプルなeコマースのアイテムとそれに関連するブランドおよび税状態テーブルを考えてみましょう。
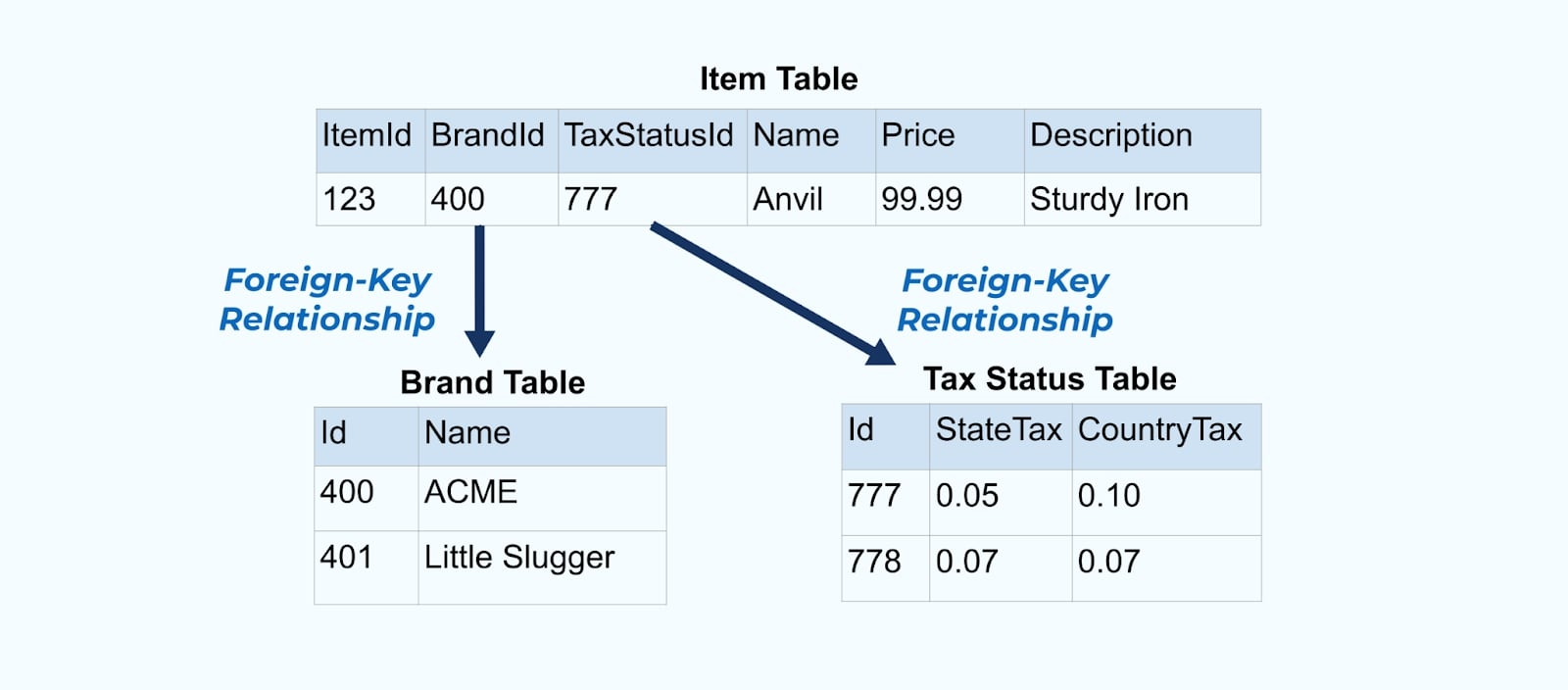
ブランドおよび税状態テーブルは、外部キー関係を通じてアイテムテーブルに関連しています。ここではテーブルに1つのアイテムしか示していませんが、販売する製品によっては数千(または数百万)になる可能性があります。
テーブルごとにコネクタを設定し、テーブルからデータを引き出し、イベントに組み立て、各テーブルを専用のイベントストリームに書き込むことが一般的です。
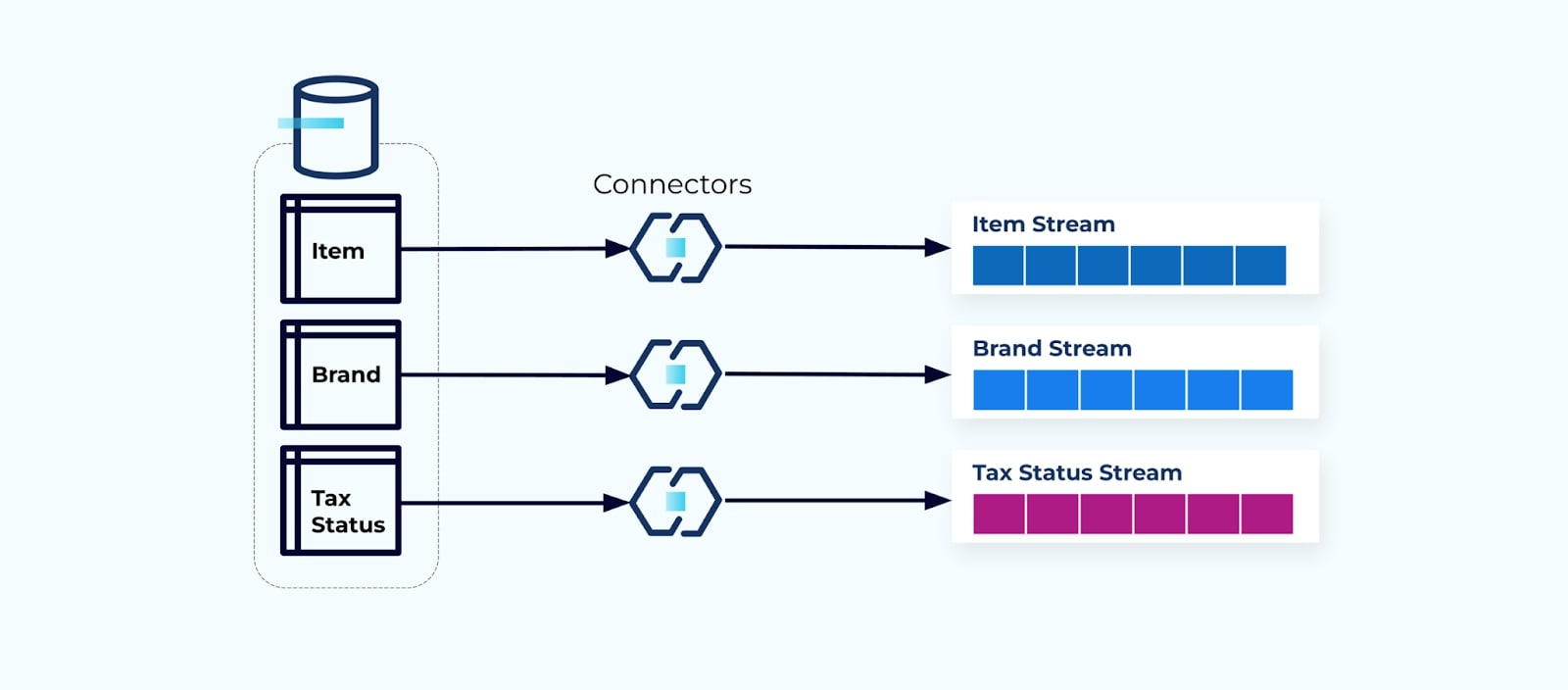
データベースの基礎となるテーブルを公開すると、テーブルごとに対応するイベントストリームが生成されます。この方法で始めるのは簡単ですが、複数の問題を引き起こし、それらは結合問題またはコスト問題に要約できます。それぞれを見てみましょう。
問題: コンシューマが内部モデルに結合する
ソースのアイテムテーブルをそのまま公開すると、コンシューマが直接それに結合する必要があります。ソースシステムのデータモデルの変更は、ダウンストリームのコンシューマに影響を与えます。
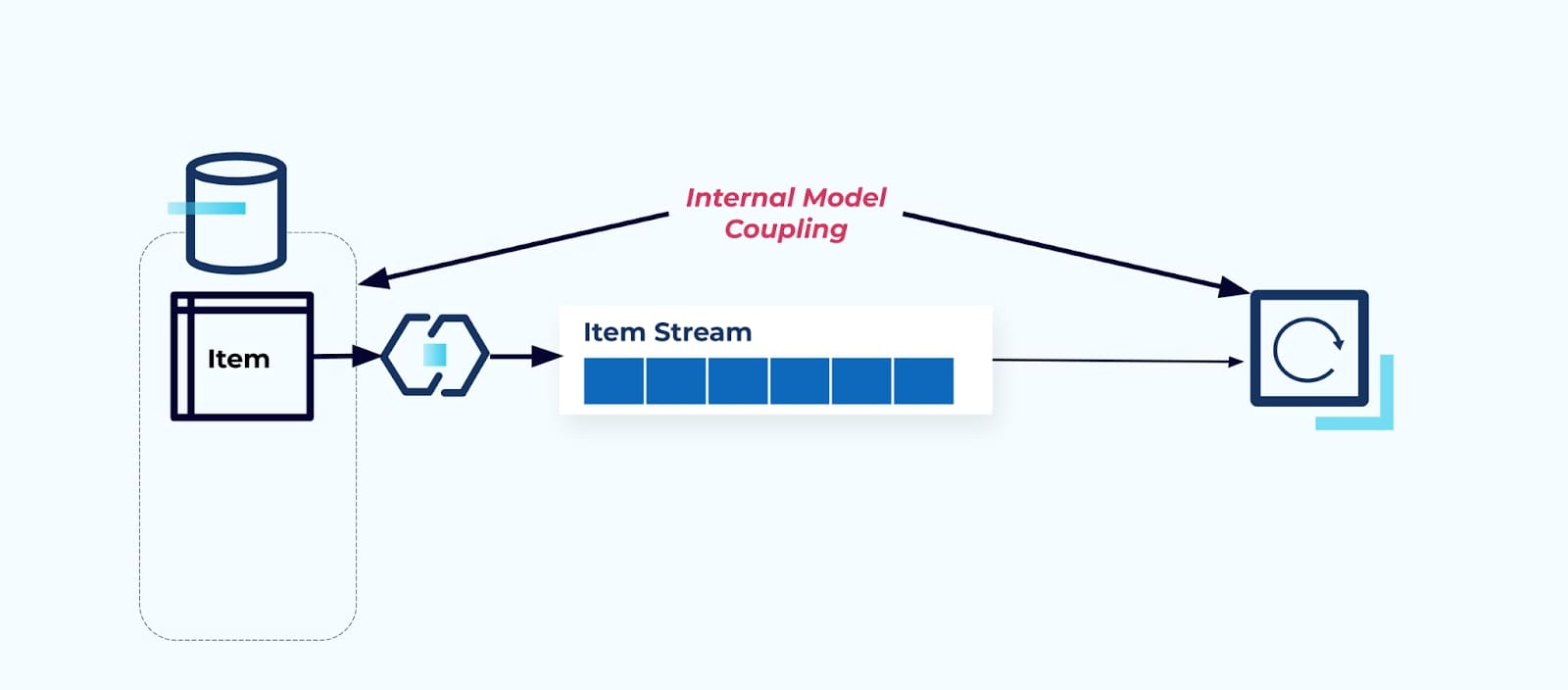
例えば、アイテムテーブルをリファクタリングして、Pricingを独自のテーブルに抽出するとします。
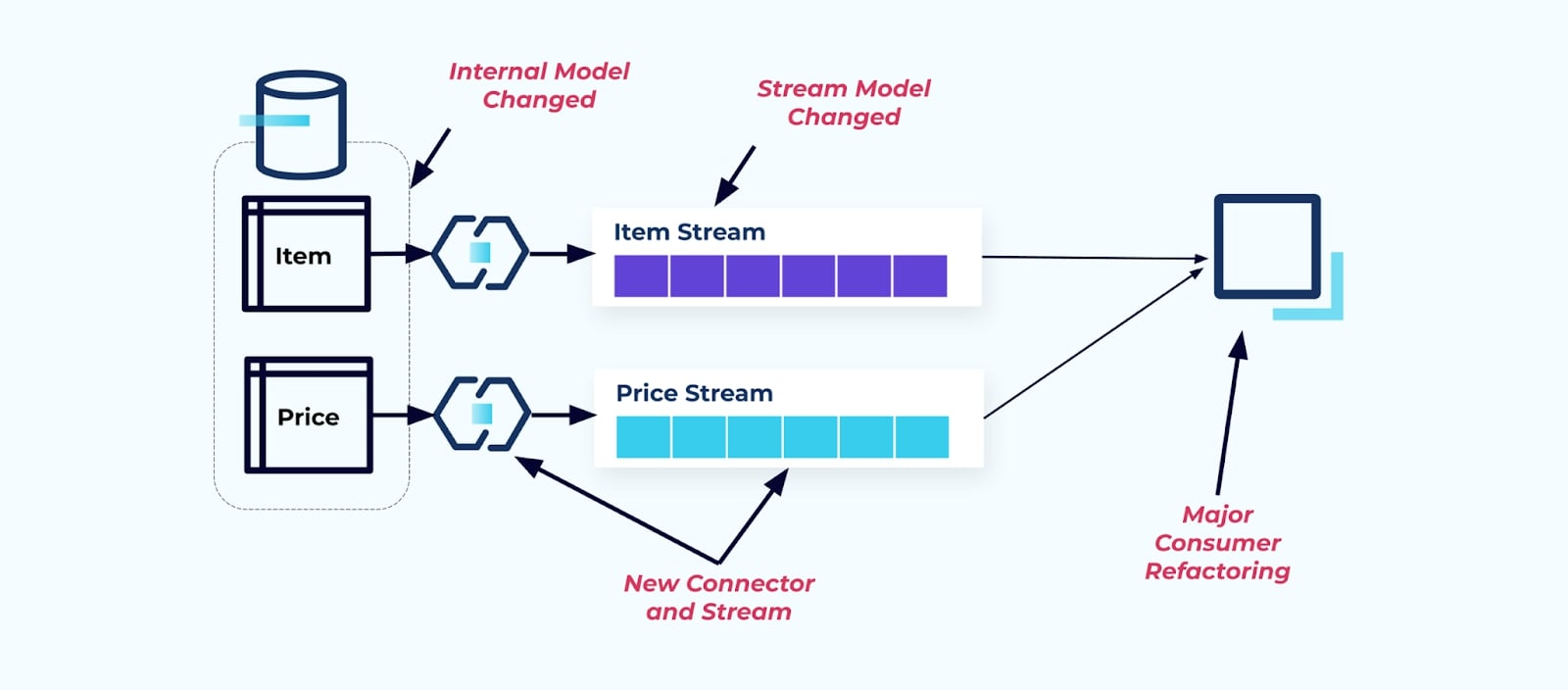
ソーステーブルのリファクタリングにより、アイテムストリームに対してデータコントラクトが破損します。コンシューマーはもはや元々期待していたのと同じアイテムデータを提供されなくなります。また、新しいコネクタを作成する必要があります — 新しいP価格ストリーム — そして最後に、コンシューマーロジックをリファクタリングして再度動作させる必要があります。列の名前変更、デフォルト値の変更、列型の変更は、内部データモデル上の緊密な結合によって導入される他の破壊的変更の形式です。
問題: ストリーミングジョインは(通常)高コストです
リレーショナルデータベースは、ジョインを迅速かつ低コストで解決するために設計されています。残念ながら、ストリーミングジョインはそうではありません。
アイテム、その税金、およびそのブランド情報にアクセスしたい2つのサービスを考えてみましょう。データが既に対応するストリームに書き込まれている場合、各コンシューマー(以下の画像の右側)は、Item、Brand、およびTaxを非正規化するために同じジョインを計算する必要があります。
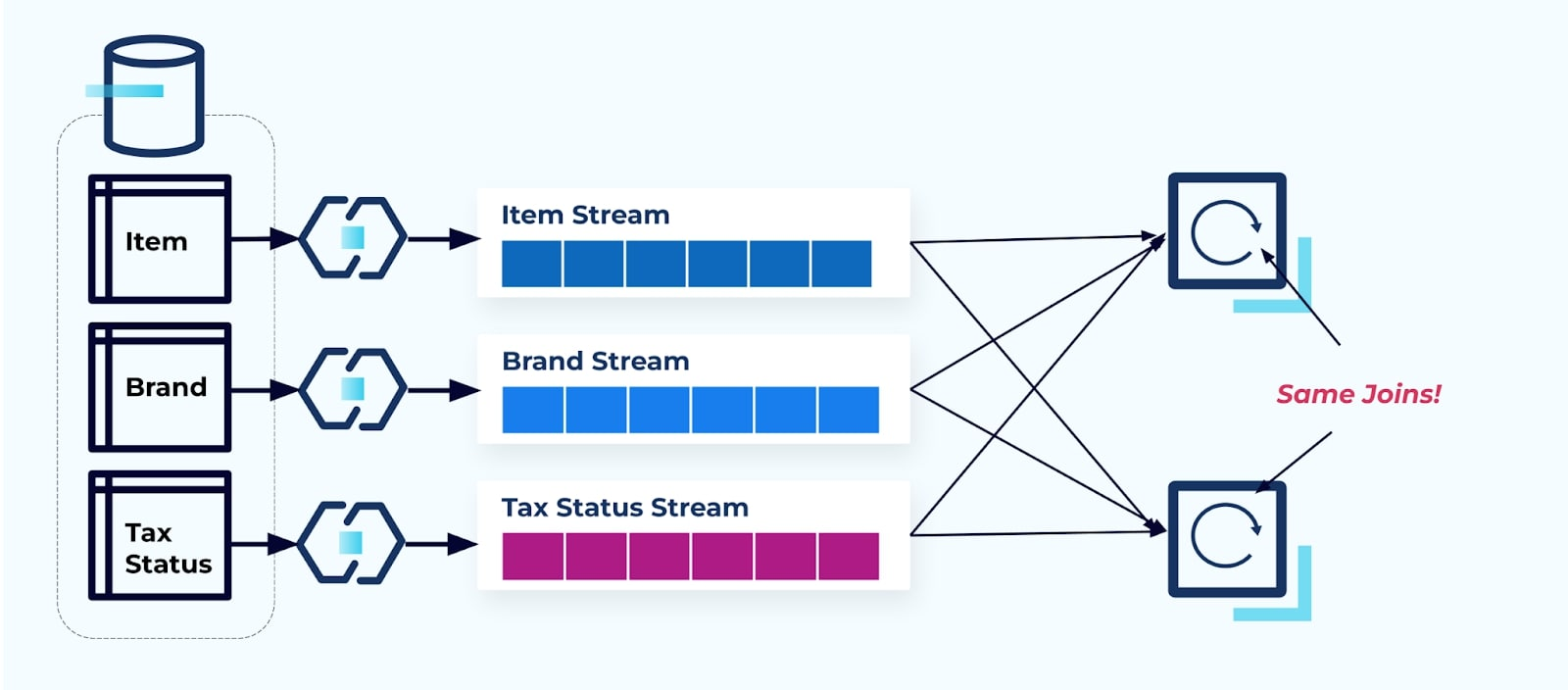
この戦略は、アプリケーションの書き込みにかかる開発時間と、ジョインの計算にかかるサーバーコストの両方で高コストを招く可能性があります。大規模なストリーミングジョインの解決には、データの大量のシャッフルが必要となり、これにより処理能力、ネットワーキング、およびストレージコストが発生します。さらに、すべてのストリーム処理フレームワークがジョインをサポートしているわけではなく、特に外部キーでのジョインはサポートされていないことが多いです。Flink、Spark、KSQL、Kafka Streams(例えば)など、ジョインをサポートするフレームワークでも、使用できるプログラミング言語は限定されており(Java、Scala、Python).
解決策:非正規化データの提供が最適
原則として、イベントストリームを消費者が使いやすいようにします。抽象化レイヤーを使用して、データを消費者に提供する前に非正規化し、消費者が結合するための明示的な外部モデルデータ契約(外部のデータ)を作成します。
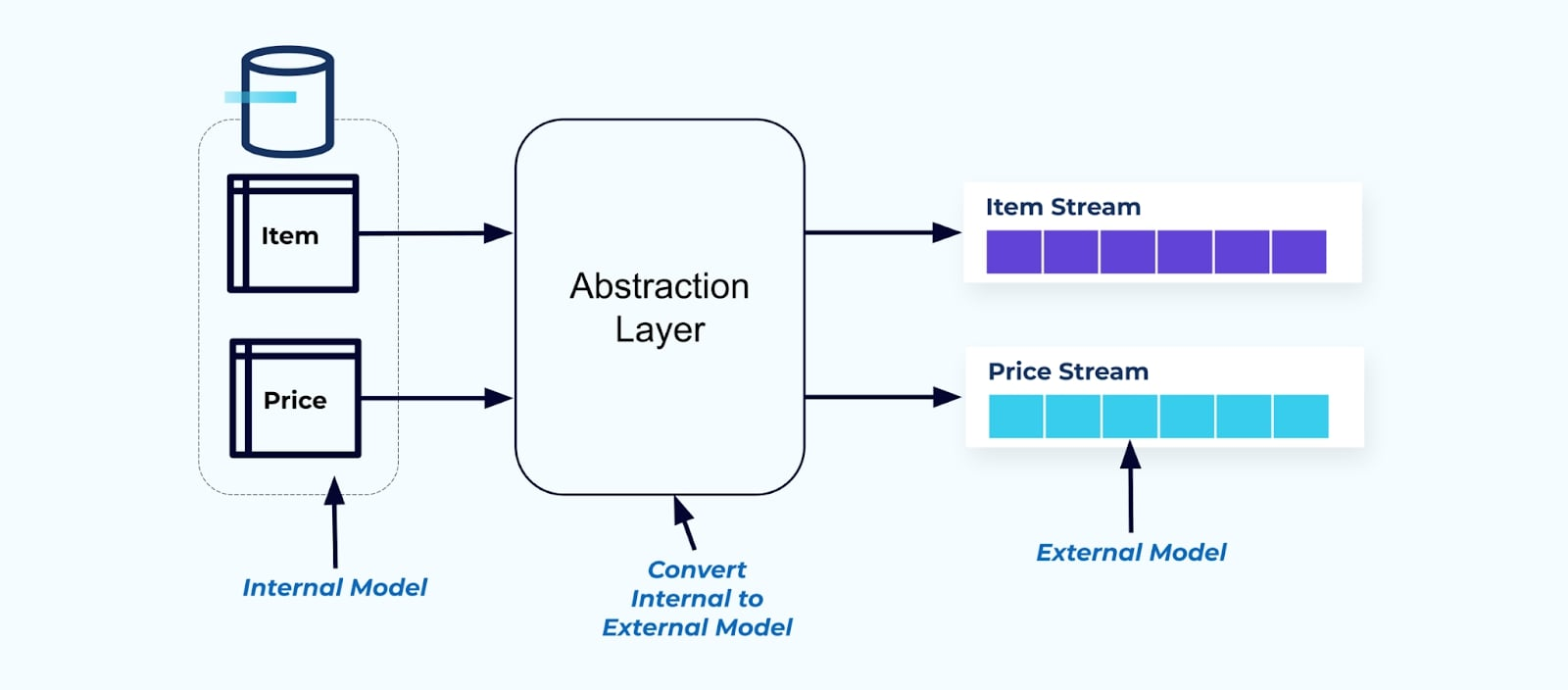
内部モデルの変更はソースシステム内で孤立しており、消費者は結合するための明確なデータ契約を取得します。ソースモデルに対する変更は、ソースシステムが消費者のためのデータ契約を維持する限り、妨げられることなく進行できます。
しかし、どこで非正規化するか?二つの選択肢があります:
- ソースシステムの外部で、専用のジョイナーサービスを使用して再構築する。
- ソースシステム内でのイベント作成時にトランザクショナルアウトボックスパターンを使用する。
それぞれの解決策を順番に見ていきましょう。
選択肢1:専用のジョイナーサービスを使用して非正規化する
この例では、左側のストリームはデータベースから来たテーブルを反映しています。
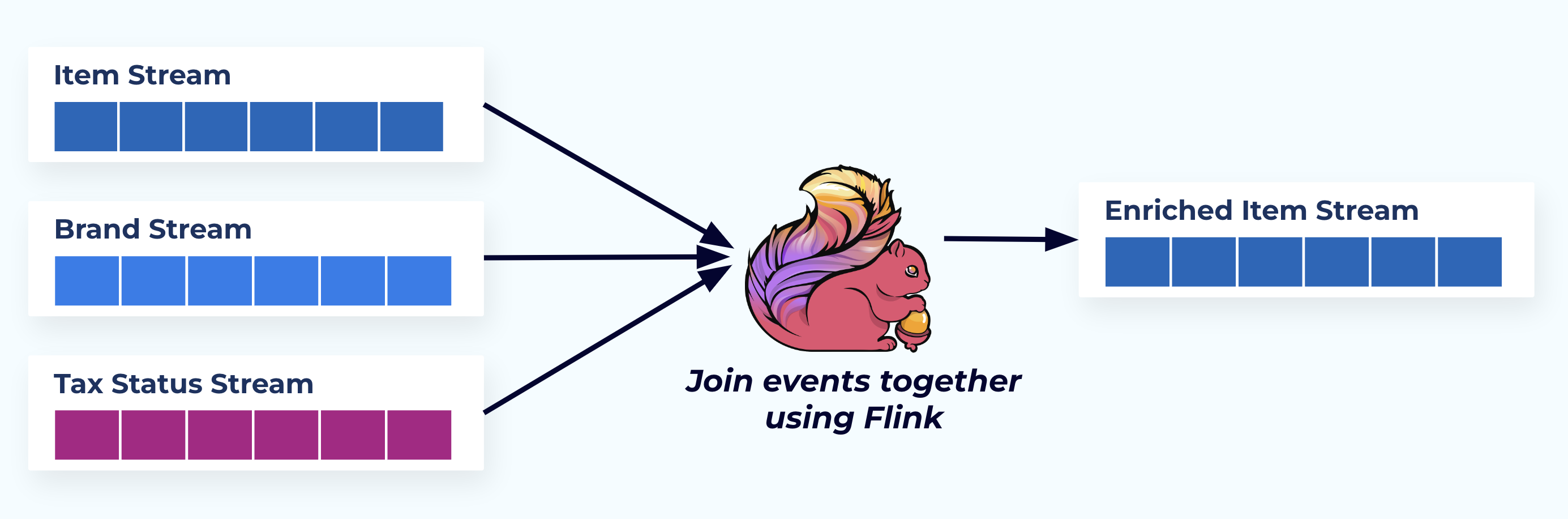
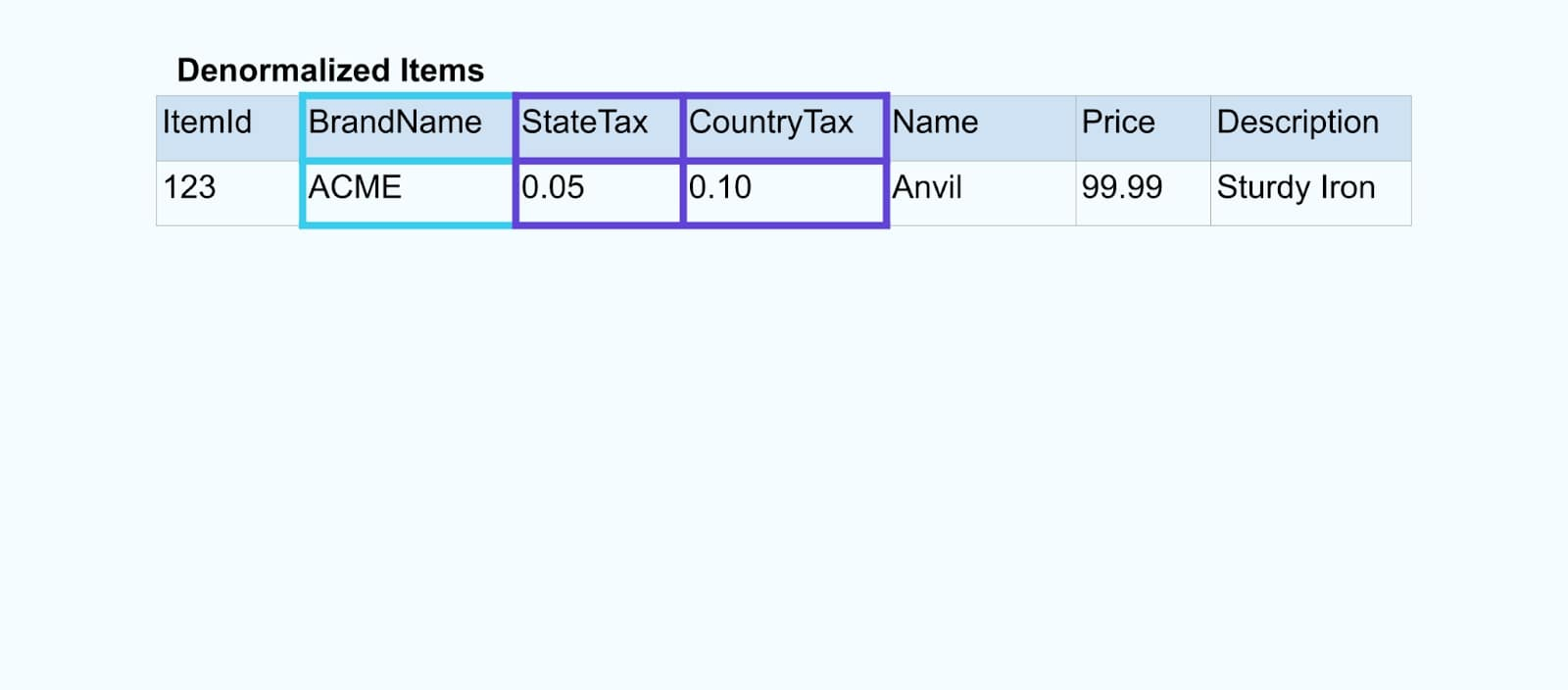
イベントを結合するために、外部キー関係に基づいた専用のアプリケーション(またはストリーミングSQLクエリ)を使用し、単一の豊富なアイテムストリームを発行します。

論理的には、関係を解決し、データを単一の非正規化行に押し込んでいます。
専用の結合ツールは、Apache Kafka StreamsやApache Flinkのようなストリーム処理フレームワークに依存して、プライマリキーと外部キーの両方の結合を解決します。これらはストリームデータを耐久性のある内部テーブル形式に具体化し、結合アプリケーションが任意の期間にわたってイベントを結合できるようにします – 時間制限されたウィンドウに限定されない。
FlinkやKafka Streamsを使用する結合ツールは、負荷に応じてスケールアップおよびスケールダウンが可能で、大量のトラフィックを処理できるため、非常にスケーラブルです。
ヒント:結合ツールにビジネスロジックを入れないでください。このパターンで成功するためには、結合されたデータが単なる非正規化結果としてソースを正確に表現する必要があります。ダウンストリームのコンシューマが非正規化データを単一の真実のソースとして使用して、独自のビジネスロジックを適用できるようにします。
ダウンストリームの結合ツールを使用したくない場合は、他のオプションもあります。次にトランザクショナルアウトボックスパターンを見てみましょう。
オプション2:トランザクショナルアウトボックスパターン
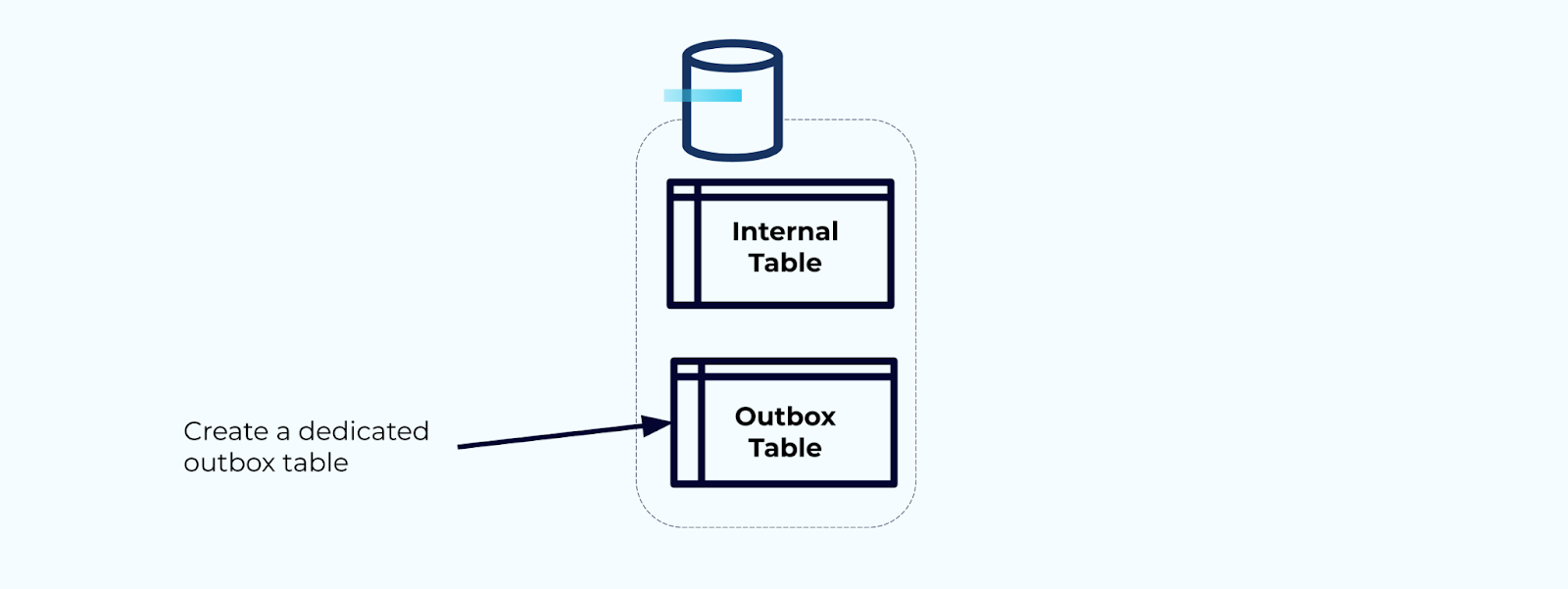
まず、ストリームにイベントを書き込むための専用のアウトボックステーブルを作成します。
第二に、すべての必要な内部テーブルの更新をトランザクション内に包み込むことです。トランザクションは、内部テーブルに対するすべての更新がアウトボックステーブルにも書き込まれることを保証します。
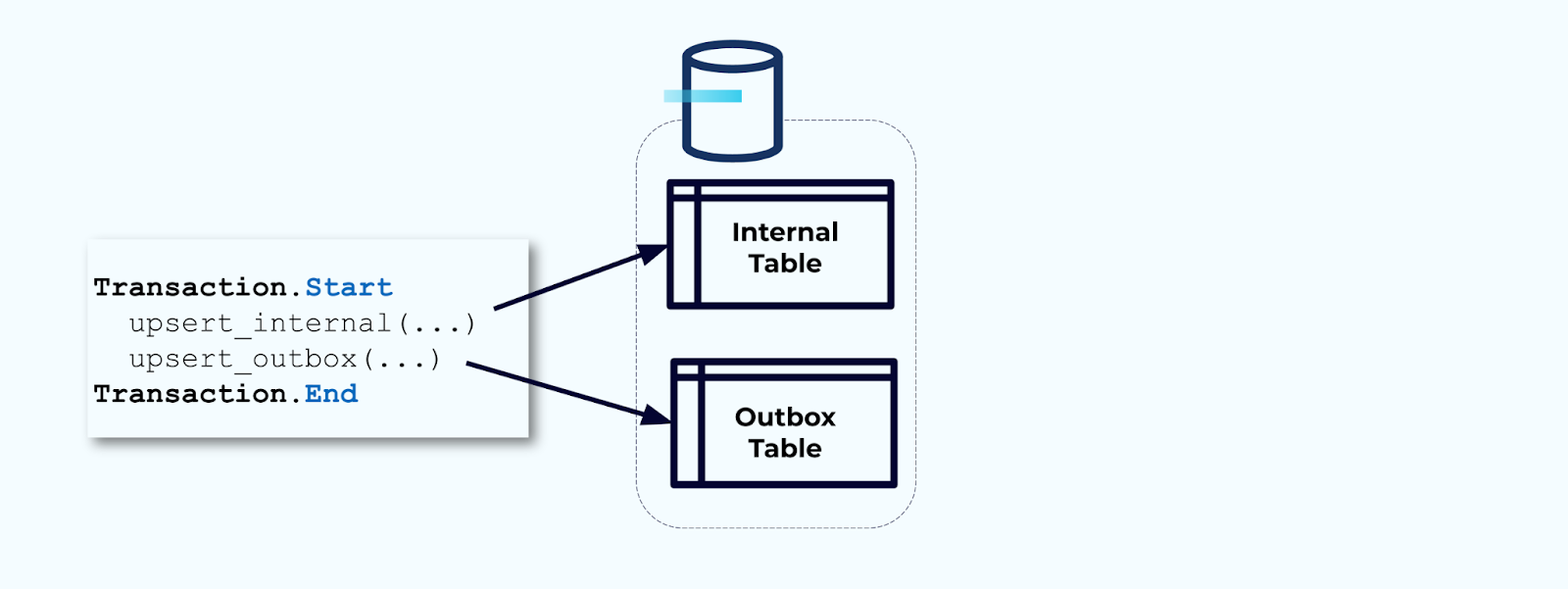
アウトボックスを使用すると、データを書き込む前に結合および変換できるため、内部データモデルを分離できます。アウトボックスは、内部のデータと外部のデータの間の抽象化層として機能し、消費者のためのデータ契約として作用します。
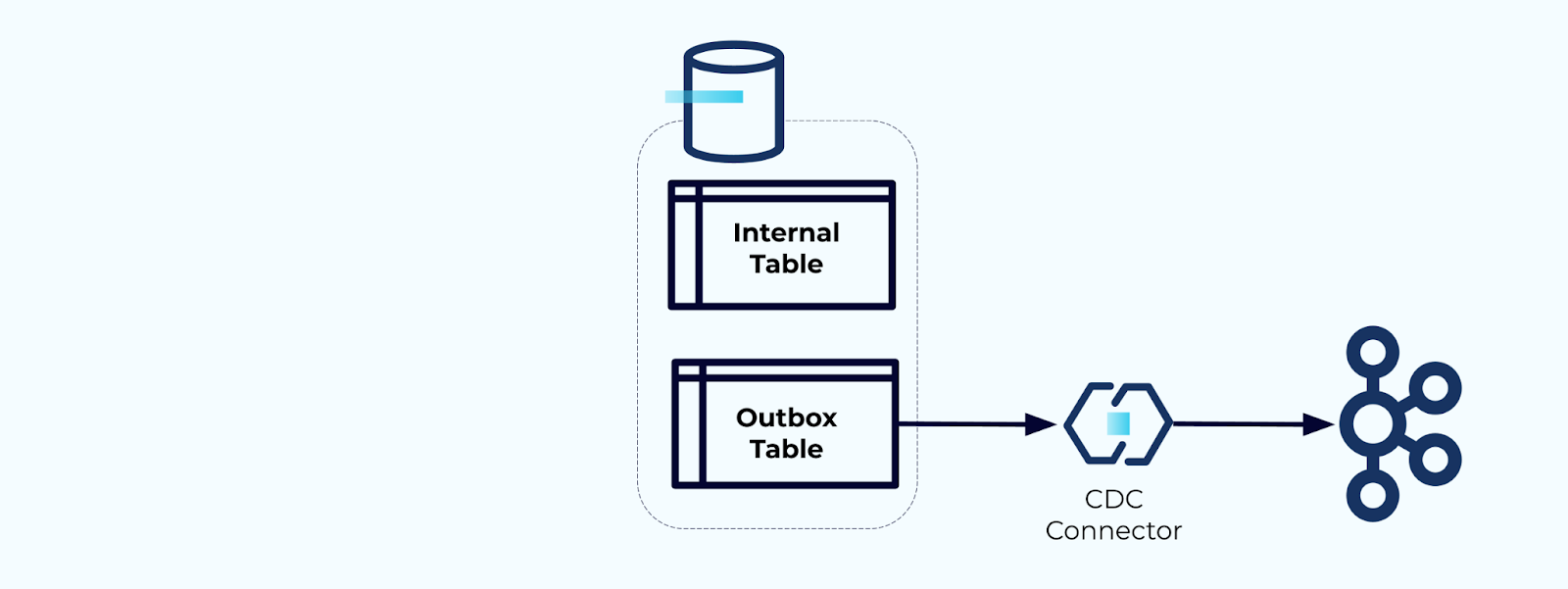
最後に、コネクタを使用してデータをアウトボックスからKafkaに移行できます。
アウトボックスが無限に成長しないようにする必要があります — CDCによってデータがキャプチャされた後に削除するか、定期的にスケジュールされたジョブで削除します。
例:ユーザー行動追跡イベントの非正規化
Webページやアプリケーションでのユーザー行動の追跡は、正規化されたイベントの一般的なソースです – Google Analyticsやファーストパーティのインハウスオプションを考えてください。しかし、イベントにはすべての情報を含めず、代わりに識別子に限定します(より速く、小さく、安価に)し、事実が作成された後に非正規化します。
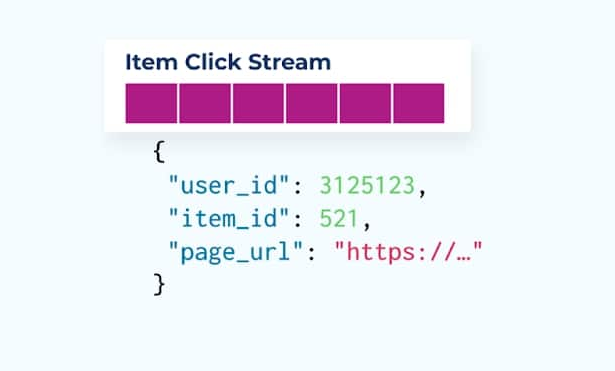
ユーザーがECアイテムをブラウジング中にアイテムをクリックしたときの詳細を示すアイテムクリックイベントのストリームを考えてみましょう。このアイテムクリックイベントには、名前、価格、説明などの豊富なアイテム情報は含まれておらず、基本的なidsだけです。
多くのクリックストリーム消費者が最初にするのは、それをアイテムファクトストリームと結合することです。そして、多くのクリックイベントを扱っているため、大量のコンピューティングリソースを使用していることが分かります。専用に構築されたFlinkアプリケーションは、アイテムクリックを詳細なアイテムデータと結合し、それを豊富なアイテムクリックストリームに送出することができます。
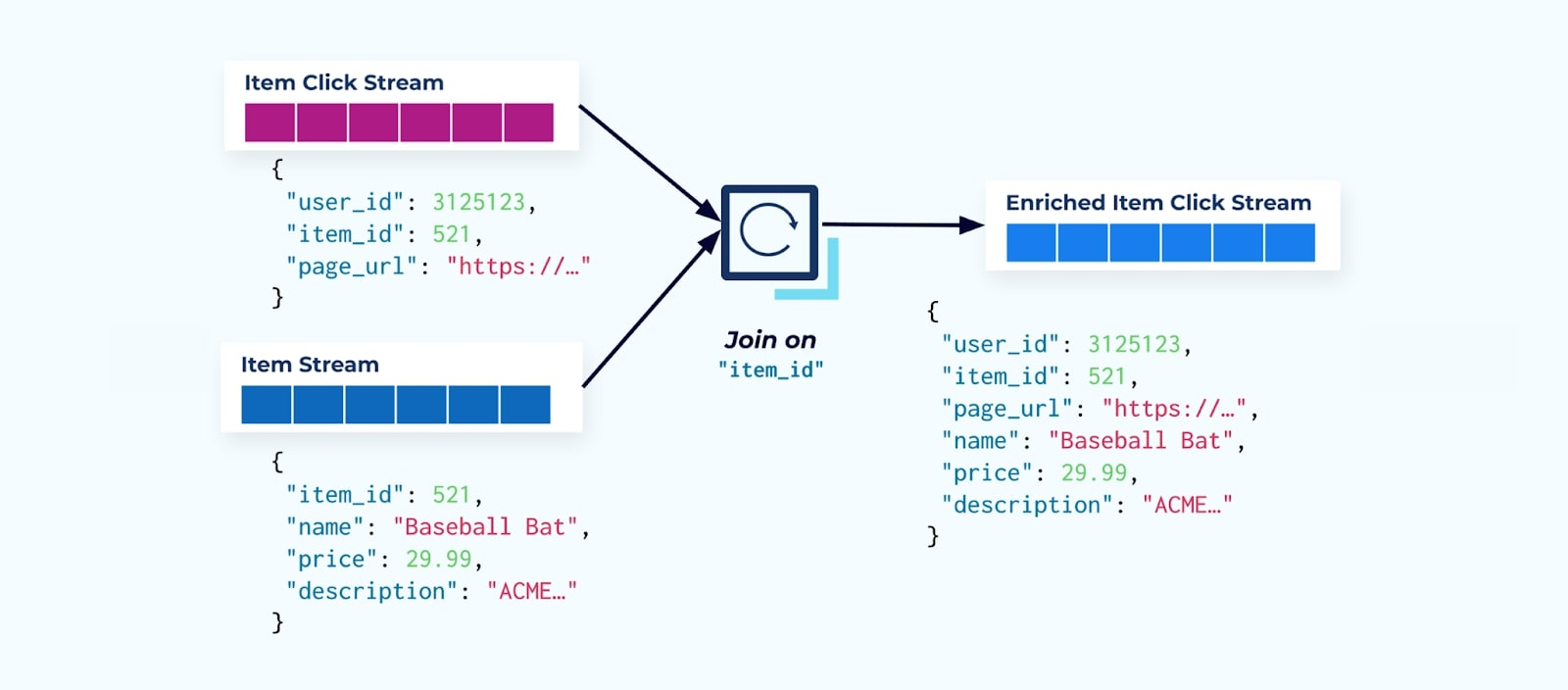
複数の部門(およびシステム)を持つ大企業は、データが異なるソースから来ることが多いでしょうし、ストリームジョイナーを使用して事後結合することが最も考えられます。
遅延変化次元に関する考慮事項
我们已经讨论了写入包含大数据集(例如,大文本块)的事件的性能考虑以及频繁变化的数据域(例如,项目库存)。现在,我们将看看遅延変化次元(SCD)、これは通常、外部キー関係を通じて示され、これもまた大きなデータ量の源となることがあります。
アイテムの例に戻りましょう。アイテムテーブルを更新する操作があるとします。アイテム名を「アンビル」から「アイアンアンビル」に変更します。
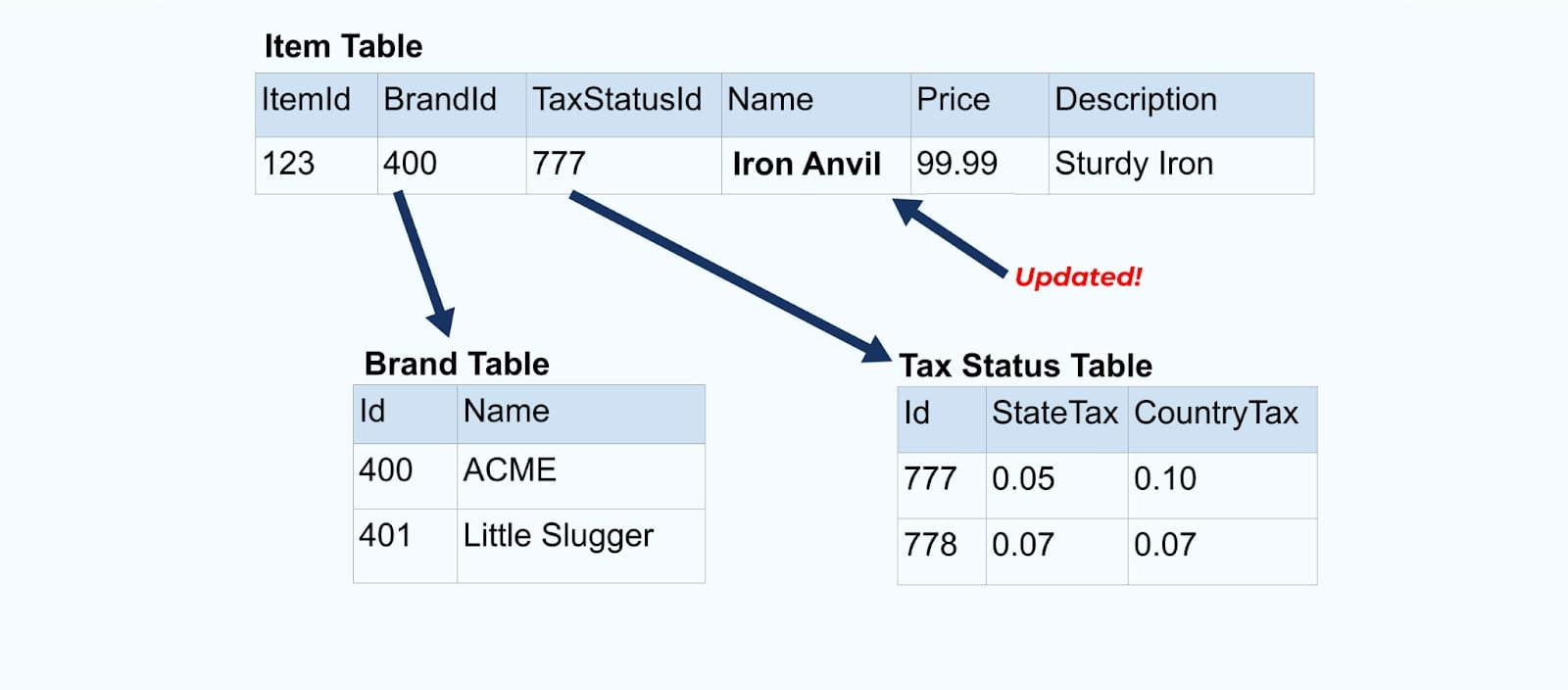
データベース内のデータを更新する際に、正規化されていない税状態とブランドテーブルを含む更新されたアイテムも出力します(たとえば、アウトボックスパターンを使用して)。
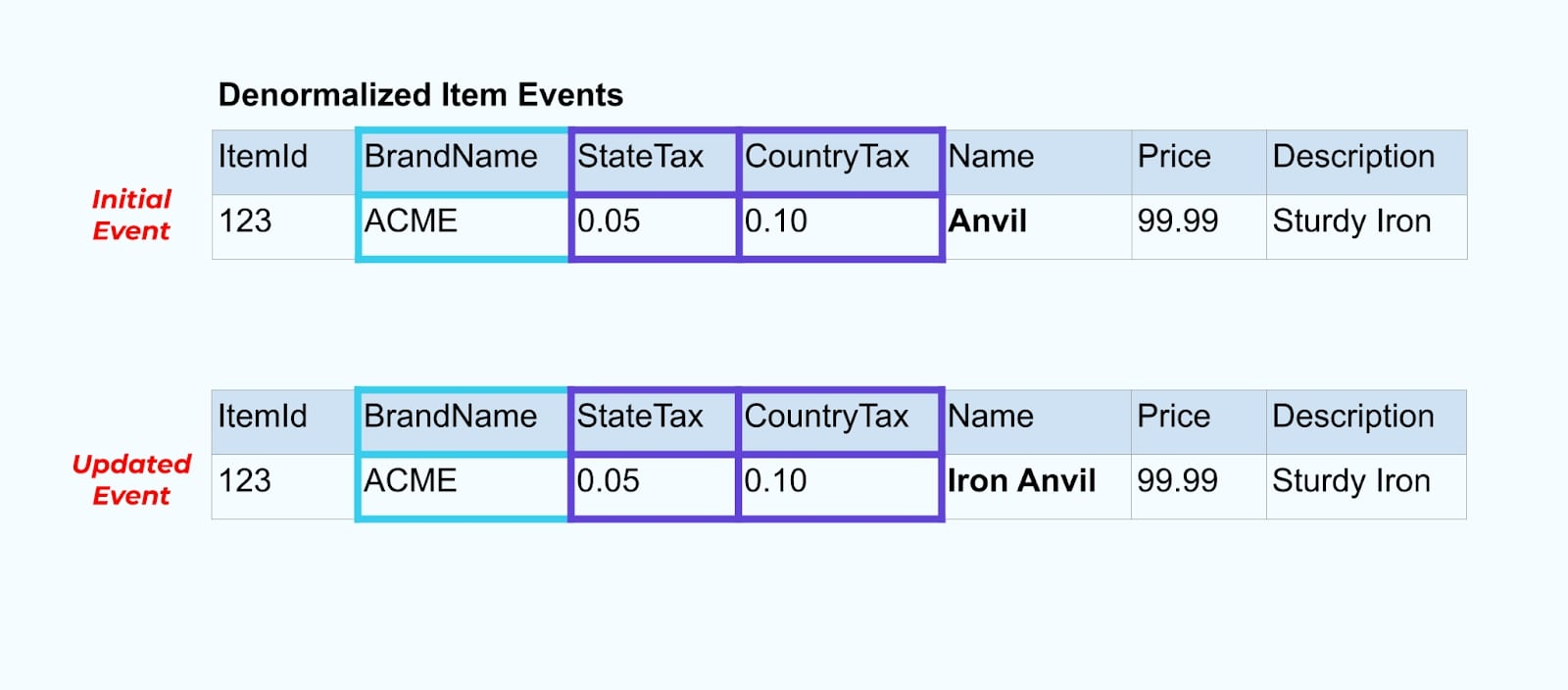
しかし、ブランドや税テーブルの値を変更する場合にも考慮する必要があります。これらの遅延変化次元の一つを更新することで、影響を受けるすべてのアイテムに対して非常に多くの更新が発生することがあります。
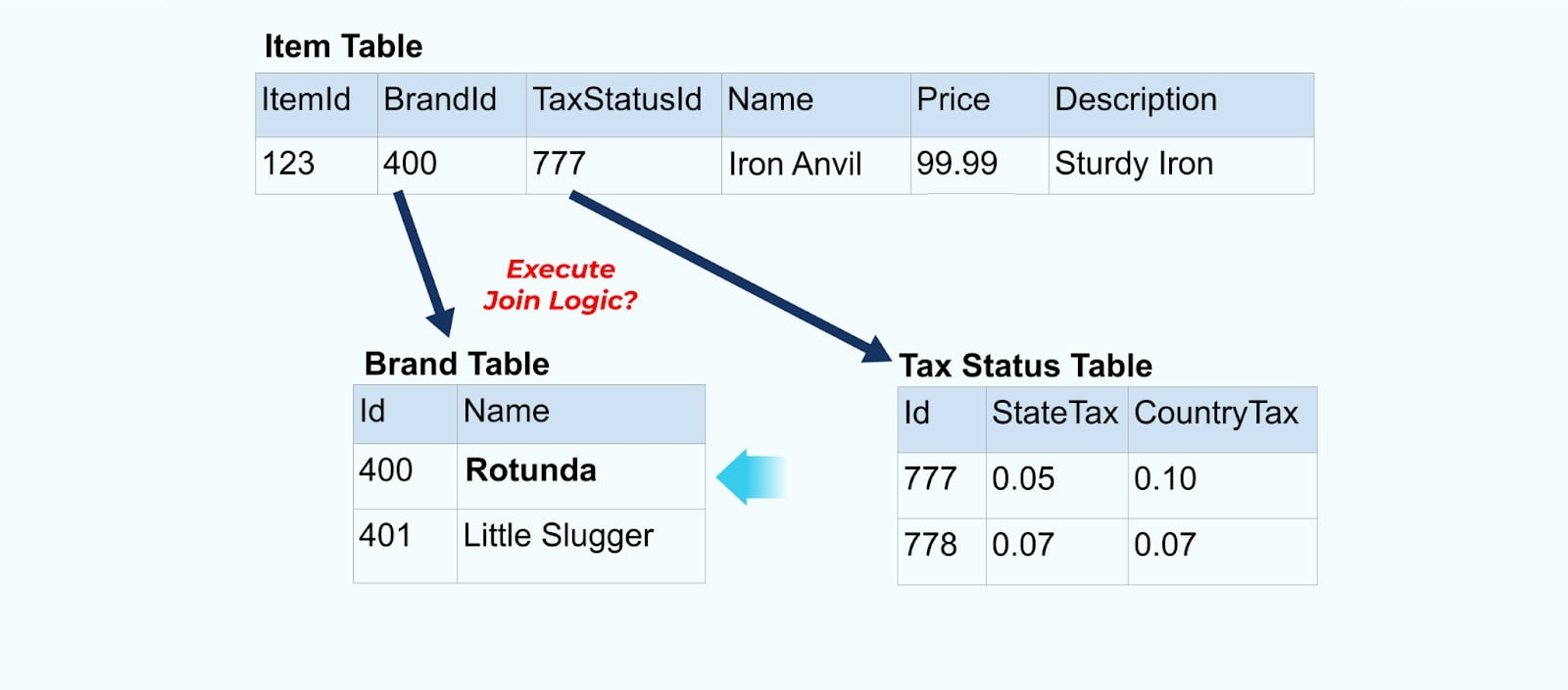
例えば、ACME会社はリブランディングを行い、新しいブランド名をRotundaに変更します。私たちはItemId=123の別のイベントを生成します。
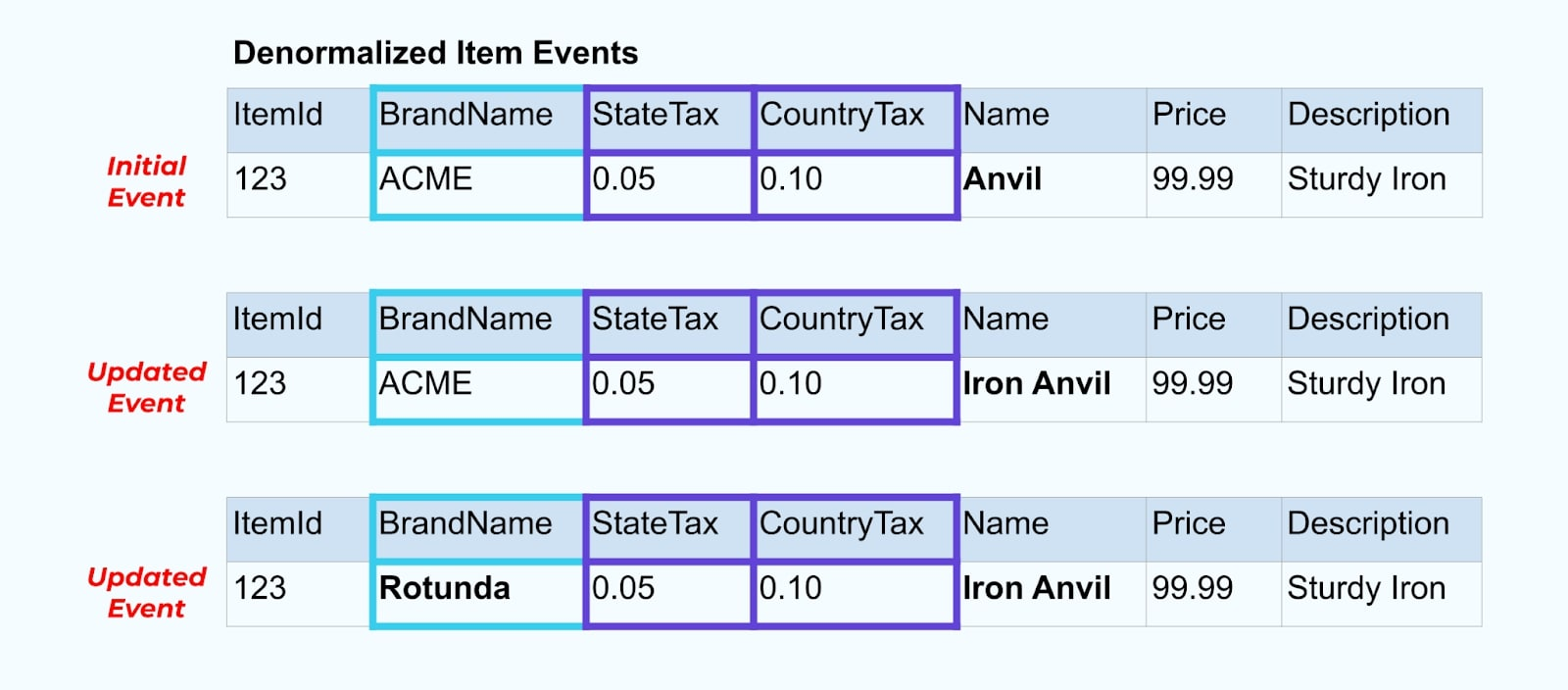
しかし、Rotunda(旧ACME)には、この変更によっても同様に更新される数百(または数千)のアイテムがおそらく存在し、それに伴って対応する数の更新されたリッチアイテムイベントが生成されます。
SCDや外部キー関係を非正規化する際には、SCDの変更がイベントストリーム全体に与える影響を念頭に置くことが重要です。SCDの変更が数百万や数十億の更新イベントを引き起こす場合、非正規化をやめて、消費者に任せることを決断するかもしれません。
概要
非正規化は消費者がデータを使用しやすくしますが、それには上流の処理が増加し、含めるデータの慎重な選択が必要です。消費者はアプリケーションの構築が容易になり、ストリーミングジョインをネイティブにサポートしていない技術も含めて、より広範囲の技術を選択できるようになります。
データが小さく、頻繁に更新されない場合、上流でのデータの正規化は効果的です。大きなイベントサイズ、頻繁な更新、SCDは、上流で何を非正規化し、消費者に任せるかを決定する際に注意すべき要因です。
最終的には、イベントに含めるデータと除外するデータを選ぶことは、消費者のニーズ、プロデューサーの能力、ユニークなデータモデル関係の間のバランスを取る行為です。しかし、最も良いスタート地点は、消費者のニーズを理解し、ソースシステムの内部データモデルを分離することです。
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2