













VAR-As-A-Service è un approccio MLOps per l’unificazione e il riuso di modelli statistici e pipeline di distribuzione di modelli di machine learning. Si tratta del secondo articolo di una serie che si basa su quel progetto, rappresentando esperimenti con vari modelli statistici e di machine learning, pipeline di dati implementate utilizzando strumenti DAG esistenti e servizi di archiviazione, sia basati su cloud che soluzioni alternative on-premises. Questo articolo si concentra sull’archiviazione dei file del modello utilizzando un approccio anche applicabile e utilizzato per i modelli di machine learning. L’archiviazione implementata si basa su MinIO come servizio di archiviazione di oggetti compatibile con AWS S3. Inoltre, l’articolo fornisce una panoramica di soluzioni di archiviazione alternative e illustra i vantaggi dell’archiviazione basata su oggetti.
Il primo articolo della serie (Time Series Analysis: VARMAX-As-A-Service) confronta modelli statistici e di machine learning come entrambi modelli matematici e fornisce un’implementazione end-to-end di un modello statistico basato su VARMAX per la previsione macroeconomica utilizzando una libreria Python chiamata statsmodels. Il modello viene distribuito come un servizio REST utilizzando Python Flask e il server web Apache, incapsulato in un contenitore docker. La struttura architetturale dell’applicazione è rappresentata nella seguente immagine:
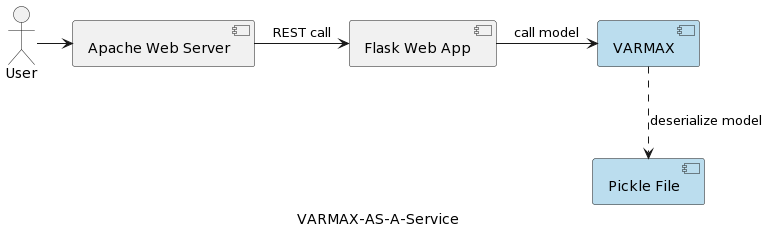
Il modello viene serializzato come file pickle e distribuito sul server web come parte del pacchetto di servizi REST. Tuttavia, nei progetti reali, i modelli sono versionati, accompagnati da informazioni sulle metadati e protetti, e gli esperimenti di addestramento devono essere registrati e mantenuti riproducibili. Inoltre, dal punto di vista architetturale, memorizzare il modello nel file system accanto all’applicazione contraddice il principio di responsabilità unica. Un buon esempio è un’architettura basata su microservizi. Scalare il servizio del modello in orizzontale significa che ogni istanza di microservizio avrà la sua propria versione del file pickle fisico replicato su tutte le istanze del servizio. Ciò significa anche che il supporto di più versioni dei modelli richiederà una nuova release e ri-distribuzione del servizio REST e della sua infrastruttura. L’obiettivo di questo articolo è separare i modelli dall’infrastruttura del servizio web e consentire la riusabilità della logica del servizio web con diverse versioni dei modelli.
Prima di immergerci nella fase di implementazione, facciamo alcune osservazioni sui modelli statistici e il modello VAR utilizzato in quel progetto. Modelli statistici sono modelli matematici, così come i modelli di machine learning. Ulteriori dettagli sulla differenza tra i due possono essere trovati nel primo articolo della serie. Un modello statistico è generalmente specificato come una relazione matematica tra una o più variabili casuali e altre variabili non casuali. Autoregressione vettoriale (VAR) è un modello statistico utilizzato per catturare la relazione tra più quantità mentre cambiano nel tempo. I modelli VAR generalizzano il modello autoregressivo univariato (AR) permettendo serie temporali multivariate. Nel progetto presentato, il modello è addestrato per fare previsioni su due variabili. I modelli VAR sono spesso utilizzati in economia e scienze naturali. In generale, il modello è rappresentato da un sistema di equazioni, che nel progetto sono nascoste dietro la libreria Python statsmodels.
L’architettura dell’applicazione del servizio modello VAR è rappresentata nella seguente immagine:
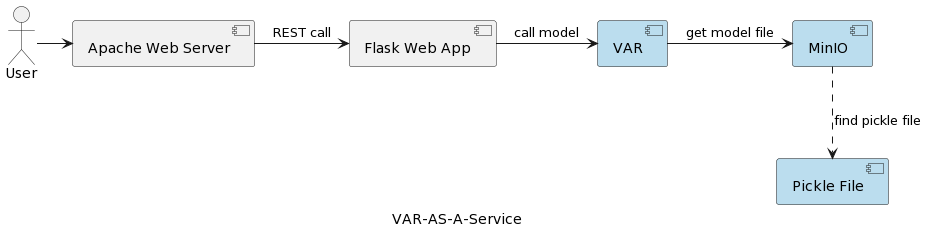
Il componente runtime VAR rappresenta l’esecuzione effettiva del modello basata sui parametri inviati dall’utente. Si connette a un servizio MinIO tramite un’interfaccia REST, carica il modello e esegue la previsione. Rispetto alla soluzione nel primo articolo, dove il modello VARMAX viene caricato e deserializzato all’avvio dell’applicazione, il modello VAR viene letto dal server MinIO ogni volta che viene attivata una previsione. Ciò comporta un costo aggiuntivo di tempo di caricamento e deserializzazione, ma anche il vantaggio di disporre della versione più recente del modello distribuito in ogni singolo run. Inoltre, consente la versionizzazione dinamica dei modelli, rendendoli automaticamente accessibili a sistemi esterni e utenti finali, come sarà mostrato più avanti nell’articolo. Si noti che a causa di quell’overhead di caricamento, le prestazioni del servizio di archiviazione selezionato sono di grande importanza.
Ma perché MinIO e l’archiviazione basata su oggetti in generale?
MinIO è una soluzione di archiviazione di oggetti ad alte prestazioni con supporto nativo per le distribuzioni Kubernetes che offre un’API compatibile con Amazon Web Services S3 e supporta tutte le funzionalità core di S3. Nel progetto presentato, MinIO è in modalità Standalone, costituito da un unico server MinIO e da un singolo disco o volume di archiviazione su Linux utilizzando Docker Compose. Per ambienti di sviluppo o produzione estesi, è disponibile l’opzione di modalità distribuita descritta nell’articolo Distribuire MinIO in Modalità Distribuita.
Diamo un rapido sguardo ad alcune alternative di archiviazione mentre una descrizione dettagliata può essere trovata qui e qui:
- Archiviazione file locale/distribuita: L’archiviazione file locale è la soluzione adottata nel primo articolo, poiché è l’opzione più semplice. La computazione e l’archiviazione sono sullo stesso sistema. È accettabile durante la fase di PoC o per modelli molto semplici che supportano una singola versione del modello. I sistemi di file locali hanno una capacità di archiviazione limitata e non sono adatti per set di dati più grandi nel caso in cui vogliamo memorizzare metadati aggiuntivi come il set di dati di allenamento utilizzato. Poiché non c’è replicazione o autoscaling, un sistema di file locale non può operare in modo disponibile, affidabile e scalabile. Ogni servizio distribuito per la scalabilità orizzontale viene distribuito con la propria copia del modello. Inoltre, l’archiviazione locale è sicura come lo è il sistema host. Le alternative all’archiviazione file locale sono NAS (Network-attached storage), SAN (Storage-area network), sistemi di file distribuiti (Hadoop Distributed File System (HDFS), Google File System (GFS), Amazon Elastic File System (EFS) e Azure Files). Rispetto al sistema di file locale, queste soluzioni sono caratterizzate dalla disponibilità, scalabilità e resilienza, ma comportano il costo dell’aumento della complessità.
- Basi di dati relazionali: A causa della serializzazione binaria dei modelli, le basi di dati relazionali offrono la possibilità di archiviare i modelli come blob o dati binari in colonne di tabelle. I programmatori e molti data scientist conoscono le basi di dati relazionali, il che rende questa soluzione semplice. Le versioni del modello possono essere memorizzate come righe separate della tabella con metadati aggiuntivi, che sono facili da leggere dal database. Uno svantaggio è che il database richiederà più spazio di archiviazione e ciò influirà sui backup. Avere grandi quantità di dati binari in un database può anche influire sulle prestazioni. Inoltre, le basi di dati relazionali impongono alcune restrizioni sulle strutture dei dati, il che potrebbe complicare la memorizzazione di dati eterogenei come file CSV, immagini e file JSON come metadati del modello.
- Archiviazione di oggetti: L’archiviazione di oggetti esiste da molto tempo, ma è stata rivoluzionata quando Amazon l’ha resa la prima servizio AWS nel 2006 con Simple Storage Service (S3). L’archiviazione di oggetti moderna è nativa nel cloud, e presto altri cloud hanno introdotto i loro servizi. Microsoft offre Azure Blob Storage, e Google ha il suo servizio Google Cloud Storage. L’API S3 è lo standard de facto per gli sviluppatori che interagiscono con l’archiviazione nel cloud, e ci sono diverse aziende che offrono archiviazione compatibile con S3 per il cloud pubblico, privato e soluzioni on-premises private. Indipendentemente da dove si trova un archivio di oggetti, viene accessibile tramite un’interfaccia RESTful. Mentre l’archiviazione di oggetti elimina la necessità di directory, cartelle e altre organizzazioni gerarchiche complesse, non è una buona soluzione per i dati dinamici che cambiano costantemente, poiché è necessario riscrivere l’intero oggetto per modificarlo, ma è una buona scelta per memorizzare modelli serializzati e i metadati del modello.
A summary of the main benefits of object storage are:
- Scalabilità massiva: La dimensione dell’archiviazione di oggetti è essenzialmente illimitata, quindi i dati possono scalare fino a exabyte semplicemente aggiungendo nuovi dispositivi. Le soluzioni di archiviazione di oggetti offrono i migliori risultati quando eseguono come cluster distribuito.
- Riduzione della complessità: I dati sono memorizzati in una struttura piatta. La mancanza di alberi complessi o partizioni (nessuna cartella o directory) riduce la complessità di recuperare file più facile poiché non è necessario conoscere la posizione esatta.
- Ricercabilità: Il metadata è parte degli oggetti, rendendo facile la ricerca e la navigazione senza bisogno di un’applicazione separata. Si può etichettare gli oggetti con attributi e informazioni, come consumo, costo e politiche per la cancellazione automatica, conservazione e stratificazione. A causa dello spazio di indirizzamento piatto dello storage sottostante (ogni oggetto in un solo bucket e nessun bucket all’interno di altri bucket), gli store di oggetti possono trovare un oggetto tra potenzialmente miliardi di oggetti rapidamente.
- Resilienza: Lo storage di oggetti può replicare automaticamente i dati e memorizzarli attraverso più dispositivi e località geografiche. Ciò può aiutare a proteggersi da interruzioni, salvaguardare contro la perdita di dati e sostenere le strategie di disaster recovery.
- Semplicità: L’uso di un’API REST per memorizzare e recuperare modelli implica quasi nessuna curva di apprendimento e rende le integrazioni in architetture basate su microservizi una scelta naturale.
È ora di esaminare l’implementazione del modello VAR come servizio e l’integrazione con MinIO. Il deployment della soluzione presentata è semplificato utilizzando Docker e Docker Compose. L’organizzazione dell’intero progetto appare come segue:

Come nel primo articolo, la preparazione del modello comprende alcuni passaggi scritti in uno script Python chiamato var_model.py situato in un repository dedicato GitHub :
- Caricamento dei dati
- Suddivisione dei dati in set di addestramento e test
- Preparazione delle variabili endogene
- Individuazione dei parametri ottimali del modello p (primi p ritardi di ciascuna variabile utilizzati come predittori di regressione)
- Creazione del modello con i parametri ottimali identificati
- Serializzazione del modello creato in un file pickle
- Archiviazione del file pickle come oggetto versionato in un bucket MinIO
Questi passaggi possono anche essere implementati come attività in un motore di workflow (ad esempio, Apache Airflow) attivato dalla necessità di addestrare una nuova versione del modello con dati più recenti. DAG e le loro applicazioni in MLOps saranno al centro di un altro articolo.
L’ultimo passaggio implementato in var_model.py è l’archiviazione del modello serializzato come file pickle in un bucket in S3. A causa della struttura piatta dell’archiviazione oggetti, il formato selezionato è:
<nome bucket>/<nome file>
Tuttavia, per i nomi dei file, è consentito utilizzare una barra rovesciata (/) per simulare una struttura gerarchica, mantenendo il vantaggio di una ricerca lineare veloce. La convenzione per memorizzare i modelli VAR è la seguente:
models/var/0_0_1/model.pkl
Dove il nome del bucket è models, e il nome del file è var/0_0_1/model.pkl e in MinIO UI, appare come segue:

Questo è un modo molto conveniente di strutturare vari tipi di modelli e versioni di modelli pur mantenendo le prestazioni e la semplicità della memorizzazione di file flat.
Si noti che la versioning del modello è implementato come parte del nome del modello. MinIO fornisce anche la versioning dei file, ma l’approccio selezionato qui presenta alcuni vantaggi:
- Supporto di versioni snapshot e sovrascrittura
- Utilizzo della versioning semantica (punti sostituiti da ‘_’ a causa delle restrizioni)
- Maggiore controllo sulla strategia di versioning
- Decoupling del meccanismo di archiviazione sottostante in termini di caratteristiche specifiche di versioning
Una volta che il modello è stato distribuito, è il momento di esporlo come un servizio REST utilizzando Flask e distribuirlo utilizzando docker-compose che esegue MinIO e un server Web Apache. L’immagine Docker, così come il codice del modello, può essere trovato in un repository GitHub dedicato.
E infine, i passaggi necessari per eseguire l’applicazione sono:
- Distribuisci l’applicazione:
docker-compose up -d - Esegui l’algoritmo di preparazione del modello:
python var_model.py(richiede un servizio MinIO attivo) - Verifica se il modello è stato distribuito: http://127.0.0.1:9101/browser
- Testa il modello:
http://127.0.0.1:80/apidocs
Dopo aver distribuito il progetto, l’API Swagger è accessibile tramite <host>:<port>/apidocs (ad esempio, 127.0.0.1:80/apidocs). C’è un endpoint per il modello VAR illustrato accanto agli altri due che espongono un modello VARMAX:
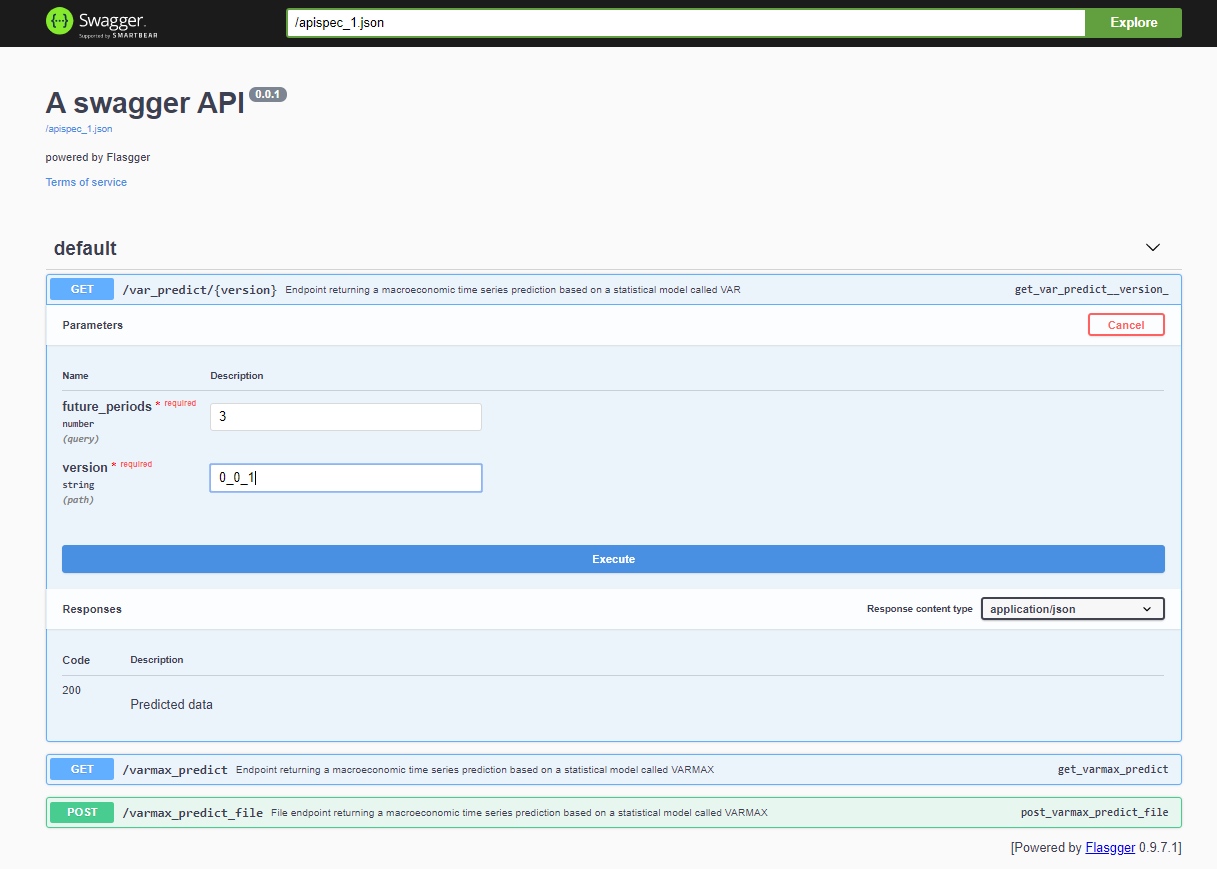
Internamente, il servizio utilizza il file pickle del modello deserializzato caricato da un servizio MinIO:
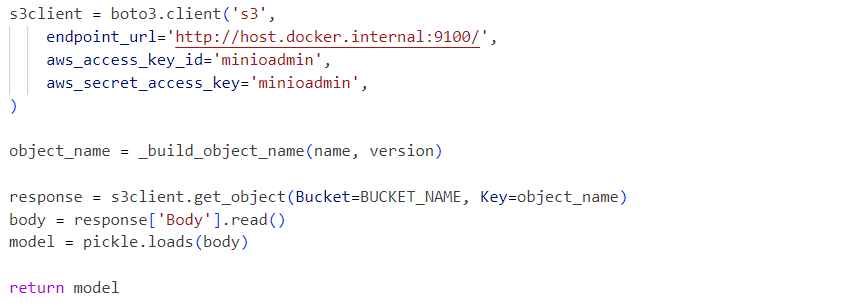
Le richieste vengono inviate al modello inizializzato come segue:

Il progetto presentato è un flusso di lavoro del modello VAR semplificato che può essere esteso passo dopo passo con funzionalità aggiuntive come:
- Esplora formati di serializzazione standard e sostituisci il pickle con una soluzione alternativa
- Integra strumenti di visualizzazione dei dati delle serie temporali come Kibana o Apache Superset
- Archivia i dati delle serie temporali in un database delle serie temporali come Prometheus, TimescaleDB, InfluxDB o uno Storage Object come S3
- Estendi il flusso di lavoro con passaggi di caricamento dei dati e pre-elaborazione dei dati
- Incorpora rapporti sui metri come parte dei flussi di lavoro
- Implementa i flussi di lavoro utilizzando strumenti specifici come Apache Airflow o AWS Step Functions o strumenti più standard come Gitlab o GitHub
- Confrontare le prestazioni e l’accuratezza dei modelli statistici con quelli di machine learning
- Implementare soluzioni integrate cloud end-to-end, inclusa l’Infrastruttura-As-Code
- Esporre altri modelli statistici e di ML come servizi
- Implementare un API di Archiviazione Modello che astragga il meccanismo di archiviazione effettivo e la versioning del modello, memorizza i metadati del modello e i dati di allenamento
Queste future migliorie saranno l’obiettivo di prossimi articoli e progetti. L’obiettivo di questo articolo è integrare un API di archiviazione compatibile con S3 e abilitare l’archiviazione di modelli versionati. Tale funzionalità verrà estratta in una libreria separata a breve. La soluzione strutturale end-to-end presentata può essere implementata in produzione e migliorata nel tempo come parte di un processo CI/CD, utilizzando anche le opzioni di distribuzione distribuita di MinIO o sostituendolo con AWS S3.
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service