













Il ripristino da disastro esterno coinvolge archiviare copie di backup dei dati in un’infrastruttura pre-preparata. Questo approccio consente di recuperare dati e ripristinare carichi di lavoro in caso di guasto al sito principale o se un disastro interessa il sito principale. Si tratta di una strategia di continuità aziendale che utilizza il backup dei dati e la replica per proteggere i dati. I dati vengono archiviati lontano dal sito primario o di produzione, ad esempio, lontano dal tuo ufficio o dal centro dati principale.
Questo post del blog spiega il ripristino da disastro esterno, la sua importanza e il principio di funzionamento. Spiegheremo anche come configurare il backup e la replica esterni per il ripristino da disastro.
Come funziona il ripristino da disastro esterno?
Archiviare backup e repliche lontano dall’ambiente principale è alla base del ripristino da disastro esterno. Con i backup, è possibile risparmiare sui requisiti di archiviazione e su altre risorse, il che è importante anche quando si trasferiscono dati tramite una rete di area vasta (WAN) o Internet in una posizione remota. Mentre la replica è più intensiva in termini di risorse ma consente di ripristinare carichi di lavoro in un tempo più breve.
I processi fondamentali del ripristino da disastro esterno sono il backup esterno, la replica esterna e l’archiviazione esterna dei dati. Esploriamoli in dettaglio.
Cos’è il backup esterno?
Il backup esterno è la copia dei dati da un sito di produzione a un sito secondario situato a distanza dal sito di produzione. I due siti sono distribuiti geograficamente per evitare la perdita di dati se un disastro colpisce il primo sito. L’approccio al backup esterno può essere implementato in modo simile per eseguire il backup dei dati da un server primario a un server esterno situato in remoto. Questa operazione può far parte di un piano di ripristino in caso di disastro .
La regola 3-2-1
Nella pianificazione del ripristino in caso di disastro e nella protezione dei dati di backup, vogliamo sempre avere più di una fonte per poter ripristinare i nostri sistemi di produzione. Lo standard raccomandato dagli esperti del settore è la regola di backup 3-2-1 . Questa regola stabilisce che idealmente dovremmo avere tre copie dei nostri dati su due diversi supporti e conservare una copia esterna di quei dati di backup.
La regola di backup 3-2-1 ci aiuta a diversificare le nostre fonti di backup in modo che non abbiamo tutte le nostre opzioni di ripristino che dipendono da una sola fonte, supporto o posizione di backup. Questo è estremamente importante da considerare quando si costruisce un piano di ripristino in caso di disastro del data center e una strategia di backup.
Ripristino da backup esterni
Il ripristino dei dati da un backup remoto può richiedere più tempo rispetto a un backup locale. Tuttavia, questo approccio aumenta significativamente l’affidabilità complessiva della strategia di protezione dei dati. Un backup può essere utilizzato per recuperare singoli file.
Tuttavia, se si utilizzano solo backup remoti per il recupero di emergenza, il tempo di recupero può essere troppo lungo per grandi quantità di dati. Il ripristino da un backup richiede tempo per estrarre e copiare i dati da un backup a un server o macchina virtuale. Per raggiungere un obiettivo di tempo di recupero (RTO) più breve è possibile utilizzare la replica dei dati remota.
Cos’è la replica remota?
La replica remota è il processo di creazione di una copia dei dati in un punto temporale specifico da utilizzare per il failover e il recupero dei carichi di lavoro in breve tempo. Quando si replica una macchina virtuale, creiamo una replica VM che è un clone della VM primaria sulla server secondario situato in remoto. La replica VM è pronta per essere accesa e ripristinare i carichi di lavoro in caso di guasto della VM primaria.
Il vantaggio dell’uso della replica remota è il breve tempo necessario per ripristinare i carichi di lavoro con i dati rispetto al ripristino dei dati da un backup. Una replica contiene dati non compressi pronti all’uso.
Cos’è la memorizzazione dei dati remota?
La memorizzazione dei dati remota è lo storage situato lontano dal server primario (di produzione), dal data center o dal sito con l’obiettivo di creare copie di dati distribuite e ridondanti per scopi di backup e recupero.

Puoi avere un server di backup esterno o una storage alternativa che può memorizzare backup dei dati e repliche e dovrebbe essere accessibile se un disastro colpisce i dati nel sito principale. Ci sono tre tipi principali di storage di destinazione:
- A local server in a remote office or data center
- Invio dei dati di backup e delle repliche al cloud
- Registrazione dei dati di backup su dischi rigidi o nastro e trasporto di questi supporti di memorizzazione in una posizione remota
Puoi costruire un sito secondario lontano dal tuo centro di produzione primario. Ci sono tre tipi di siti di ripristino da disastro:
- Sito caldo. L’infrastruttura è pronta per il ripristino dei dati e il failover del carico di lavoro in poco tempo. Sono richieste operazioni minime di configurazione durante un disastro poiché tutto è fatto in anticipo.
- Sito tiepido. Ci sono alcuni hardware pre-installati. Tuttavia, sono comunque necessarie alcune azioni per configurare l’infrastruttura prima di ripristinare i dati dai backup ed eseguire carichi di lavoro critici.
- Sito freddo. Il livello di preparazione dell’infrastruttura è basso. Solo gli elementi principali dell’infrastruttura sono pronti. Potresti dover acquistare hardware aggiuntivo con altri equipaggiamenti e configurare server prima di poter ripristinare i dati dalla memorizzazione dei backup esterni ed eseguire i carichi di lavoro.
Motivi per implementare il ripristino dei disastri esterni
Considerando gli scenari comuni di ripristino da disastri, viene in mente la perdita di un ambiente in una posizione a causa di un guasto hardware o forse di una perdita di dati non intenzionale. Anche se la perdita di un sito a causa di un disastro naturale o di un attacco ransomware su larga scala può sembrare improbabile, non essere preparati per questi tipi di scenari di disastro può spingere un’azienda al fallimento a causa delle ripercussioni finanziarie e sulla reputazione del marchio. Le aziende oggi devono prepararsi per qualsiasi scenario di ripristino da disastro, compresa la perdita di un’intera posizione fisica.
Se il ransomware corrompe la copia principale dei dati sui server di produzione, anche i backup locali possono essere interessati. Avere backup in una posizione isolata, non accessibile dalla rete di produzione, consente di riprendersi più velocemente da un attacco ransomware e senza negoziare con gli hacker.
Archiviare repliche e backup fuori sede può aiutare in caso di disastri naturali come incendi, tifoni, terremoti, tornado o uragani che distruggono i server di produzione nel sito principale. È possibile ripristinare i dati dal backup esterno o avviare la replica in un’altra posizione. Naturalmente, in questo caso, il sito secondario dovrebbe essere situato abbastanza lontano da non essere influenzato dagli stessi eventi naturali del sito principale.
I benefici del ripristino da disastro esterno sono:
- Protezione aggiuntiva dai disastri naturali
- Migliorata sicurezza dei backup, proteggendo i dati da malware
- Abilità di ripristinare dati e carichi di lavoro
- Probabilità inferiore di perdita irreversibile di dati
- Migliorata continuità operativa
Come configurare il backup e la replica esterni per il ripristino in caso di disastro
Quando si crea una strategia di ripristino esterno in caso di disastro, è necessario selezionare una soluzione di protezione dei dati per aiutare a implementarla. Questa soluzione dovrebbe supportare il backup, la copia di backup, la replica dei dati e il failover. L’automazione delle attività e l’attacco/detach del supporto di destinazione del backup sono le funzionalità consigliate.
Con NAKIVO Backup & Replication, possiamo creare backup di VM, copia di backup e replica che ci consentono di creare una copia secondaria dei nostri dati. Possiamo conservare una copia dei nostri backup in più posizioni, inclusi supporti di archiviazione removibili, nastri e il cloud.

Esploriamo come configurare il backup e la replica esterni utilizzando un esempio di un ambiente VMware vSphere e la soluzione NAKIVO.
Configurazione di un lavoro di copia di backup per il backup esterno
Con NAKIVO Backup & Replication puoi utilizzare la funzione Backup Copy per creare una copia da un backup memorizzato in un repository locale e inviarlo fuori sede. La tua copia di backup può, ovviamente, essere memorizzata localmente su un altro server di backup nello stesso sito. Tuttavia, per ottenere il massimo beneficio di una copia di backup, idealmente, vorremmo che questa copia risieda in un’altra posizione connessa tramite rete, sia LAN o tecnologie WAN-based. In questo modo, abbiamo una copia dei nostri dati di backup che è fuori sede, il che soddisfa l’ultimo dei 3 principi della regola 3-2-1.
Diamo un’occhiata a come creare un job di copia di backup nella soluzione NAKIVO per il backup dei dati fuori sede.
Dobbiamo aprire l’interfaccia web e fare clic su Crea > Job di copia di backup.
Viene aperto il Wizard Nuovo Job di Copia di Backup.
- Per prima cosa, seleziona il backup VM per il quale desideriamo impostare un job di copia di backup.
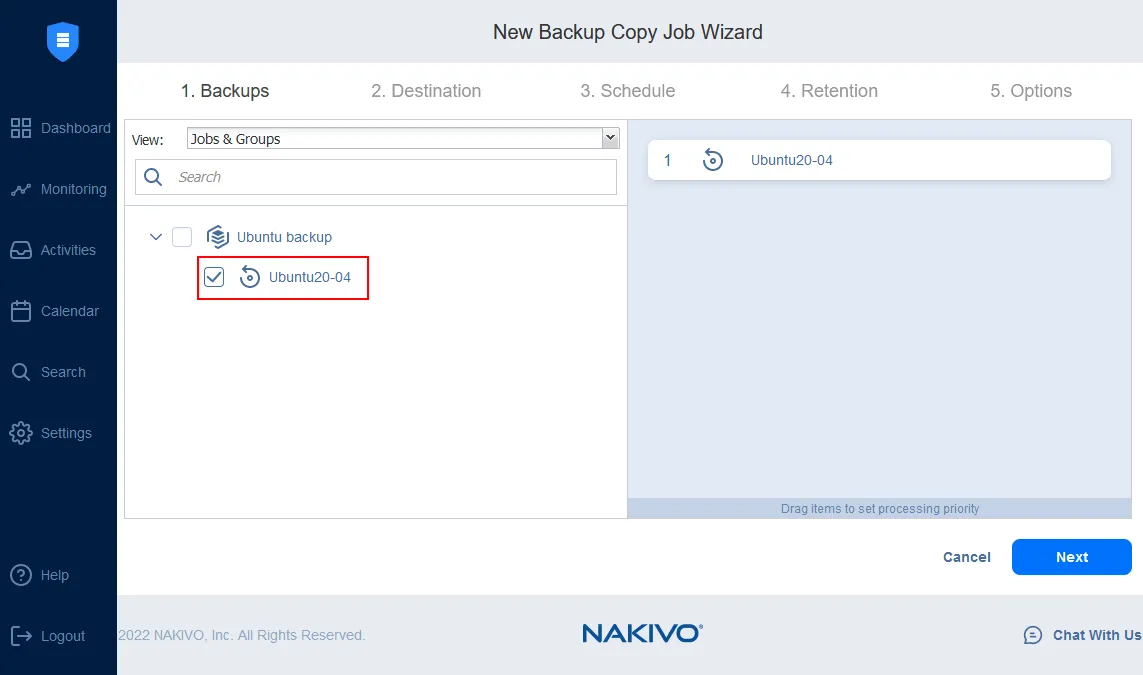
- Ecco un dettaglio importante della configurazione del processo di backup quando prendiamo in considerazione la creazione di una posizione di backup remoto per una VM: dove si trova i dati? Di seguito è possibile scegliere il DR Repo, che è un repository di backup remoto nell’ambiente sottostante.
Le destinazioni alternative per i backup remoti possono essere cloud pubblici come Amazon S3 o Wasabi. I repository cloud offrono la possibilità di abilitare l’immutabilità per proteggere i dati di backup contro la corruzione e la cancellazione da parte di ransomware.

-
- Possiamo selezionare il periodo di conservazione per la copia di backup. Come puoi vedere di seguito, il valore predefinito è mantenere lo stesso numero di punti come per il backup sorgente. Quando selezioni questa opzione, la politica di conservazione del backup sorgente viene applicata.
Nota che se scegli un repository cloud o un repository locale basato su Linux in NAKIVO Backup & Replication, puoi anche abilitare l’immutabilità per assicurarti che i punti di ripristino siano protetti contro nuove infezioni di ransomware.
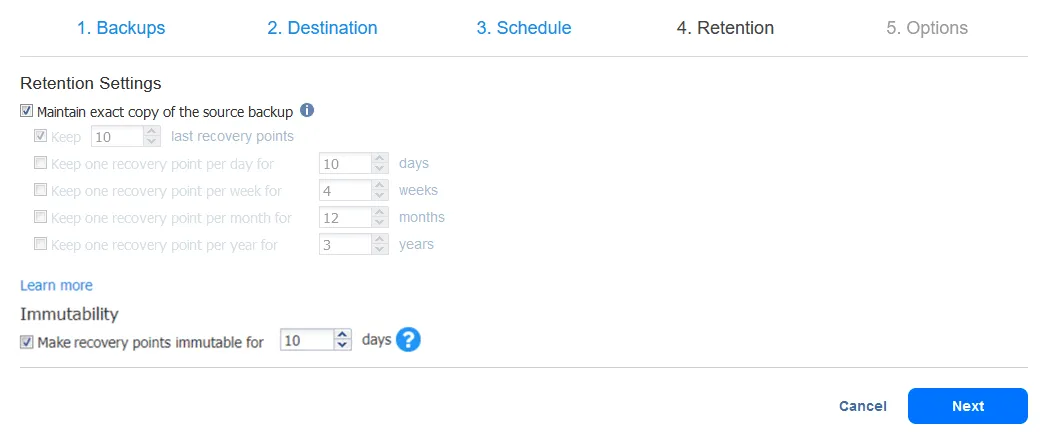
- Infine, possiamo abilitare altre opzioni come Acceleramento di rete e Crittografia, che aiutano sia nelle prestazioni che nella sicurezza dei dati copiati nel repository di backup offsite.

Configurazione della replica dei dati offsite
La replica consente di creare una replica VM di riserva per la macchina virtuale in esecuzione in produzione. Questa replica VM di riserva può essere presente sul posto, ma idealmente è memorizzata fuori sede per avere resilienza in caso di fallimento del sito. Se perdiamo un intero sito, possiamo avviare il failover sulla replica VM di riserva che è già attrezzata nell’impianto di disaster recovery (DR) fuori sede. Diamo un’occhiata a quanto è facile impostare un lavoro di replica in NAKIVO Backup & Replication.
Apri il dashboard, quindi fai clic su Crea > Lavoro di replica VMware vSphere.

Si apre il Nuovo Wizard per il lavoro di replica per VMware vSphere.
- Innanzitutto, seleziona la VM che desideri replicare.
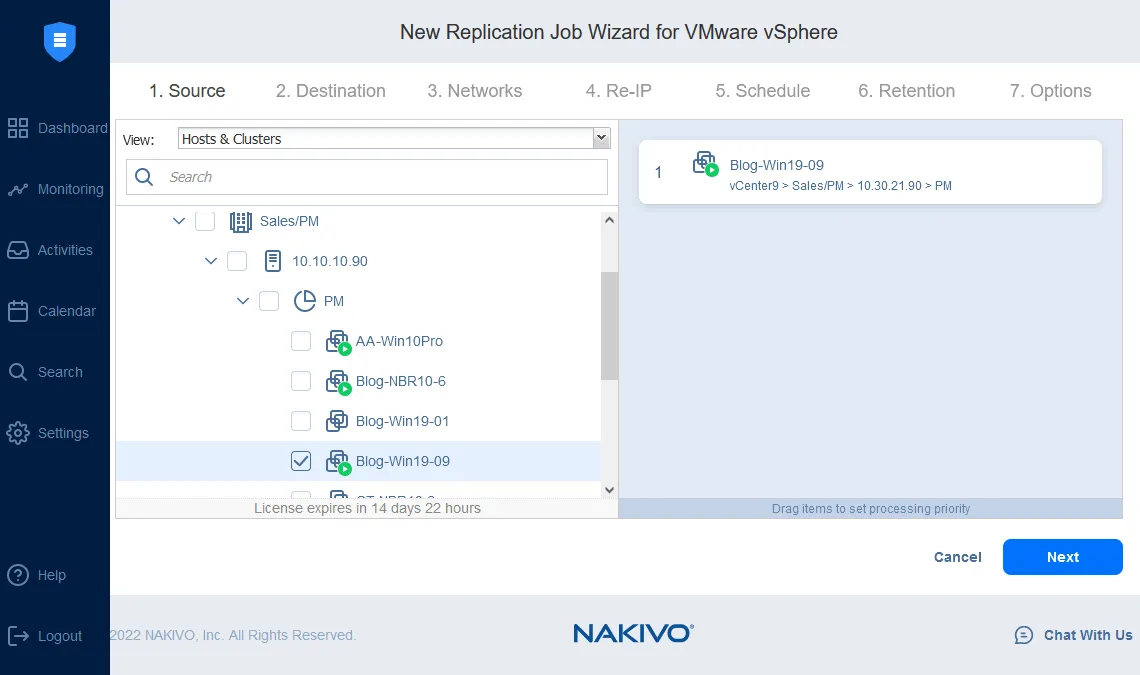
- Per quanto riguarda il Destinazione, ancora una volta, la chiave per le copie di backup fuori sede e la resilienza è assicurarsi che l’ambiente VMware e il datastore di destinazione si trovino su un sito separato.

- Abilita il mapping di rete per mappare le reti virtuali della VM sorgente alle reti virtuali di destinazione appropriate.

- Dopo aver configurato il mapping di rete, è possibile abilitare Re-IP per mappare gli indirizzi IP specifici di destinazione durante il recupero.
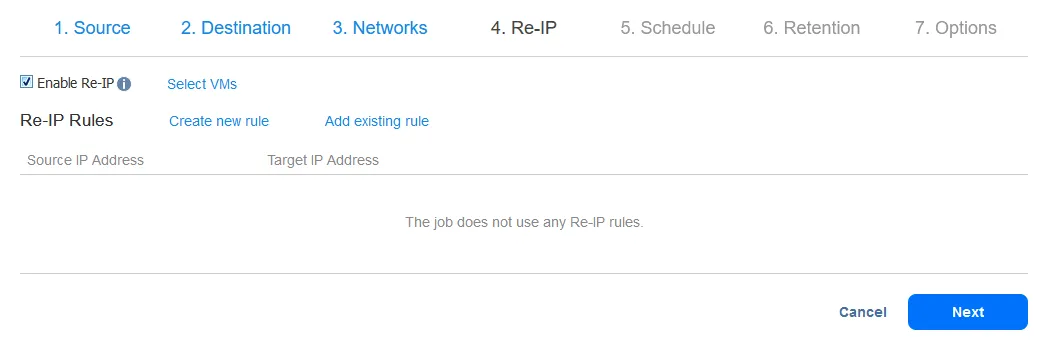
- Possiamo pianificare che la replica VM venga creata/aggiornata dopo l’esecuzione di un altro lavoro, come il lavoro di backup principale. Una agenda ci aiuta a vedere quando sono pianificate altre attività per evitare sovrapposizioni.

- Con la conservazione su una replica VM, questa viene realizzata tramite uno snapshot a punto di tempo ogni volta che viene eseguito il processo di replica. È possibile specificare il numero di snapshot/punti di conservazione che si desidera mantenere. Il prodotto NAKIVO supporta il schema di conservazione GFS.
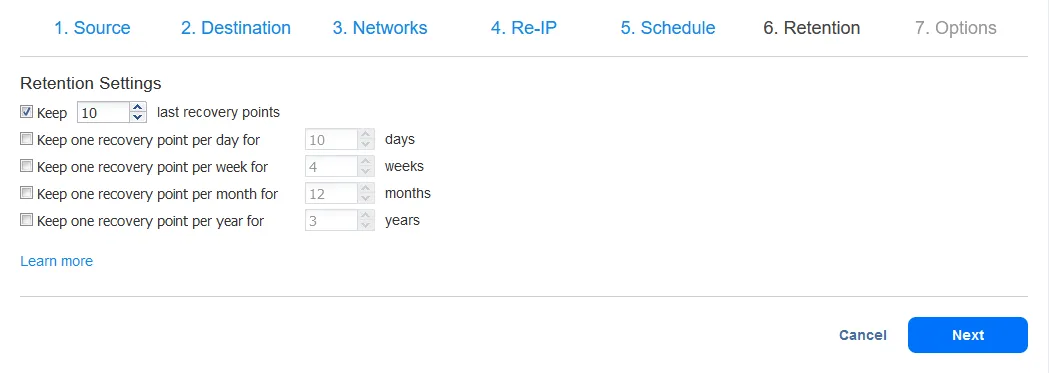
- Finalmente, puoi scegliere un numero di opzioni per controllare le prestazioni e la sicurezza del lavoro di replica, come l’accelerazione di rete e la crittografia in volo. Qui, dai anche un nome alla VM replica risultante, imposti le opzioni di posta elettronica ed esegui eventuali script pre- e post-lavoro.

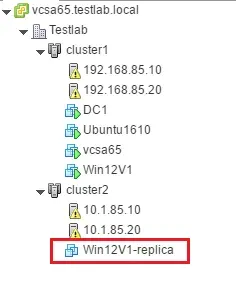
Ora sai come configurare un lavoro di replica VMware per il ripristino di emergenza in un sito remoto. La replica VM viene creata in un ambiente VMware vSphere remoto. Nella schermata qui sotto, possiamo vedere un esempio di cluster locale nel sito di produzione e un cluster remoto che si trova in una struttura DR.
Suggerimento professionale. La soluzione NAKIVO include anche una funzionalità Site Recovery per automatizzare i flussi di lavoro con backup di dati, replica e test di failover per scenari di ripristino di emergenza.
Pensieri
Un backup offsite e una replica offsite sono parti importanti di una strategia di ripristino di emergenza che aumentano significativamente la probabilità di recuperare i dati. Questo approccio si adatta alla regola di backup 3-2-1 per evitare un punto di fallimento e evitare la perdita di dati a causa dell’influenza di un backup on-site. I backup offsite ci aiutano a proteggerci da un fallimento a livello di sito che determina perdite di dati di produzione ma anche potenzialmente perdita di dati del sistema di backup.
Source:
https://www.nakivo.com/blog/offsite-disaster-recovery/