













Apache Iceberg è diventato una scelta popolare per gestire grandi set di dati con flessibilità e scalabilità. I cataloghi sono centrali per la funzionalità di Iceberg, che è fondamentale nell’organizzazione delle tabelle, nella coerenza e nella gestione dei metadati. Questo articolo esplorerà cosa sono i cataloghi di Iceberg, le loro varie implementazioni, casi d’uso e configurazioni, fornendo una comprensione delle soluzioni di catalogo più adatte per differenti casi d’uso.
Cosa è un Catalogo Iceberg?
In Iceberg, un catalogo è responsabile della gestione dei percorsi delle tabelle, puntando ai file dei metadati attuali che rappresentano lo stato di una tabella. Questa architettura è essenziale perché consente atomicità, coerenza ed interrogazioni efficienti garantendo che tutti i lettori e scrittori accedano allo stesso stato della tabella. Diverse implementazioni di cataloghi memorizzano questi metadati in modi diversi, dai sistemi di file ai servizi di metastore specializzati.
Responsabilità principali di un Catalogo Iceberg
Le responsabilità fondamentali di un catalogo Iceberg sono:
- Mappatura dei Percorsi delle Tabelle: Collegare un percorso della tabella (ad esempio, “db.tabella”) al relativo file di metadati.
- Supporto a Operazioni Atomiche: Garantire lo stato coerente della tabella durante letture e scritture concorrenti.
- Gestione dei Metadati: Memorizzare e gestire i metadati, garantendo accessibilità e coerenza.
I cataloghi Iceberg offrono varie implementazioni per soddisfare diverse architetture di sistema e requisiti di archiviazione. Esaminiamo queste implementazioni e la loro idoneità per diversi ambienti.
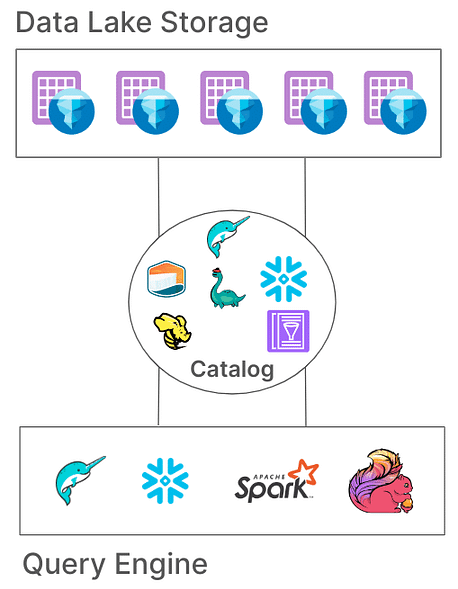
Tipi di Cataloghi Iceberg
1. Catalogo Hadoop
Il Catalogo Hadoop è generalmente il più facile da configurare, richiedendo solo un file system. Questo catalogo gestisce i metadati cercando il file di metadati più recente nella directory di una tabella in base ai timestamp dei file. Tuttavia, a causa della sua dipendenza dalle operazioni atomiche a livello di file (che alcuni sistemi di archiviazione come S3 non hanno), il catalogo Hadoop potrebbe non essere adatto per ambienti di produzione dove le scritture concorrenti sono comuni.
Esempio di configurazione
Per configurare il catalogo Hadoop con Apache Spark:
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:0.14.0 \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.type=hadoop \
--conf spark.sql.catalog.my_catalog.warehouse=file:///D:/sparksetup/iceberg/spark_warehouse
Un modo diverso per impostare il catalogo nel lavoro di spark stesso:
SparkConf sparkConf = new SparkConf()
.setAppName("Example Spark App")
.setMaster("local[*]")
.set("spark.sql.extensions","org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.set("spark.sql.catalog.local","org.apache.iceberg.spark.SparkCatalog")
.set("spark.sql.catalog.local.type","hadoop")
.set("spark.sql.catalog.local.warehouse", "file:///D:/sparksetup/iceberg/spark_warehouse")
Nell’esempio sopra, impostiamo il nome del catalogo su “local” come configurato in spark “spark.sql.catalog.local“. Questa può essere una scelta del tuo nome.
Pro:
- Configurazione semplice, nessun metastore esterno richiesto.
- Ideale per ambienti di sviluppo e test.
Contro:
- Limitato a singoli file system (ad es., un singolo bucket S3).
- Non raccomandato per la produzione
2. Catalogo Hive
Il Catalogo Hive sfrutta il Metastore di Hive per gestire la posizione dei metadati, rendendolo compatibile con numerosi strumenti per big data. Questo catalogo è ampiamente utilizzato in produzione grazie alla sua integrazione con l’infrastruttura esistente basata su Hive e alla compatibilità con più motori di interrogazione.
Esempio di configurazione
Per utilizzare il catalogo Hive in Spark:
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:0.14.0 \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.type=hive \
--conf spark.sql.catalog.my_catalog.uri=thrift://<metastore-host>:<port>
Vantaggi:
- Alta compatibilità con gli strumenti esistenti per big data.
- Indipendente dal cloud e flessibile su configurazioni on-premises e cloud.
Svantaggi:
- Necessita di mantenere un Metastore di Hive, che potrebbe aumentare la complessità operativa.
- Mancanza di supporto per transazioni multi-tabella, limitando l’atomicità per le operazioni tra tabelle
3. Catalogo AWS Glue
Il Catalogo AWS Glue è un catalogo di metadati gestito fornito da AWS, ideale per organizzazioni fortemente impegnate nell’ecosistema AWS. Gestisce i metadati delle tabelle Iceberg come proprietà delle tabelle all’interno di AWS Glue, consentendo un’integrazione senza soluzione di continuità con altri servizi AWS.
Esempio di configurazione
Per configurare AWS Glue con Iceberg in Spark:
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-x.x_x.xx:x.x.x,software.amazon.awssdk:bundle:x.xx.xxx \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog \
--conf spark.sql.catalog.my_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO \
--conf spark.hadoop.fs.s3a.access.key=$AWS_ACCESS_KEY \
--conf spark.hadoop.fs.s3a.secret.key=$AWS_SECRET_ACCESS_KEY
Vantaggi:
- Servizio gestito, riducendo i costi infrastrutturali e di manutenzione.
- Forte integrazione con i servizi AWS.
Svantaggi:
- Specifico per AWS, limitando la flessibilità tra cloud diversi.
- Assenza di supporto per transazioni multi-tabella
4. Catalogo Project Nessie
Il progetto Nessie offre un approccio “dati come codice”, consentendo il controllo della versione dei dati. Con le sue capacità di branching e tagging simili a Git, Nessie consente agli utenti di gestire i branch dei dati in modo simile al codice sorgente. Fornisce un framework robusto per transazioni multi-tabella e multi-istruzione.
Esempio di configurazione
Per configurare Nessie come catalogo:
spark-sql --packages "org.apache.iceberg:iceberg-spark-runtime-x.x_x.xx:x.x.x" \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.catalog-impl=org.apache.iceberg.nessie.NessieCatalog \
--conf spark.sql.catalog.my_catalog.uri=http://<host>:<port>
Vantaggi:
- Fornisce funzionalità “dati come codice” con controllo della versione.
- Supporta transazioni multi-tabella.
Svantaggi:
- Richiede l’auto-hosting, aggiungendo complessità all’infrastruttura.
- Supporto limitato degli strumenti rispetto a Hive o AWS Glue
5. Catalogo JDBC
Il Catalogo JDBC consente di archiviare metadati in qualsiasi database compatibile con JDBC, come PostgreSQL o MySQL. Questo catalogo è agnostico rispetto al cloud e garantisce alta disponibilità utilizzando sistemi RDBMS affidabili.
Esempio di configurazione
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-x.x_x.xx:x.x.x \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.catalog-impl=org.apache.iceberg.jdbc.JdbcCatalog \
--conf spark.sql.catalog.my_catalog.uri=jdbc:<protocol>://<host>:<port>/<database> \
--conf spark.sql.catalog.my_catalog.jdbc.user=<username> \
--conf spark.sql.catalog.my_catalog.jdbc.password=<password>
Vantaggi:
- Facile da configurare con un’infrastruttura RDBMS esistente.
- Alta disponibilità e agnostico rispetto al cloud.
Svantaggi:
- Nessun supporto per transazioni multi-tabella.
- Aumenta le dipendenze dai driver JDBC per tutti gli strumenti di accesso
6. Catalogo Snowflake
Snowflake offre un robusto supporto per le tabelle Apache Iceberg, consentendo agli utenti di sfruttare la piattaforma di Snowflake come catalogo Iceberg. Questa integrazione combina le prestazioni e la semantica delle query di Snowflake con la flessibilità del formato di tabella aperta di Iceberg, abilitando una gestione efficiente di grandi dataset memorizzati in storage cloud esterni. Consulta la documentazione di Snowflake per ulteriori configurazioni link
Pro:
- Integrazione senza soluzione di continuità: Combina le prestazioni e le capacità di query di Snowflake con il formato di tabella aperto di Iceberg, facilitando la gestione efficiente dei dati.
- Supporto completo della piattaforma: Fornisce accesso completo in lettura e scrittura, insieme a funzionalità come transazioni ACID, evoluzione dello schema e viaggi nel tempo.
- Manutenzione semplificata: Snowflake gestisce compiti di ciclo di vita come la compattazione e la riduzione dei costi operativi.
Contro:
- Vincoli di Cloud e Regione: Il volume esterno deve trovarsi nello stesso fornitore cloud e nella stessa regione dell’account Snowflake, limitando le configurazioni cross-cloud o cross-regione.
- Limitazione del formato dei dati: Supporta solo il formato di file Apache Parquet, che potrebbe non allinearsi con tutte le preferenze di formato dati dell’organizzazione.
- Restrizioni per i client di terze parti: Impedisce ai client di terze parti di modificare i dati nelle tabelle Iceberg gestite da Snowflake, potenzialmente influenzando i flussi di lavoro che si basano su strumenti esterni.
7. Cataloghi basati su REST
Iceberg supporta cataloghi basati su REST per affrontare diverse sfide associate alle implementazioni di cataloghi tradizionali.
Sfide con i Cataloghi Tradizionali
- Complessità lato client: I cataloghi tradizionali spesso richiedono configurazioni e dipendenze lato client per ciascun linguaggio (Java, Python, Rust, Go), portando a inconsistenze tra diversi linguaggi di programmazione e motori di esecuzione. Leggi di più a riguardo qui.
- Limiti di scalabilità: Gestire metadati e operazioni sulle tabelle a livello client può introdurre dei colli di bottiglia, influenzando le prestazioni e la scalabilità in ambienti di dati su larga scala.
Vantaggi dell’Adozione del Catalogo REST
- Integrazione semplificata del client: I client possono interagire con il catalogo REST utilizzando protocolli HTTP standard, eliminando la necessità di configurazioni complesse o dipendenze.
- Scalabilità: L’architettura lato server del catalogo REST consente una gestione scalabile dei metadati, adattandosi a set di dati in crescita e a modelli di accesso concorrenti.
- Flessibilità: Le organizzazioni possono implementare logiche di catalogo personalizzate sul lato server, adattando il catalogo REST per soddisfare requisiti specifici senza modificare le applicazioni client.
Sono emerse diverse implementazioni del catalogo REST, ognuna dedicata a specifiche esigenze organizzative:
- Gravitino: Un servizio di catalogo REST Iceberg open-source che facilita l’integrazione con Spark e altri motori di elaborazione, offrendo una configurazione semplice per la gestione delle tabelle Iceberg.
- Tabular: Un servizio gestito che fornisce un’interfaccia di catalogo REST, consentendo alle organizzazioni di sfruttare le capacità di Iceberg senza il costo di gestire l’infrastruttura del catalogo. Per ulteriori informazioni, consultare Tabular.
- Apache Polaris: Un catalogo completo open-source per Apache Iceberg, che implementa l’API REST per garantire un’interoperabilità multi-motore senza problemi su piattaforme come Apache Doris, Apache Flink, Apache Spark, StarRocks e Trino. Per ulteriori informazioni, consultare GitHub.
Uno dei modi semplici e preferiti per provare il catalogo REST con le tabelle Iceberg è utilizzare un’implementazione Java REST standard. Si prega di verificare il link GitHub qui.
Conclusione
La selezione del catalogo Apache Iceberg appropriato è cruciale per ottimizzare la strategia di gestione dei dati. Ecco una panoramica concisa per guidare la tua decisione:
- Catalogo Hadoop: Più adatto per ambienti di sviluppo e test a causa della sua semplicità. Tuttavia, potrebbero verificarsi problemi di coerenza in scenari di produzione con scritture concorrenti.
- Catalogo Hive Metastore: Ideale per le organizzazioni con infrastrutture Hive esistenti. Offre compatibilità con una vasta gamma di strumenti per big data e supporta operazioni complesse sui dati. Tuttavia, mantenere un servizio Hive Metastore può aggiungere complessità operativa.
- Catalogo AWS Glue: Ottimale per coloro che sono fortemente coinvolti nell’ecosistema AWS. Fornisce un’integrazione senza soluzione di continuità con i servizi AWS e riduce la necessità di servizi di metadati auto-gestiti. Tuttavia, è specifico di AWS, il che potrebbe limitare la flessibilità multi-cloud.
- Catalogo JDBC: Adatto per ambienti che preferiscono i database relazionali per lo storage dei metadati, consentendo l’uso di qualsiasi database compatibile con JDBC. Questo offre flessibilità e sfrutta l’infrastruttura RDBMS esistente ma potrebbe introdurre dipendenze aggiuntive e richiedere una gestione attenta delle connessioni al database.
- Catalogo REST: Ideale per scenari che richiedono un’API standardizzata per le operazioni di catalogo, migliorando l’interoperabilità tra diversi motori di elaborazione e linguaggi. Decoppia i dettagli di implementazione del catalogo dai client ma richiede la configurazione di un servizio REST per gestire le operazioni di catalogo, il che potrebbe aggiungere complessità iniziale alla configurazione.
- Progetto Catalogo Nessie: Questo è perfetto per le organizzazioni che necessitano di controllo di versione sui loro dati, simile a Git. Supporta il branching, il tagging e le transazioni multi-tabella. Fornisce robuste capacità di gestione dei dati ma richiede il dispiegamento e la gestione del servizio Nessie, il che potrebbe aggiungere un sovraccarico operativo.
Comprendere queste opzioni di catalogo e le loro configurazioni ti permetterà di fare scelte informate e ottimizzare la configurazione del tuo data lake o lakehouse per soddisfare le esigenze specifiche della tua organizzazione.
Source:
https://dzone.com/articles/iceberg-catalogs-a-guide-for-data-engineers