













Whisper AI היא מודל מתקדם לזיהוי אוטומטי של דיבור (ASR) שפותח על ידי OpenAI ויכול להמיר שמע לטקסט בדיוק מרשים ולתמוך במגוון שפות. בעוד Whisper AI מיועד בעיקר לעיבוד בצורה סדורה, ניתן להגדיר אותו לטקסט חי בזמן אמת על מערכת Linux.
במדריך זה נדבור על תהליך התקנה, הגדרה והפעלה של Whisper AI לטקסט חי על מערכת Linux.
מהו Whisper AI?
Whisper AI הוא מודל לזיהוי קול פתוח המאומן על מאגר נרחב של הקלטות שמע ומבוסס על ארכיטקטורת למידת עמוק שמאפשרת לו:
- להעתיק דיבור במגוון שפות.
- להתמודד עם מבטאים ורעש רקע ביעילות.
- לבצע תרגום של שפה מדוברת לאנגלית.
בשל יכולתו לבצע העתקה ברמה גבוהה של דיוק, הוא משמש במידה רחבה בתחומים הבאים:
- שירותי העתקה בזמן אמת (לדוגמה, לצורך נגישות).
- עזרים קוליים ואוטומציה.
- העתקת קבצי שמע מוקלטים.
כברירת מחדל, Whisper AI אינו מותאם לעיבוד בזמן אמת. אך בעזרת כלים נוספים ניתן לעבד זרמי שמע חיים להעתקה מיידית.
דרישות מערכת ל-Whisper AI
לפני הרצת Whisper AI על Linux, וודא שהמערכת שלך עומדת בדרישות הבאות:
דרישות חומרה:
- CPU: מעבד מרובה ליבות (Intel/AMD).
- RAM: לפחות 8GB (נמלצים 16GB או יותר).
- GPU: כרטיס מסך NVIDIA עם CUDA (אופציונלי אך מאיץ את העיבוד באופן משמעותי).
- אחסון: מינימום 10GB של שטח פנוי בדיסק קשיח עבור מודלים ותלות.
דרישות תוכנה:
- הפצת Linux כגון Ubuntu, Debian, Arch, Fedora, וכו'
- Python גרסה 3.8 או מאוחר יותר.
- מנהל החבילות Pip להתקנת חבילות Python.
- FFmpeg לטיפול בקבצי וזרמי שמע.
שלב 1: התקנת תלות נדרשות
לפני התקנת Whisper AI, עדכן את רשימת החבילות ושדרג את החבילות הקיימות.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
לאחר מכן, עליך להתקין את Python 3.8 או גרסה גבוהה יותר ואת Pip מנהל החבילות כפי שמוצג.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
לבסוף, עליך להתקין את FFmpeg, שהוא מסגרת מולטימדיה המשמשת לעיבוד קבצי שמע ווידאו.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
שלב 2: התקנת Whisper AI ב-Linux
כאשר התלויות הנדרשות מותקנות, ניתן להמשיך ולהתקין Whisper AI בסביבה וירטואלית שמאפשרת לך להתקין חבילות Python מבלי להשפיע על חבילות המערכת.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
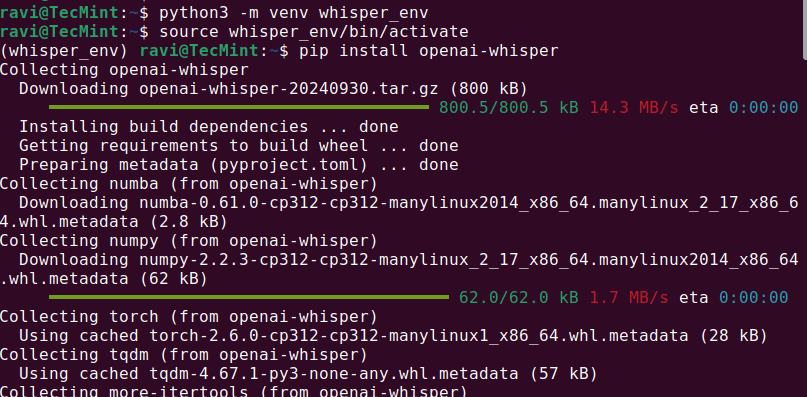
לאחר התקנת התוכנה, יש לוודא שהתקנת Whisper AI הושלמה כראוי על ידי הרצת.
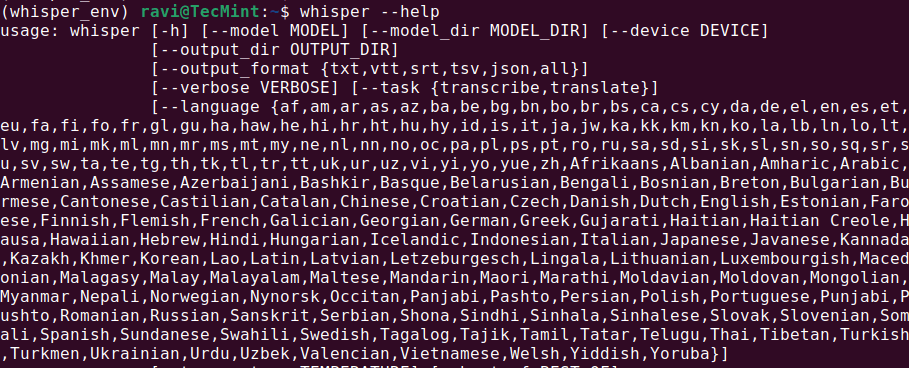
whisper --help
כך יוצג תפריט עזר עם פקודות זמינות ואפשרויות, שמעיד על התקנת Whisper AI והכנות לשימוש.
שלב 3: הרצת Whisper AI ב-Linux
לאחר התקנת Whisper AI, ניתן להתחיל להמיר קבצי קול באמצעות פקודות שונות.
המרת קובץ שמע
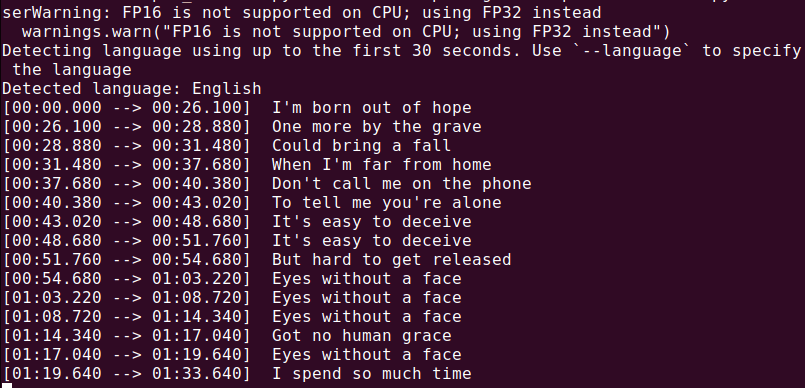
כדי להמיר קובץ שמע (audio.mp3), יש להריץ את הפקודה הבאה:
whisper audio.mp3
Whisper תעבד את הקובץ ותייצר טקסט עם התמלול.
עכשיו שכל התהליכים הושלמו, בואו ניצור סקריפט Python ללכוד קול מהמיקרופון שלך ולהמיר אותו בזמן אמת.
nano real_time_transcription.py
יש להעתיק ולהדביק את הקוד הבא לקובץ.
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
יש להריץ את הסקריפט באמצעות Python, שיתחיל להאזין לקלט מיקרופון ולהציג את הטקסט המתומלל בזמן אמת. יש לדבר באופן ברור למיקרופון שלך, ואז תראה את התוצאות מודפסות בטרמינל.
python3 real_time_transcription.py
מסקנה
Whisper AI היא כלי עוצמתי להמרת דיבור לטקסט שניתן להתאים לתמלול בזמן אמת ב-Linux. לתוצאות מיטביות, כדאי להשתמש ב-GPU ולייעל את המערכת שלך לעיבוד בזמן אמת.
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/