













By Okure U. Edet
Go est une langue de programmation rapide avec une syntaxe relativement simple. En apprenant Go, il est important d’apprendre comment construire des API et comment les utiliser pour communiquer avec les bases de données. Au cours de l’apprentissage, j’ai décidé de me lancer dans un projet qui m’a aidé à cet égard : une simple API de suivi d’inventaire.
En travaillant avec une base de données SQL comme Postgres, j’ai appris qu’il est important de faire des modifications à la base de données en temps opportun. Ainsi, si vous avez un schéma que vous pourriez modifier à l’avenir, la meilleure façon de le faire est avec les migrations de base de données. Cela garantit que les modifications apportées à la base de données sont effectuées avec précision sans affecter les données existantes.
Dans cet article, vous apprendrez à utiliser les migrations de base de données avec Docker et Postgres.
Table des matières
- Qu’est-ce que les migrations de base de données ?
- Comment démarrer et exécuter un conteneur Docker
- Comment créer et exécuter un schéma à l’aide de TablePlus
- Comment installer golang-migrate
- Comment créer une nouvelle migration
- Comment créer et supprimer la base de données à l’intérieur et à l’extérieur d’un conteneur Postgres Docker
- Comment afficher la base de données dans TablePlus
- Comment exécuter les migrations
- Conclusion
Qu’est-ce que la migration de base de données ?
Qu’est-ce que la migration de base de données et pourquoi l’utiliser ? Bien, en tant que développeur backend, lorsque vous travailliez sur un projet qui exige que vous stockiez des données dans une base de données, vous devrez développer un schéma pour les données que vous souhaitez stocker.
Les migrations de base de données vous aident à gérer la structure des données dans une base de données, et dans ce cas, une base de données relationnelle. Les migrations aident à modifier les schémas à partir d’un état courant vers un état spécifique/ souhaité. Cela peut impliquer l’ajout de tables et de colonnes, la suppression d’éléments ou le changement des types et des contraintes.
Une importance de la migration de base de données est de faire des changements dans une base de données répétables et sans bogue sans la préoccupation de la perte de données.
Il est conseillé d’utiliser des migrations si vous n’êtes pas sûr de ce que votre schéma de données final ressemblera. Dans ce sens, vous pouvez implémenter des modifications progressivement.
Comment démarrer et exécuter un conteneur Docker
Ouvrez votre terminal et créez un nouveau dossier mkdir tracking-inventory-app.
Ensuite, téléchargez une image de postgres depuis Docker Hub. J’ai utilisé l’étiquette postgres:14-alpine. Vous pouvez utiliser l’étiquette que vous voulez.
Dans votre terminal, collez ce qui suit et appuyez sur Entrée :
$ docker pull postgres:14-alpine
Après l’installation, démarrez le conteneur en utilisant la commande docker run :
$ docker run --name postgres14 -e POSTGRES_USER=root -e POSTGRES_PASSWORD=passwordd -p 5432:5432 -d postgres:14-alpine
Le drapeau --name fait référence au nom du conteneur. Le drapeau -e correspond aux variables d’environnement. Le drapeau -p signifie que vous devez publier. Vous devez exécuter votre conteneur sur un port spécifique. Le drapeau -d signifie que vous souhaitez le démarrer en mode détaché.
Une fois entré, ouvrez votre Docker Desktop si vous l’avez installé. Si ce n’est pas le cas, vous pouvez le télécharger depuis le site web de Docker.
Dans votre Docker Desktop, vous devez voir que le conteneur a été démarré :
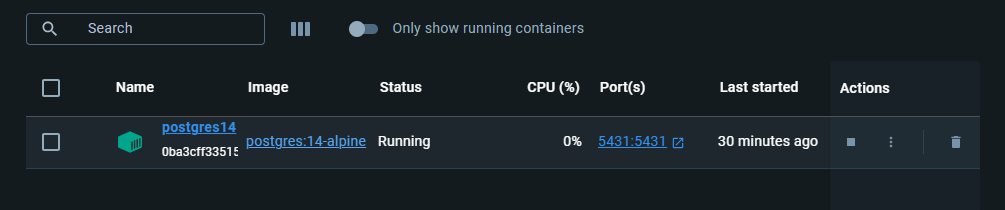
Vous pouvez établir une connexion à la base de données à l’aide de TablePlus :
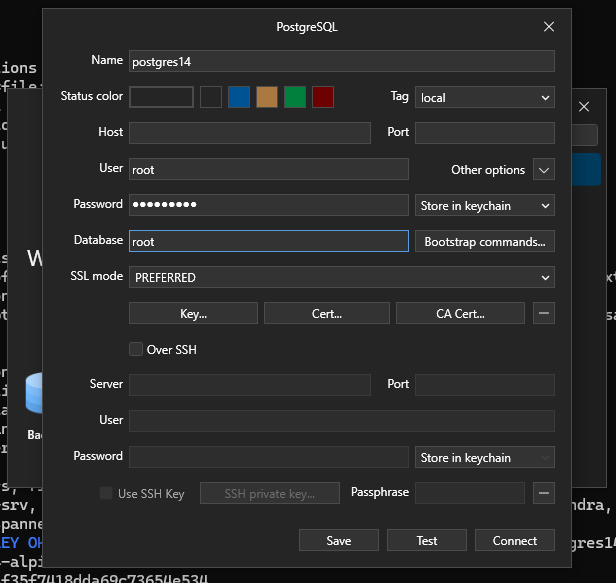
Testez la connexion. Si cela indique « ok », connectez-vous. Si vous êtes sur Windows et qu’il affiche une erreur d’authentification, allez à votre bouton Démarrer et cliquez sur Exécuter. Dans la fenêtre contextuelle, tapez services.msc et appuyez sur Entrée. Recherchez Postgres et cliquez sur le service Stop. Ensuite, essayez de vous connecter à nouveau.
Comment créer et exécuter un schéma à l’aide de TablePlus
J’ai créé un schéma prédéfini/modèle pour le projet tracking-inventory avec db diagram. Ce tracking-inventory devrait vous permettre d’ajouter un article, un numéro de série et une valeur. Donc le schéma aura les champs item, serial_number, id et created_at.
CREATE TABLE "inventory" (
"id" uuid PRIMARY KEY,
"item" varchar NOT NULL,
"serial_number" varchar NOT NULL,
"user" uuid NOT NULL,
"created_at" timestamptz NOT NULL DEFAULT 'now()'
);
CREATE TABLE "user" (
"id" uuid PRIMARY KEY,
"name" varchar NOT NULL,
"email" varchar UNIQUE NOT NULL,
"password" varchar NOT NULL,
"created_at" timestamptz NOT NULL DEFAULT 'now()'
);
CREATE INDEX ON "inventory" ("item");
ALTER TABLE "inventory" ADD FOREIGN KEY ("user") REFERENCES "user" ("id");
C’est comment le mien est. Vous pouvez ouvrir votre TablePlus et ajouter le code PostgreSQL généré et le exécuter.
Comment installer golang-migrate
La prochaine étape consiste à installer golang-migrate sur votre système. J’utilise Windows avec Linux pour ce tutoriel.
Pour l’installer, consultez cette documentation.
Je suis en train d’utiliser Linux, donc je vais utiliser curl :
$ curl -L https://github.com/golang-migrate/migrate/releases/download/v4.12.2/migrate.linux-amd64.tar.gz | tar xvz
Une fois l’installation réussie, exécutez sur votre terminal la commande migrate -help pour voir ses différentes commandes.

Comment créer une nouvelle migration
Après l’installation de golang-migrate, vous pouvez créer un nouveau script de migration.
Tout d’abord, dans votre terminal et à l’intérieur du répertoire tracking-app, ouvrez VS Code avec la commande code.
Une fois que c’est fait, créez un nouveau dossier nommé db et un autre dossier à l’intérieur du dossier db nommé migrations.
Ensuite, dans votre terminal, exécutez la commande suivante :
$ migrate create -ext sql -dir db/migration -seq tracking_inventory_schema
Le drapeau -ext fait référence à l’extension que vous souhaitez pour la migration. Dans ce cas, c’est sql. Le drapeau -dir se réfère au répertoire où vous voulez créer les fichiers. Le drapeau -seq se réfère au numéro séquentiel pour les fichiers de migration.
Dans VS Code, il devrait y avoir deux fichiers : l’un pour up et un autre pour down. Le premier est utilisé pour faire des modifications avant dans le répertoire tandis que le second est pour annuler les modifications.
Dans le fichier up, vous allez coller votre schéma dans le fichier.
Mon schéma ressemble à celui-ci :
CREATE TABLE "inventory" (
"id" uuid PRIMARY KEY,
"item" varchar NOT NULL,
"serial_number" varchar NOT NULL,
"user" uuid NOT NULL,
"created_at" timestamptz NOT NULL DEFAULT 'now()'
);
CREATE TABLE "user" (
"id" uuid PRIMARY KEY,
"name" varchar NOT NULL,
"email" varchar UNIQUE NOT NULL,
"password" varchar NOT NULL,
"created_at" timestamptz NOT NULL DEFAULT 'now()'
);
CREATE INDEX ON "inventory" ("item");
ALTER TABLE "inventory" ADD FOREIGN KEY ("user") REFERENCES "user" ("id");
Votre schéma peut ressembler à différents projets selon ce que vous construisez.
Pour le fichier down, collez simplement cela :
DROP TABLE IF EXISTS inventory;
DROP TABLE IF EXISTS user;
La table d’inventaire devrait d’abord être supprimée parce qu’elle référence la table des utilisateurs.
Comment créer et supprimer la base de données à l’intérieur et à l’extérieur d’un conteneur Postgres Docker
Vérifiez si votre conteneur Docker est en cours d’exécution en utilisant la commande :
$ docker ps
Si ce n’est pas le cas, utilisez la commande docker start ${container name} pour le démarrer.
La prochaine étape consiste à accéder à la console Postgres en utilisant la commande suivante, puisque je suis sur Linux :
$ docker exec -it postgres14 bin/bash
Le flag -it signifie shell interactif/terminal. Dans cette console, vous pouvez exécuter la commande createdb :
/# createdb --username=root --owner=root tracking_inventory
Une fois créée, vous pouvez exécuter la commande psql pour interagir avec la base de données :
/# psql tracking-inventory
psql (14.12)
Type "help" for help.
tracking_inventory=#
Vous pouvez également supprimer la base de données avec la commande dropdb.
Pour quitter la console, utilisez la commande exit.
Pour créer la base de données à l’extérieur du conteneur Postgres, collez la commande suivante :
$ docker exec -it postgres14 createdb --username=root --owner=root tracking_inventory
Comment afficher la base de données dans TablePlus
Pour afficher la base de données que vous avez créée, connectez-vous en utilisant la connexion que nous avons établie plus tôt. Elle vous amènera au racine de la base de données, puis cliquez sur l’icône de la base de données en haut.
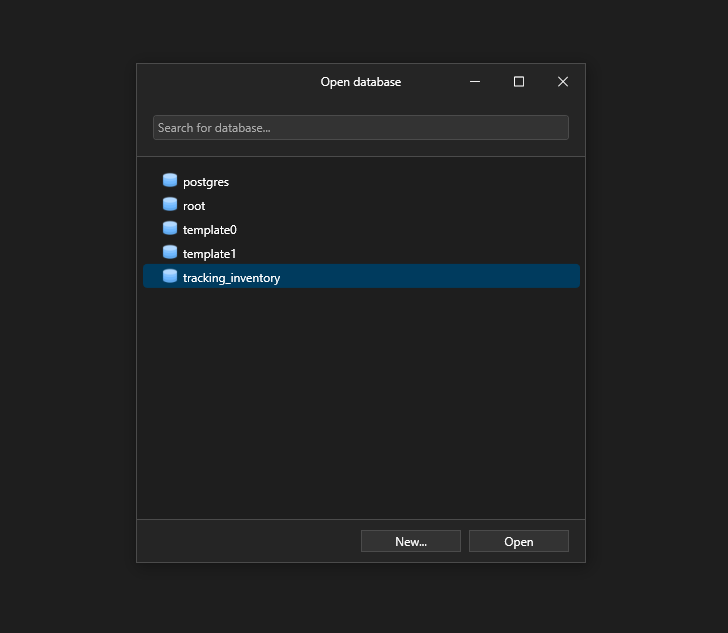
La base de données créée apparaîtra, puis cliquez simplement sur ouvrir pour l’ouvrir
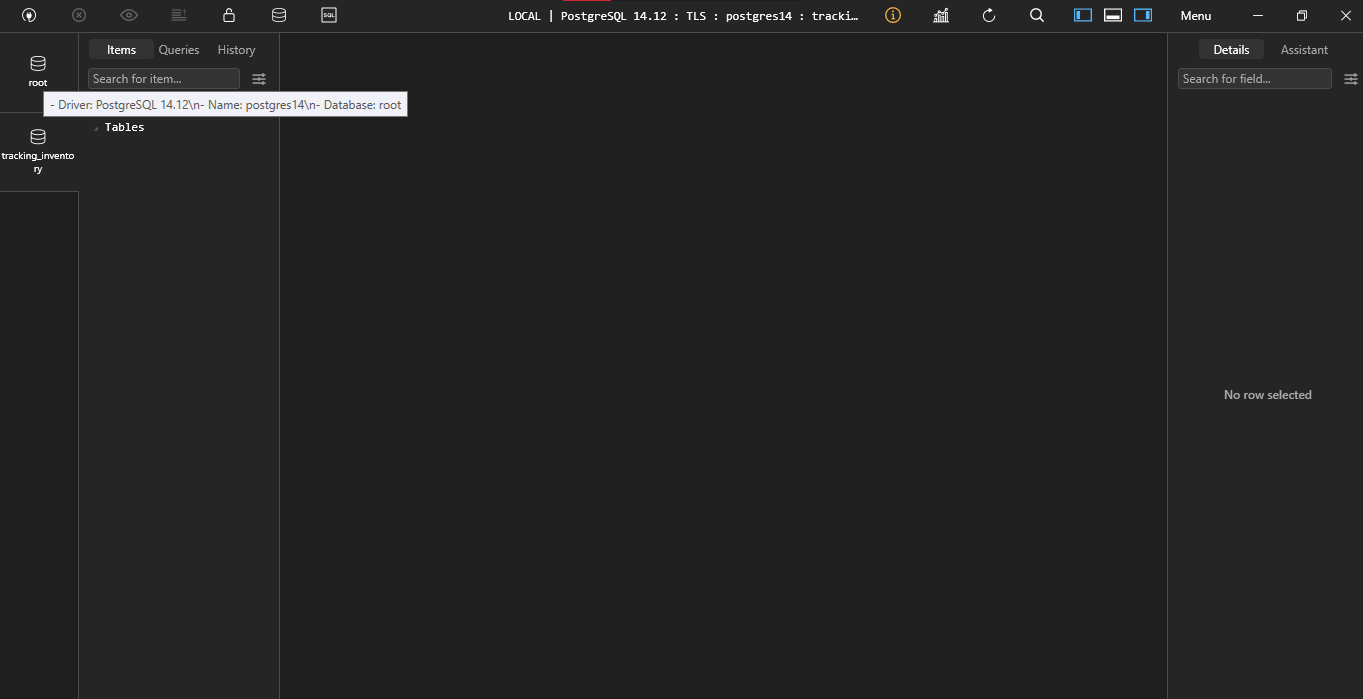
Comment exécuter les migrations
Pour exécuter les migrations, exécutez cette commande dans votre terminal :
$ migrate -path db/migration -database "postgresql://root:passwordd@localhost:5432/tracking_inventory?sslmode=disable" -verbose up
Le drapeau -path spécifie le chemin contenant les fichiers de migration. L’option -database spécifie l’URL vers la base de données.
Dans l’URL, le pilote est postgresql. Le nom d’utilisateur et le mot de passe sont respectivement root et passwordd. Il est également important d’ajouter l’option sslmode=disable car Postgres ne configure pas SSL par défaut.
Maintenant, exécutez les migrations :
$ migrate -path db/migration -database "postgresql://root:passwordd@localhost:5432/tracking_inventory?sslmode=disable" -verbose up
calhost:5432/tracking_inventory?sslmode=disable" -verbose up
2024/06/25 00:13:25 Start buffering 1/u tracking_inventory_schema
2024/06/25 00:13:25 Read and execute 1/u tracking_inventory_schema
2024/06/25 00:13:26 Finished 1/u tracking_inventory_schema (read 43.186044ms, ran 255.501635ms)
2024/06/25 00:13:26 Finished after 312.928488ms
2024/06/25 00:13:26 Closing source and database
La migration est réussie !
Rechargez la base de données et observez les nouvelles tables :

##Conclusion
Dans ce tutoriel, vous avez appris comment écrire et exécuter des migrations de base de données en utilisant Docker et Postgres en Go de manière transparente. J’espère que vous avez appris beaucoup grâce à cet article.
Source:
https://www.freecodecamp.org/news/how-to-create-database-migrations-in-go/