













Haftungsausschluss: Alle Ansichten und Meinungen, die im Blog geäußert werden, gehören ausschließlich dem Autor und nicht unbedingt dem Arbeitgeber des Autors oder einer anderen Gruppe oder Person. Dieser Artikel ist keine Werbung für eine Cloud-/Datenmanagement-Plattform. Alle Bilder und APIs sind öffentlich auf der Azure-/Databricks-Website verfügbar..
Was ist Databricks Lakehouse Monitoring?
In meinen anderen Artikeln habe ich beschrieben, was Databricks und der Unity Catalog sind und wie man einen Katalog von Grund auf mit einem Skript erstellt. In diesem Artikel werde ich das Lakehouse Monitoring-Feature beschreiben, das als Teil der Databricks-Plattform verfügbar ist, und wie man das Feature mit Skripten aktiviert.
Lakehouse Monitoring bietet Datenprofilierung und datenqualitätsbezogene Metriken für die Delta Live Tables im Lakehouse. Databricks Lakehouse Monitoring bietet umfassende Einblicke in die Daten, wie Änderungen im Datenvolumen, Änderungen der numerischen Verteilung, Prozentsatz von Nullwerten und Nullen in den Spalten sowie die Erkennung kategorischer Anomalien im Laufe der Zeit.
Warum Lakehouse Monitoring verwenden?
Die Überwachung Ihrer Daten und der Leistungen Ihres ML-Modells bietet quantitative Maßnahmen, die Ihnen helfen, die Qualität und Konsistenz Ihrer Daten und Modellleistungen im Laufe der Zeit zu verfolgen und zu bestätigen.
Hier ist eine Aufschlüsselung der wichtigsten Funktionen:
- Datenqualität und Datenintegritätsverfolgung: Verfolgt den Datenfluss über Pipelines, gewährleistet die Datenintegrität und bietet Einblicke darin, wie sich die Daten im Laufe der Zeit verändert haben, 90. Perzentil einer numerischen Spalte, % der Null- und Nullspalten, usw.
- Datenveränderungen im Laufe der Zeit: Bietet Metriken zur Erkennung von Datenveränderungen zwischen den aktuellen Daten und einem bekannten Ausgangspunkt oder zwischen aufeinanderfolgenden Zeitfenstern der Daten
- Statistische Verteilung der Daten: Bietet numerische Verteilungsänderungen der Daten im Laufe der Zeit, die beantworten, wie sich die Verteilung der Werte in einer kategorialen Spalte ändert und wie sie sich von der Vergangenheit unterscheidet
- Leistung und Vorhersageveränderungen des ML-Modells: ML-Modellinputs, Vorhersagen und Leistungstrends im Laufe der Zeit
So funktioniert es
Das Databricks Lakehouse Monitoring bietet die folgenden Arten von Analysen: Zeitreihen, Snapshot und Inferenz.
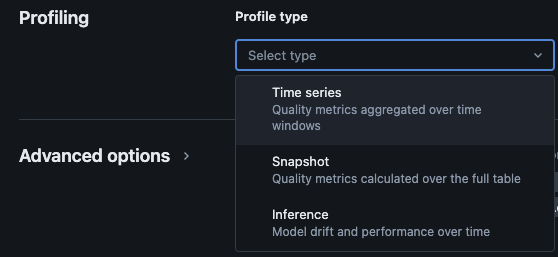
Profiltypen für die Überwachung
Wenn Sie das Lakehouse-Monitoring für eine Tabelle im Unity-Katalog aktivieren, werden zwei Tabellen im angegebenen Überwachungs-Schema erstellt. Sie können die Tabellen abfragen und Dashboards erstellen (Databricks bietet standardmäßig ein konfigurierbares Dashboard direkt nach der Installation) sowie Benachrichtigungen zu den Tabellen einrichten, um umfassende statistische und Profilinformationen über Ihre Daten im Laufe der Zeit zu erhalten.
- Drift-Metrik-Tabelle: Die Drift-Metrik-Tabelle enthält Statistiken zu den Abweichungen der Daten über die Zeit. Sie erfasst Informationen wie Unterschiede in der Anzahl, den Unterschied im Durchschnitt, den Unterschied in % null und Nullen usw.
- Profil-Metrik-Tabelle: Die Profil-Metrik-Tabelle enthält zusammenfassende Statistiken für jede Spalte und für jede Kombination aus Zeitfenster, Slice und Gruppierungsspalten. Für die Analyse des InferenceLogs enthält die Analysentabelle auch Metriken zur Modellgenauigkeit.
So aktivieren Sie das Lakehouse-Monitoring über Skripte
Voraussetzungen
- Unity Catalog, Schema und Delta Live Tables sind vorhanden.
- Der Benutzer ist der Eigentümer der Delta Live Table.
- Für private Azure Databricks-Cluster ist private Konnektivität von serverlosem Compute konfiguriert.
Schritt 1: Erstellen Sie ein Notebook und installieren Sie das Databricks SDK
Erstellen Sie ein Notebook im Databricks-Workspace. Um ein Notebook in Ihrem Workspace zu erstellen, klicken Sie auf das „+“ Neu in der Seitenleiste und wählen Sie dann Notebook.
Ein leeres Notebook öffnet sich im Workspace. Stellen Sie sicher, dass Python als Notebook-Sprache ausgewählt ist.
Kopieren Sie den untenstehenden Code-Ausschnitt in die Notebook-Zelle und führen Sie die Zelle aus.
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
Schritt 2: Variablen erstellen
Kopieren Sie den untenstehenden Code-Ausschnitt in die Notebook-Zelle und führen Sie die Zelle aus.
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
Schritt 3: Überwachungsschema erstellen
Kopieren Sie den untenstehenden Code-Ausschnitt in die Notebook-Zelle und führen Sie die Zelle aus. Dieser Ausschnitt erstellt das Überwachungsschema, falls es noch nicht vorhanden ist.
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
Schritt 4: Monitor erstellen
Kopieren Sie den untenstehenden Code-Ausschnitt in die Notebook-Zelle und führen Sie die Zelle aus. Dieser Ausschnitt erstellt das Lakehouse-Monitoring für alle Tabellen innerhalb des Schemas.
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
Validierung
Nach erfolgreicher Ausführung des Skripts können Sie zu Katalog -> Schema -> Tabelle navigieren und zum Tab „Qualität“ in der Tabelle gehen, um die Überwachungsdetails anzuzeigen.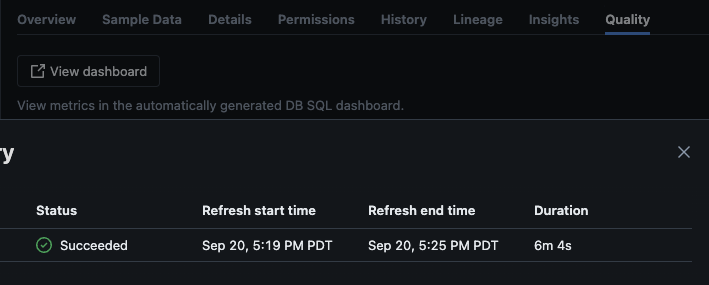
Wenn Sie auf die Schaltfläche „Dashboard anzeigen“ in der oberen linken Ecke der Überwachungs-Seite klicken, wird das Standardüberwachungsdashboard geöffnet. Anfangs sind die Daten leer. Während die Überwachung nach Zeitplan läuft, werden im Laufe der Zeit alle statistischen, Profil- und Datenqualitätswerte ausgefüllt.
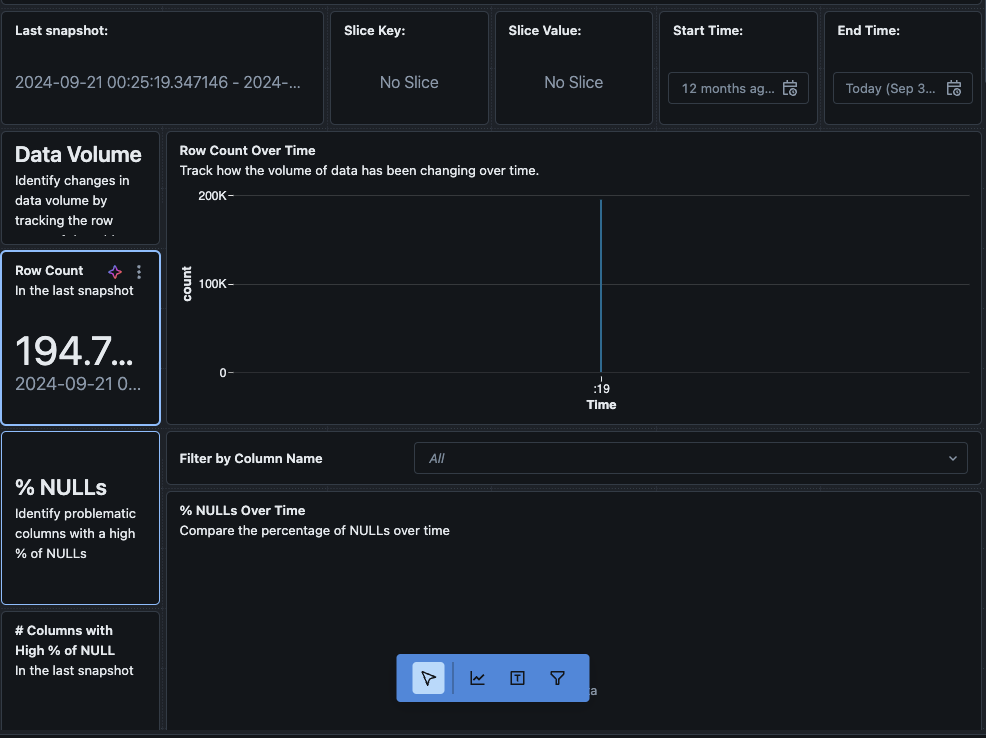
Sie können auch zum „Daten„-Tab im Dashboard navigieren. Databricks bietet standardmäßig eine Liste von Abfragen, um den Verlauf und andere Profilinformationen zu erhalten. Sie können auch eigene Abfragen erstellen, um im Laufe der Zeit einen umfassenden Überblick über Ihre Daten zu erhalten.
Zusammenfassung
Das Databricks Lakehouse Monitoring bietet einen strukturierten Weg, um die Datenqualität, Profilmetriken und Datenabweichungen im Laufe der Zeit zu verfolgen. Durch die Aktivierung dieser Funktion über Skripte können Teams Einblicke in das Datenverhalten erhalten und die Zuverlässigkeit ihrer Datenpipelines gewährleisten. Der in diesem Artikel beschriebene Einrichtungsprozess bildet die Grundlage für die Aufrechterhaltung der Datenintegrität und die Unterstützung laufender Datenanalysebemühungen.
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring