













تشغيل وصيانة سجلات الشبكة أو أجهزة الإنترنت من الأشياء.
السجلات هي الملاحظة أن سجلات الأعمال هي أساس فهم المستخدم.
ومع ذلك، قد تكون السجلات صعبة التعامل بسبب:
- تدفقها بشكل كبير. كل حدث نظامي أو نقرة من المستخدم تولد سجلًا. غالبًا ما ينتج شركة تيرابايت عدد هائل من السجلات الجديدة يوميًا.
- إنها كبيرة الحجم. من المفترض أن تبقى السجلات. قد لا تكون مفيدة حتى تصبح كذلك. لذا يمكن للشركة تراكم ما يصل إلى بيتابايت من بيانات السجل، والكثير منها لا يزال غير مستخدم ولكنه يستغرق مساحة تخزين هائلة.
- يجب أن تكون سريعة التحميل والعثور عليها. تحديد السجل المستهدف للتحقيق في مشكلة التشغيل يشبه حقًا البحث عن إبرة في مجموعة القش. يتطلع الناس إلى كتابة السجلات في الوقت الفعلي والاستجابة لاستعلامات السجلات في الوقت الفعلي.
الآن يمكنك رؤية لمحة صادقة عن ما يجب أن يكون عليه نظام معالجة السجلات المثالي. يجب أن يدعم ما يلي:
- امتصاص البيانات الفعلية العالية المعدل: يجب أن يكون قادرًا على كتابة مدونات كمية كبيرة وجعلها مرئية فورًا.
- التخزين بأسعار معقولة: يجب أن يكون قادرًا على تخزين كميات كبيرة من السجلات دون تكلفة كبيرة.
- البحث الفوري في النص: يجب أن يكون قادرًا على البحث السريع في النص.
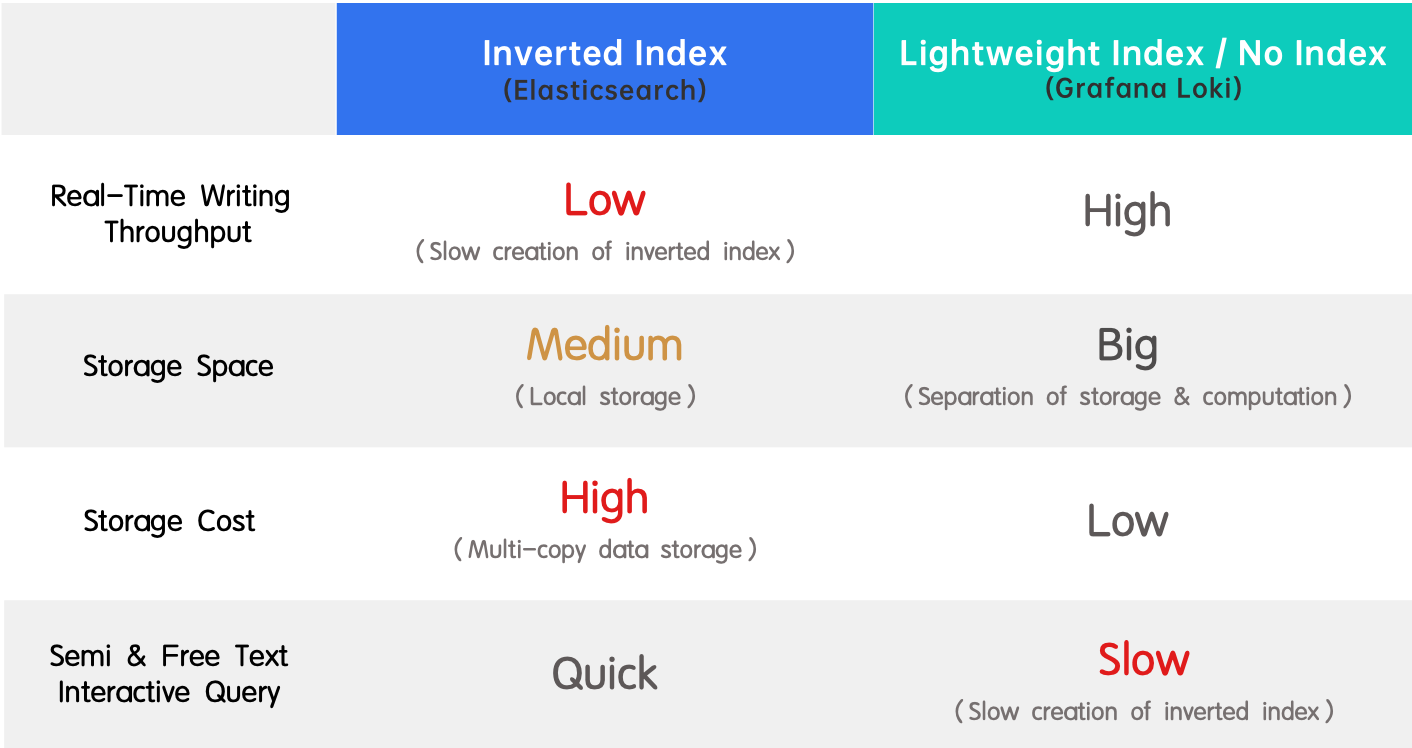
الحلول الشائعة: Elasticsearch و Grafana Loki
هناك حلان شائعان لمعالجة السجلات في الصناعة، ممثلان بـ Elasticsearch و Grafana Loki على التوالي.
- فهرس معكوس (Elasticsearch): يحظى بتبني واسع نظرًا لدعمه للبحث الكامل النصوص والأداء العالي. الجانب السلبي هو الناتج المنخفض في الكتابة الفورية واستهلاك الموارد الهائل في إنشاء الفهرس.
- فهرس خفيف / بدون فهرس (Grafana Loki): إنه عكس الفهرس المعكوس لأنه يتميز بناتج الكتابة الفوري العالي وتكلفة التخزين المنخفض ولكنه يوفر استعلامات بطيئة.
مقدمة للفهرس المعكوس
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
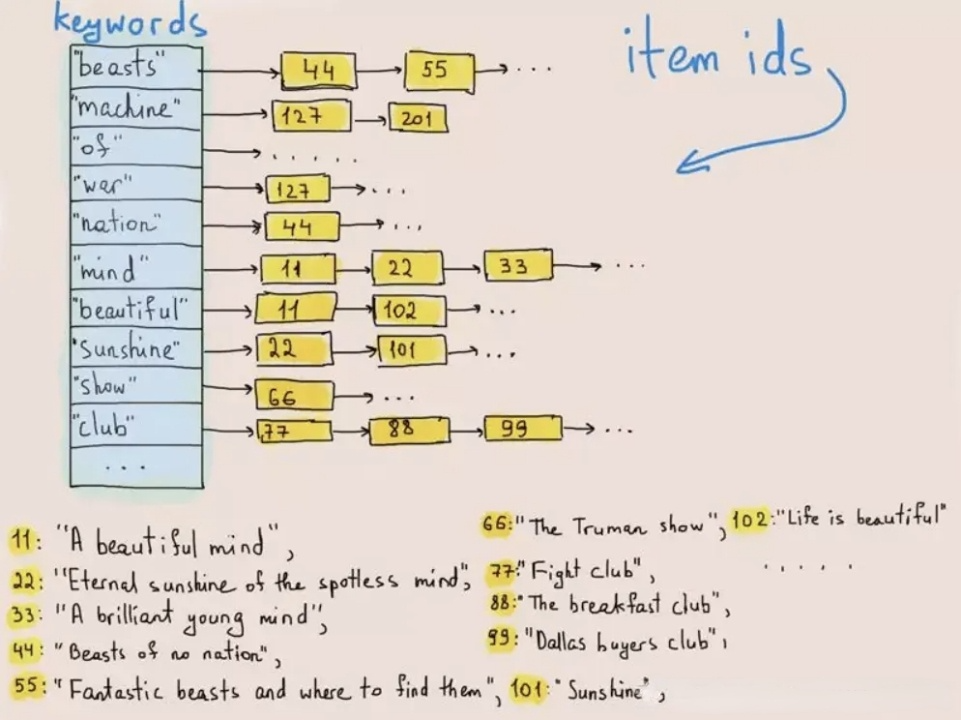
كان الفهرس المعكوس في الأصل يستخدم لاسترداد الكلمات أو العبارات في النصوص. يوضح الشكل التالي كيف يعمل:
عند كتابة البيانات، يقوم النظام بتفكيك النصوص إلى المصطلحات ويخزن هذه المصطلحات في قائمة النشر التي تربط المصطلحات بمعرفة الصف الذي توجد فيه. في استعلامات النص، يجد قاعدة البيانات معرفة الصف المقابل للكلمة المفتاحية (المصطلح) في قائمة النشر ويسترد الصف المستهدف بناءً على معرفة الصف. بهذه الطريقة، لن يضطر النظام للتنقل في المواد التعليمية بأكملها وبالتالي يحسن سرعة الاستعلام بمقادير كبيرة.
في الفهرسة العكسية لـ Elasticsearch، تأتي الاسترجاع السريع على حساب سرعة الكتابة، تصدُّر الكتابة، ومساحة التخزين. لماذا؟ أولاً، تحليل التوكن، فرز القاموس، وإنشاء الفهرس العكسي كلها عمليات مكرّسة للمعالجة والذاكرة. ثانياً، Elasticssearch يجب أن يخزن البيانات الأصلية، الفهرس العكسي، ونسخة إضافية من البيانات المخزنة في الأعمدة لتسريع الاستعلامات. هذا تكرار ثلاثي.
ولكن بدون فهرس عكسي، Grafana Loki، على سبيل المثال، يؤدي إلى تدهور تجربة المستخدم بسبب تحقيقاته البطيئة، وهو أكبر مشكلة يواجهها المهندسون في تحليل السجلات.
ببساطة، Elasticsearch وGrafana Loki تمثلان تنازلات مختلفة بين تصدُّر الكتابة العالي، تكلفة التخزين المنخفضة، وأداء الاستعلام السريع. ماذا لو أخبرتك أن هناك طريقة لتحقيقها كلها؟ لقد قدمنا الفهارس العكسية في Apache Doris 2.0.0 وقمنا بتحسينها إلى حد تحقيق أداء تحقيق السجلات أسرع مرتين من Elasticsearch باستخدام 1/5 من المساحة التي يستخدمها. مجتمعين كلا العاملين، هو حل أفضل 10 مرات.
الفهرس العكسي في Apache Doris
عمومًا، هناك طريقتين لتنفيذ الفهارس: نظام الفهرسة الخارجي أو الفهارس المدمجة.
نظام الفهرسة الخارجي: يتم توصيل نظام فهرسة خارجي بقاعدة البيانات الخاصة بك. في عملية استيراد البيانات، يتم استيراد البيانات إلى كلا النظامين. بعد أن يقوم نظام الفهرسة بإنشاء الفهارس، يقوم بحذف البيانات الأصلية داخل نفسه. عندما يدخل مستخدمو البيانات استعلامًا، يقدم نظام الفهرسة أيدي البيانات المتعلقة، ثم تقوم قاعدة البيانات بالبحث عن البيانات المستهدفة استنادًا إلى تلك الأيدي.
إن بناء نظام فهرسة خارجي أسهل وأقل تدخلًا في قاعدة البيانات، لكنه يأتي مع بعض العيوب المزعجة:
- الحاجة إلى كتابة البيانات في نظامين يمكن أن تؤدي إلى عدم انسجام البيانات والتكرار في التخزين.
- التفاعل بين قاعدة البيانات ونظام الفهرسة تجلب الإضافيات، لذا عندما تكون البيانات المستهدفة كبيرة، يمكن أن يكون الاستعلام عبر النظامين بطيئًا.
- من المرهق الصيانة لنظامين.
في أباتشي دوريس، نفضل الطريقة الأخرى. الفهارس المعكوسة المدمجة أصعب في الإعداد، لكنها عندما تنجز، تكون أسرع، أكثر صديقة للمستخدم، وخالية من المتاعب في الصيانة.
في أباتشي دوريس، يتم ترتيب البيانات بالشكل التالي. الفهارس مخزنة في منطقة الفهرسة:
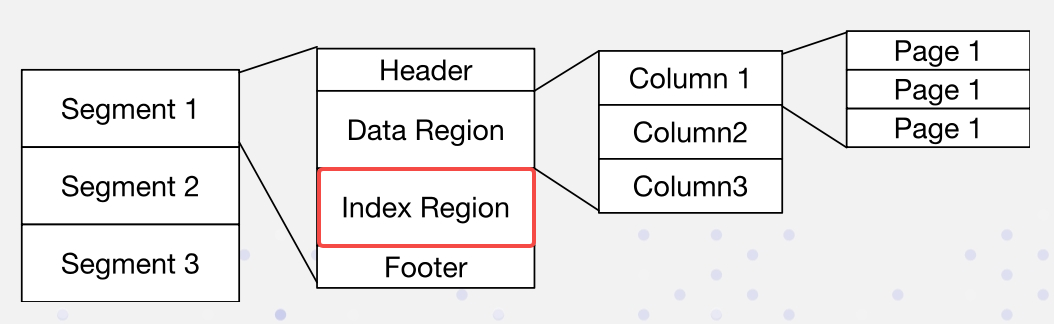
نحن ننفذ الفهارس المعكوسة بطريقة غير متصلة:
- استيراد البيانات والتكثيف: عندما يتم كتابة ملف قطعة في دوريس، سيتم كتابة ملف فهرس معكوس أيضًا. يتم تحديد مسار ملف الفهرس بواسطة رقم القطعة ورقم الفهرس. الصفوف في المقاطع تتوافق مع المستندات في الفهارس، وهكذا الرقم السطري ورقم المستند.
- استفسار: إذا تضمنت عبارة
حيثفي الشرط عمودًا يتم فيه تصفية الفهرس، سيقوم النظام بالبحث في ملف الفهرس، سيعيد قائمة DocID، ويحول قائمة DocID إلى بتماسك RowID. تحت آلية تصفية RowID في Apache Doris، سيتم قراءة فقط الصفوف المستهدفة. هكذا يتم تسريع الاستعلامات.
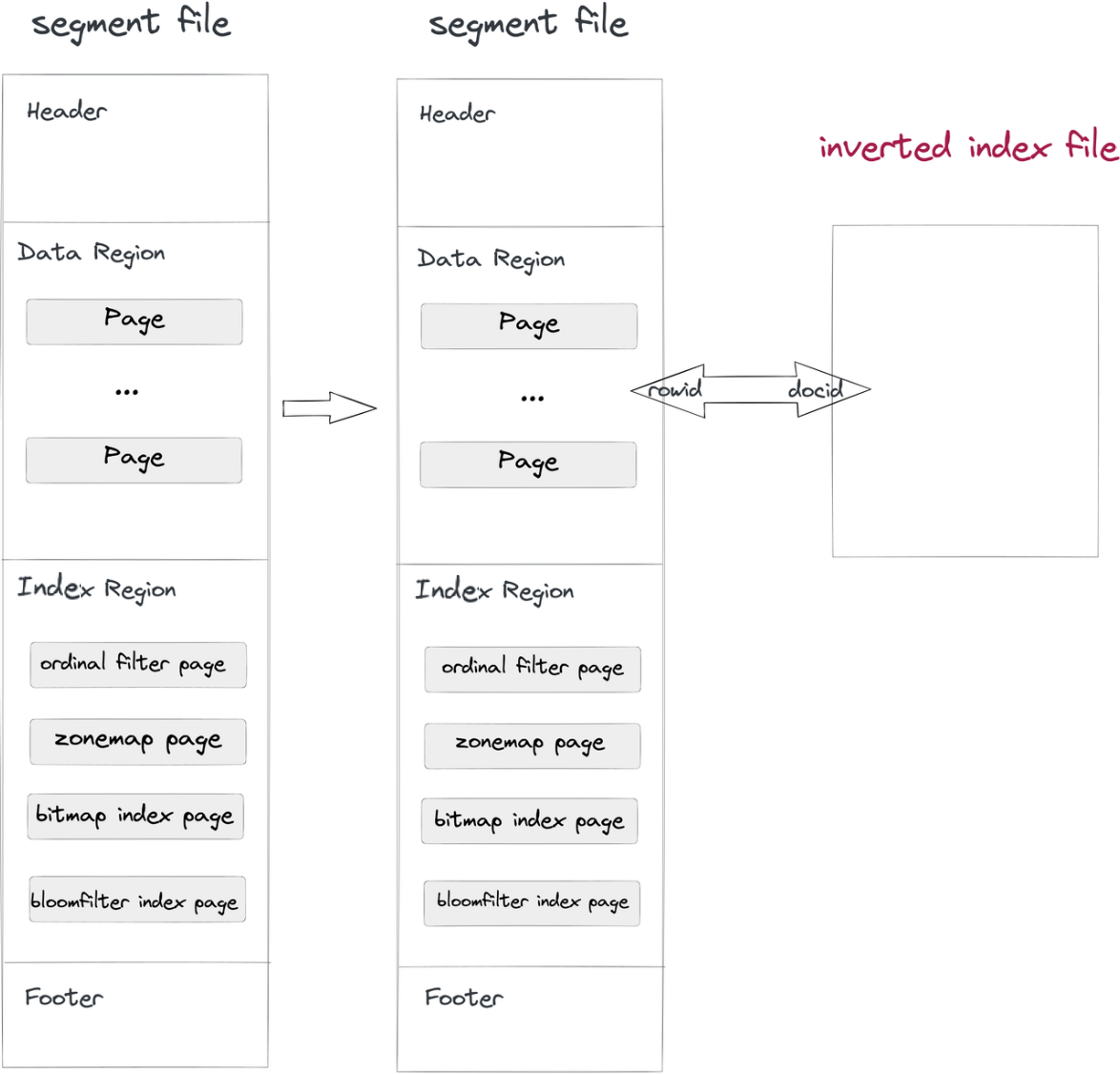
طريقة غير متصاصة من هذا القبيل تفصل ملف الفهرس عن ملفات البيانات، لذا يمكنك إجراء أي تغييرات في الفهارس المقلوبة دون القلق من التأثير على ملفات البيانات نفسها أو الفهارس الأخرى.
التحسينات للفهرس المقلوب
التحسينات العامة
C++ Implementation and Vectorization
على عكس Elasticsearch، الذي يستخدم Java، يُنفذ Apache Doris بلغة C++ في مكونات التخزين، محرك تنفيذ الاستعلامات، والفهارس المقلوبة. مقارنة بـ Java، يوفر C++ أداءً أفضل، يسمح بالتعديل أسهل، ولا ينتج عنه أية جرعات GC لآلة JVM. لقد مررنا بكل خطوة من خطوات الفهرسة المقلوبة في Apache Doris، مثل التفريع، إنشاء الفهرس، والاستعلامات. لتقديم وجهة نظر لك، في الفهرسة المقلوبة، يكتب Apache Doris بسرعة 20 ميغا بايت/ثانية لكل أربعة أضعاف سرعة Elasticsearch (5 ميغا بايت).
التخزين العمودي والضغط
يقوم Apache Lucene بتأسيس الفهارس المقلوبة في Elasticsearch. حيث أن Lucene نفسه مبني لدعم تخزين الملفات، يخزن البيانات بشكل موجه للصفوف.
في Apache Doris، تكون الفهارس المقلوبة لأعمدة مختلفة معزولة عن بعضها البعض، وتتبع ملفات الفهرس المقلوبة تخزين عمودي لتسهيل التعديل وضغط البيانات.
باستخدام ضغط Zstandard، Apache Doris يحقق نسبة ضغط تتراوح بين 5:1 إلى 10:1، سرعة ضغط أسرع، واستخدام 50% أقل مساحة مقارنة بضغط GZIP.
أشجار BKD للأعمدة العددية / التواريخ
يُنفذ Apache Doris أشجار BKD للأعمدة العددية والتواريخ. هذا لا يزيد فقط من أداء الاستعلامات عن طريقة النطاق ولكنه أيضًا طريقة أكثر توفيرًا للمساحة مقارنة بتحويل هذه الأعمدة إلى سلاسل ثابتة الطول. تشمل مزايا ذلك:
- استعلامات النطاق الفعالة: يمكنها تحديد نطاق البيانات المستهدف بسروعة في الأعمدة العددية والتواريخ.
- مساحة تخزين أقل: تجمع وتضغط على كتل بيانات مجاورة للحد من تكاليف التخزين.
- دعم البيانات متعددة الأبعاد: أشجار BKD قابلة للتوسع وتكيفية بشأن أنواع البيانات متعددة الأبعاد، مثل نقاط GEO والنطاقات.
بالإضافة إلى أشجار BKD، قمنا بتحسين أداء الاستعلامات على الأعمدة العددية والتواريخ.
- تحسين الحالات ذات الكميات المنخفضة: لقد ضبطنا خوارزمية الضغط للحالات ذات الكميات المنخفضة، لذا ستستهلك عمليات التحليل وفك التسلسل للقوائم المعكوسة الضخمة موارد معالجة أقل.
- الاستيلاء المسبق: بالنسبة للحالات ذات معدل الإصابة العالي، نتبنى الاستيلاء المسبق. إذا تجاوز معدل الإصابة عتبة معينة، ستتخطى Doris عملية الفهرسة وتبدأ في تصفية البيانات.
تحسينات مبنية خصيصًا لـ OLAP
عادة، تحليل السجلات يكون نوعًا بسيطًا من الاستعلامات بدون حاجة لميزات متقدمة (مثل تسعير الأهمية في أباتشي لوسين). القدرة الأساسية لأداة معالجة السجلات هي الاستعلامات السريعة وتكلفة التخزين المنخفضة. ولذلك، في أباتشي دوريس، قمنا بتبسيط بنية الفهرسة العكسية لتلبية احتياجات قاعدة بيانات OLAP.
- في توصيل البيانات، نمنع توظيف خيوط متعددة لكتابة البيانات في نفس الفهرس، وبالتالي نتجنب الجدل الناتج عن تنافس القفل.
- نتخلص من ملفات الفهرس الأمامي وملفات Norm لتخليص مساحة التخزين وتقليل الجهد التخزيني.
- نبسط منطق حساب التسعير والترتيب المتعلق بالأهمية لتقليل الجهد أكثر وزيادة الأداء.
بالنظر إلى أن السجلات تُقسم حسب مدى الزمن والسجلات التاريخية تزيد على زيارات أقل بكثير، نعتزم تقديم إدارة فهرسة أكثر تنوعًا ومرونة في إصدارات فريق أباتشي دوريس المستقبلية:
- إنشاء فهرس عكسي لقسم بيانات محدد: إنشاء فهرس لسجلات الأسبوع السابق، إلخ.
- حذف فهرس عكسي لقسم بيانات محدد: حذف فهرس لسجلات قبل شهر على الأقل، إلخ. (لتخليص مساحة الفهرس).
اختبار الأداء
قمنا باختبار أباتشي دوريس على مجموعات بيانات متاحة بشكل عام ضد إلستيك سيرش وكليكهاوس.
من أجل مقارنة عادلة، نتأكد من انتظام ظروف الاختبار، بما في ذلك أداة الاختبار، المجموعات البيانات، والأجهزة.
أباتشي دوريس مقابل إلستيك سيرش
- أداة المقارنة: ES Rally، أداة الاختبار الرسمية لـ Elasticsearch
- مجموعة البيانات: سجلات خادم HTTP كأس العالم لعام 1998 (مجموعة البيانات موجودة في ES Rally)
- حجم البيانات (قبل الضغط): 32 جيجابايت، 247 مليون سطر، 134 بايت لكل سطر (في المتوسط)
- الاستعلام: 11 استعلام، بما في ذلك البحث بالكلمات المفتاحية، الاستعلام بالنطاق، التجميع، والترتيب؛ كل استعلام يتم تنفيذه بشكل متسلسل 100 مرة.
- البيئة: 3 آلاف من آلات البيور الظاهرية بحجم 16C 64G
نتائج Apache Doris:
- سرعة الكتابة: 550 ميغابايت/ثانية،4.2 مرة من Elasticsearch
- نسبة الضغط: 10:1
- استخدام التخزين: 20% من Elasticsearch
- مدة الاستجابة: 43% من Elasticsearch

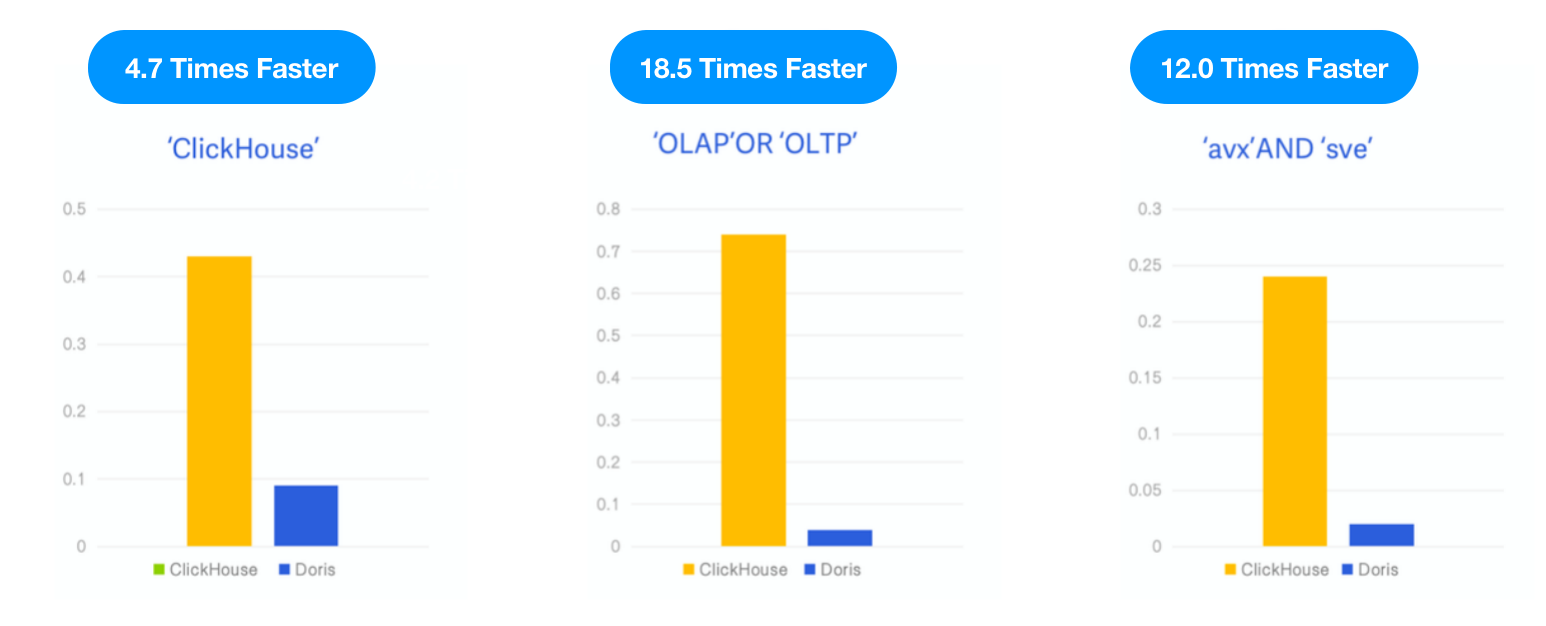
Apache Doris مقابل ClickHouse
حيث طُلق عند ClickHouse ميزة الفهرس العكسي كميزة تجريبية في الإصدار 23.1، قمنا باختبار Apache Doris بنفس مجموعة البيانات وال SQL الموصوفة في مدونة ClickHouse وقارنا أداء الاثنين تحت نفس موارد الاختبار والحالة والأداة.
- البيانات: 6.7 جيجابايت، 28.73 مليون سطر، مجموعة بيانات Hacker News، تنسيق Parquet
- الاستعلام: 3 بحث بالكلمات المفتاحية، حساب عدد التكرارات للكلمات المفتاحية “ClickHouse”، “OLAP”، أو “OLTP”، و”avx” AND “sve”.
- البيئة: آلة في البيور الظاهرية بحجم 1 × 16C 64G
النتيجة: Apache Doris كان 4.7 مرة، 18.5 مرة، و 12 مرة أسرع من ClickHouse في الاستعلامات الثلاثة، على التوالي.
استخدام ومثال
- المجموعة البيانات: مليون سجل تعليق من Hacker News
الخطوة 1: تحديد الفهرس المعكوس للجدول البيانات عند إنشاء الجدول.
المعلمات:
- INDEX idx_comment (
comment): إنشاء فهرس يسمى “idx_comment” لعمود “comment” - USING INVERTED: تحديد الفهرس المعكوس للجدول
- PROPERTIES(“parser” = “english”): تحديد لغة التفكيك لتكون الإنجليزية
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(ملاحظة: يمكنك إضافة فهرس لجدول موجود عبر ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english"). على عكس فهرس الذكاء والفهرس الثانوي، إنشاء الفهرس المعكوس يتضمن فقط قراءة عمود التعليق، لذا يمكن أن يكون أسرع بكثير.)
الخطوة 2: استرداد الكلمتين “OLAP” و “OLTP” في عمود التعليق باستخدام MATCH_ALL. كان وقت الاستجابة هنا 1/10 من ذلك في المطابقة الصعبة باستخدام like. (يزداد الفجوة في الأداء مع زيادة حجم البيانات.)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
لمزيد من مقدمة الميزات ودليل الاستخدام، انظر الوثائق: الفهرس المعكوس
تلخيص
باختصار، ما يساهم في أن يكون Apache Doris أكثر كفاءة واقعية بعشر مرات مقارنةً بـ Elasticsearch هو تحسيناته المصممة للمعالجة التحليلية المباشرة (OLAP) للفهرسة العكسية، مدعومة بمحرك تخزين العمود، إطار المعالجة الموازية الهائلة، محرك الاستعلام المتجه، ومحول التكلفة في Apache Doris.
ومع أننا فخورون بحلنا الخاص للفهرسة العكسية، ندرك أن المقاييس المنشورة من الشخص الواحد قد تكون مثيرة للجدل، لذا نكون متقبلين للملاحظات من أي مختبر ثالث ونرى كيف يعمل Apache Doris في الحالات الفعلية العالمية.
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co