













في معظم شركات المالية، غالبًا ما يعتمد المعالجة المباشرة للمعاملات عبر الإنترنت (OLTP) على بيانات ثابتة أو تحديثها في الغالب نادرًا، والتي تعرف أيضًا بـ البيانات المرجعية. مصادر البيانات المرجعية لا تحتاج دائمًا إلى قدرات المعاملات ACID، بل تحتاج إلى دعم لاستعلامات القراءة السريعة غالبًا مبنية على أنماط الوصول البيانات البسيطة، وهيكل الأحداث القائم لضمان أن يظل النظام المستهدف محدثًا. قواعد البيانات NoSQL تظهر كمرشحون مثاليون لتلبية هذه المتطلبات، وتقدم منصات الغير محدد مثل AWS بيئات بيانات مدارة ومرنة بشكل كبير.
في هذا المقال، لن أحدد أي قاعدة بيانات NoSQL على AWS هي الأفضل: مفهوم القاعدة البيانات الأفضل يتواجد فقط في سياق محدد عمليًا. سأشارك مختبر برمجة لقياس أداء قواعد البيانات NoSQL المدارة بواسطة AWS مثل DynamoDB، Cassandra، Redis، و MongoDB.
تجربة الأداء
I will start by defining the performance test case, which will concurrently insert a JSON payload 200 times and then read it 200 times.
حزمة JSON
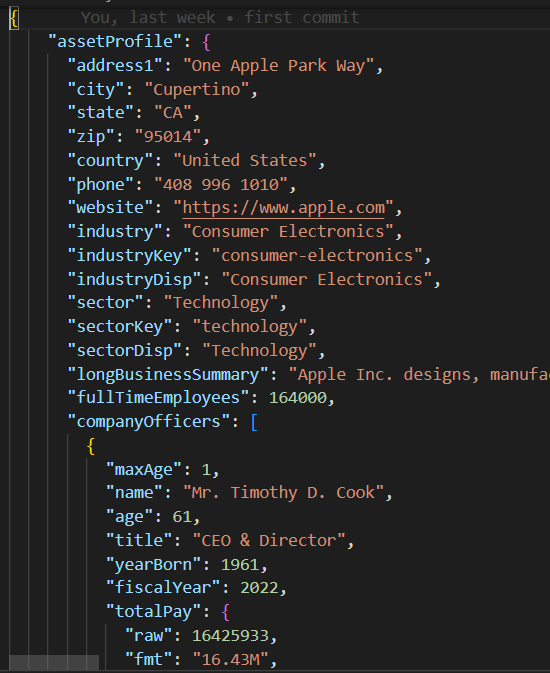
الفصل الأساسي/الأصلي في base_db.py يُنفذ مخطط الاختبار المنطقي لتنفيذ 10 خيوط متوازية لإنشاء وقراءة 200 سجل.
#imports
.....
class BaseDB:
def __init__(self, file_name='instrument.json', threads=10, records=20):
...................................
def execute(self):
create_threads = []
for i in range(self.num_threads):
thread = threading.Thread(
target=self.create_records, args=(i,))
create_threads.append(thread)
thread.start()
for thread in create_threads:
thread.join()
read_threads = []
for i in range(self.num_threads):
thread = threading.Thread(target=self.read_records, args=(i,))
read_threads.append(thread)
thread.start()
for thread in read_threads:
thread.join()
self.print_stats()
كل خيط ينفذ الروتين الكتابي/القراءة في create_records و read_records على التوالي. لاحظ أن هذه الوظائف لا تشمل أي منطق محدد لقاعدة البيانات، بل تقيس أداء كل عملية قراءة وكتابة.
def create_records(self, thread_id):
for i in range(1, self.num_records + 1):
key = int(thread_id * 100 + i)
start_time = time.time()
self.create_record(key)
end_time = time.time()
execution_time = end_time - start_time
self.performance_data[key] = {'Create Time': execution_time}
def read_records(self, thread_id):
for key in self.performance_data.keys():
start_time = time.time()
self.read_record(key)
end_time = time.time()
execution_time = end_time - start_time
self.performance_data[key]['Read Time'] = execution_timeبمجرد تنفيذ الاختبار، تقوم الدالة print_stats بطباعة مقاييس التنفيذ مثل متوسط القراءة/الكتابة وقيم الانحراف المعياري (stdev)، التي تشير إلى أداء واستقرار قراءة/كتابة قاعدة البيانات (قيمة stdev أصغر تعني تنفيذ أكثر استقرارًا).
def print_stats(self):
if len(self.performance_data) > 0:
# إنشاء جدول Pandas DataFrame من بيانات الأداء
df = pd.DataFrame.from_dict(self.performance_data, orient='index')
if not df.empty:
df.sort_index(inplace=True)
# حساب المتوسط والانحراف المعياري لكل عمود
create_mean = statistics.mean(df['Create Time'])
read_mean = statistics.mean(df['Read Time'])
create_stdev = statistics.stdev(df['Create Time'])
read_stdev = statistics.stdev(df['Read Time'])
print("Performance Data:")
print(df)
print(f"Create Time mean: {create_mean}, stdev: {create_stdev}")
print(f"Read Time mean: {read_mean}, stdev: {read_stdev}")
كود NoSQL
على عكس قواعد البيانات العلائقية التي تدعم SQL القياسي، لكل قاعدة بيانات NoSQL مكتبة SDK خاصة بها. تحتاج فئات اختبار الطفل لكل قاعدة بيانات NoSQL فقط إلى تنفيذ مُنشئ ووظائف create_record/read_recod تحتوي على مكتبة SDK الموروثة لقاعدة البيانات لتهيئة اتصال بقاعدة البيانات وإنشاء/قراءة السجلات في عدد قليل من الأسطر.
اختبار DynamoDB
import boto3
from base_db import BaseDB
class DynamoDB (BaseDB):
def __init__(self, file_name='instrument.json', threads=10, records=20):
super().__init__(file_name, threads, records)
dynamodb = boto3.resource('dynamodb', region_name='us-east-1')
table_name = 'Instruments'
self.table = dynamodb.Table(table_name)
def create_record(self, key):
item = {
'key': key,
'data': self.json_data
}
self.table.put_item(Item=item)
def read_record(self, key):
self.table.get_item(Key={'key': key})
if __name__ == "__main__":
DynamoDB().execute()إعداد AWS
لتنفيذ هذه الاختبارات الأداء في حساب AWS، يجب اتباع هذه الخطوات:
- إنشاء دور IAM لـ EC2 بأذونات للوصول إلى الخدمات المطلوبة في AWS.
- إطلاق مثيل EC2 وتعيين الدور الجديد الذي تم إنشاؤه.
- إنشاء مثيل لكل قاعدة بيانات NoSQL.
دور IAM
جدول DynamoDB
فضاء مفتاح Cassandra/جدول

يرجى ملاحظة أن مضيفات القواعد البيانات والبيانات الشخصية كانت مصنوعة يدويًا وتمت إزالتها في الوحدات mongo_db.py و redis_db.py وسوف تحتاج إلى تحديثها بإعدادات اتصال القاعدة البيانات المقابلة لحساب AWS الخاص بك. للاتصال بجدول DynamoDB و Cassandra، اخترت استخدام بطاقات جوجو الدخول المؤقتة إلى دور IAM db_performnace_iam_role. سيعمل هذا الرمز في أي حساب AWS في منطقة East 1 دون أي تعديل.
class CassandraDB(BaseDB):
def __init__(self, file_name='instrument.json', threads=10, records=20):
super().__init__(file_name=file_name, threads=threads, records=records)
self.json_data = json.dumps(
self.json_data, cls=DecimalEncoder).encode()
# إعدادات فضاءات المفاتيح في Cassandra
contact_points = ['cassandra.us-east-1.amazonaws.com']
keyspace_name = 'db_performance'
ssl_context = SSLContext(PROTOCOL_TLSv1_2)
ssl_context.load_verify_locations('sf-class2-root.crt')
ssl_context.verify_mode = CERT_REQUIRED
boto_session = boto3.Session(region_name="us-east-1")
auth_provider = SigV4AuthProvider(session=boto_session)
cluster = Cluster(contact_points, ssl_context=ssl_context, auth_provider=auth_provider,
port=9142)
self.session = cluster.connect(keyspace=keyspace_name)قم بالاتصال بوحدة التنفيذ EC2 (استخدمت مدير الجلسة)، وقم بتشغيل السكربت البرمجي الشكلي التالي لإجراء هذه المهام:
- تثبيت Git.
- تثبيت Pythion3.
- استنساخ مستودع GitHub performance_db.
- تثبيت وتنشيط بيئة Python3 الافتراضية.
- تثبيت المكتبات/التبعيات الثالثة.
- تنفيذ كل حالة إختبار.
sudo yum install git
sudo yum install python3
git clone https://github.com/dshilman/db_performance.git
sudo git pull
cd db_performance
python3 -m venv venv
source ./venv/bin/activate
sudo python3 -m pip install -r requirements.txt
cd code
sudo python3 -m dynamo_db
sudo python3 -m cassandra_db
sudo python3 -m redis_db
sudo python3 -m mongo_dbيجب أن ترى النتائج التالية للحالتين الإختباريتين الأوليين:
|
(venv) sh-5.2$ sudo python3 -m dynamo_db بيانات الأداء: زمن الإنشاء زمن القراءة 1 0.336909 0.031491 2 0.056884 0.053334 3 0.085881 0.031385 4 0.084940 0.050059 5 0.169012 0.050044 .. … … 916 0.047431 0.041877 917 0.043795 0.024649 918 0.075325 0.035251 919 0.101007 0.068767 920 0.103432 0.037742
[200 صفوف x 2 أعمدة] متوسط زمن الإنشاء: 0.0858926808834076, الانحراف المعياري: 0.07714510154026173 متوسط زمن القراءة: 0.04880355834960937, الانحراف المعياري: 0.028805479258627295 زمن التنفيذ: 11.499964714050293 |
(venv) sh-5.2$ sudo python3 -m cassandra_db بيانات الأداء: زمن الإنشاء زمن القراءة 1 0.024815 0.005986 2 0.008256 0.006927 3 0.008996 0.009810 4 0.005362 0.005892 5 0.010117 0.010308 .. … … 916 0.006234 0.008147 917 0.011564 0.004347 918 0.007857 0.008329 919 0.007260 0.007370 920 0.004654 0.006049
[200 صفوف x 2 أعمدة] متوسط وقت الإنشاء: 0.009145524501800537، الانحراف المعياري: 0.005201661271831082 متوسط وقت القراءة: 0.007248317003250122، الانحراف المعياري: 0.003557610695674452 وقت التنفيذ: 1.6279327869415283 |
نتائج الاختبار
| DynamoDB | Cassandra | MongoDB | Redis | |
|---|---|---|---|---|
| Create | mean: 0.0859 stdev: 0.0771 |
mean: 0.0091 stdev: 0.0052 |
mean: 0.0292 std: 0.0764 |
mean: 0.0028 stdev: 0.0049 |
| Read | mean: 0.0488 stdev: 0.0288 |
mean: 0.0072 stdev: 0.0036 |
mean: 0.0509 std: 0.0027 |
mean: 0.0012 stdev: 0.0016 |
| Exec Time | 11.45 sec | 1.6279 sec | 10.2608 sec | 0.3465 sec |
ملاحظاتي
- I was blown away by Cassandra’s fast performance. Cassandra support for SQL allows rich access pattern queries and AWS Keyspaces offer cross-region replication.
- I find DynamoDB’s performance disappointing despite the AWS hype about it. You should try to avoid the cross-partition table scan and thus must use an index for each data access pattern. DynamoDB global tables enable cross-region data replication.
- MongoDB يتمتع بـ SDK بسيط للغاية، ممتع في الاستخدام، ويقدم أفضل دعم لنوع بيانات JSON. يمكنك إنشاء المؤشرات وتنفيذ الاستعلامات المعقدة على سمات JSON متعددة الطبقات. مع ظهور تناظريات بيانات ثنائية جديدة، قد يفقد MongoDB جاذبيته.
- Redis يتمتع بأداء سريع بشكل مذهل، ومع ذلك، في نهاية المطاف، هو مخزن قيم/مفتاح حتى لو كان يدعم أنواع بيانات معقدة. يقدم Redis ميزات قوية مثل الأنابيب المزدوجة والبرمجة لتحسين معالجة الاستعلام بتمرير الكود إلى Redis لتنفيذه على الخادم.
الخلاصة
في الختام، اختيار قاعدة بيانات NoSQL المدارة من AWS لمنصة معلومات المؤسسة يعتمد على تفضيلاتك المحددة. إذا كان الأداء والتكرار عبر المناطق هما المصدر الأساسي للقلق، فإن AWS Cassandra يبرز نفسه كفائز واضح. يدمج DynamoDB بشكل جيد مع خدمات AWS الأخرى مثل Lambda وKinesis وبالتالي هو خيار رائع للهيكل المحلي لـ AWS أو بدون خوادم. للتطبيقات التي تتطلب دعم قوي لأنواع بيانات JSON، يتقدم MongoDB. ومع ذلك، إذا كانت تركيزك هو البحث السريع أو إدارة الجلسات للوصول العالي، يبرز Redis كخيار ممتاز. في نهاية المطاف، يجب أن يتماشى القرار مع متطلبات مؤسستك الفريدة.
كما هو الحال دائمًا، يمكنك العثور على الكود في مستودع GitHub المرتبط في وقت سابق في هذه المقالة (انظر مهمة السكربت البرمجي #3 أعلاه). لا تتردد في التواصل معي إذا كنت بحاجة إلى مساعدة في تشغيل هذا الكود أو في إعداد AWS.
Source:
https://dzone.com/articles/aws-nosql-performance-lab-using-python