













Caso Clássico 1
Muitos profissionais de software carecem de conhecimento aprofundado sobre a lógica de raciocínio do TCP/IP, o que frequentemente leva à identificação equivocada de problemas como problemas misteriosos. Alguns são desencorajados pela complexidade da literatura de redes TCP/IP, enquanto outros são induzidos ao erro por detalhes confusos no Wireshark. Por exemplo, um DBA enfrentando problemas de desempenho pode interpretar erroneamente os dados de captura de pacotes no Wireshark, concluindo erroneamente que as retransmissões TCP são a causa.

Como a retransmissão é suspeitada, é essencial compreender sua natureza. A retransmissão envolve fundamentalmente a retransmissão por timeout. Para confirmar se a retransmissão é de fato a causa, as informações relacionadas ao tempo são necessárias, o que não é fornecido na captura de tela acima. Após solicitar uma nova captura de tela ao DBA, as informações de timestamp foram incluídas.

Ao analisar pacotes de rede, as informações de timestamp são cruciais para um raciocínio lógico preciso. Uma diferença de tempo na faixa de microssegundos entre dois pacotes duplicados sugere uma retransmissão por timeout ou uma captura de pacote duplicado. Em um ambiente LAN típico com um tempo de ida e volta (RTT) de cerca de 100 microssegundos, onde as retransmissões TCP exigem pelo menos um RTT, uma retransmissão ocorrendo em apenas 1/100 do RTT provavelmente indica uma captura de pacote duplicado em vez de uma retransmissão por timeout real.
Caso Clássico 2
Outro caso clássico ilustra a importância do raciocínio lógico na análise de problemas de rede.
Um dia, um desenvolvedor de negócios veio correndo, dizendo que um script agendado usando o middleware de banco de dados MySQL havia falhado nas primeiras horas da manhã sem resposta. Ao ouvir sobre o problema, verifiquei os logs de erro do middleware de banco de dados MySQL, mas não encontrei pistas valiosas. Então, perguntei aos desenvolvedores se podiam reproduzir o problema, sabendo que, uma vez reproduzível, um problema se torna mais fácil de resolver.
Os desenvolvedores tentaram várias vezes reproduzir o problema, mas não tiveram sucesso. No entanto, fizeram uma nova descoberta: descobriram que a execução das mesmas consultas SQL durante o dia resultava em tempos de resposta diferentes em comparação com as primeiras horas da manhã. Eles suspeitaram que, quando a resposta SQL era lenta, o middleware de banco de dados MySQL estava bloqueando a sessão e não retornando resultados ao cliente.
Com base nessa percepção, a equipe de operações de banco de dados foi solicitada a modificar o SQL do script para simular uma resposta SQL lenta. Como resultado, o middleware de banco de dados MySQL retornou os resultados sem encontrar o problema de travamento observado nas primeiras horas da manhã.
Por um tempo, a causa raiz não pôde ser identificada, e os desenvolvedores descobriram um problema funcional com o middleware de banco de dados MySQL. Portanto, os desenvolvedores e as operações DBA se tornaram mais convencidos de que o middleware de banco de dados MySQL estava atrasando as respostas. Na realidade, esses problemas não estavam relacionados aos tempos de resposta do middleware de banco de dados MySQL.
Com os eventos do primeiro dia, o problema realmente ocorreu. Todos os envolvidos tentaram identificar a causa, fazendo várias suposições, mas a verdadeira razão permaneceu elusiva.
No dia seguinte, os desenvolvedores relataram que o problema do script reapareceu na madrugada, mas não conseguiram reproduzi-lo durante o dia. Os desenvolvedores, sentindo-se pressionados já que o script em breve seria usado online, reclamaram da situação. Minha única sugestão foi que eles usassem o script durante o dia para evitar problemas na madrugada. Com todas as suspeitas focadas no middleware do banco de dados MySQL, foi desafiador analisar o problema de outras perspectivas.
Como desenvolvedor responsável pelo middleware do banco de dados MySQL, problemas tão misteriosos não podem ser facilmente ignorados. Ignorá-los poderia impactar o uso subsequente do middleware do banco de dados MySQL, e também há pressão da liderança para resolver o problema rapidamente. Finalmente, decidiu-se implementar uma solução de análise de captura de pacotes de baixo custo: durante a execução do script na madrugada, capturas de pacotes seriam realizadas no servidor para analisar o que estava acontecendo naquele momento. O objetivo era determinar se o middleware do banco de dados MySQL não enviou uma resposta ou se enviou uma resposta que o script cliente não recebeu. Uma vez confirmado que o middleware do banco de dados MySQL enviou uma resposta, o problema não seria atribuído aos desenvolvedores do middleware do banco de dados MySQL.
No terceiro dia, os desenvolvedores relataram que o problema da manhã cedo não se repetiu, e a análise da captura de pacotes confirmou que o problema não ocorreu. Após cuidadosa consideração, parecia improvável que o problema estivesse apenas com o middleware do banco de dados MySQL: ocorrências frequentes na manhã cedo e raras durante o dia eram intrigantes. A única ação a ser tomada era esperar que o problema ocorresse novamente e analisá-lo com base nas capturas de pacotes.
No quarto dia, o problema não apareceu novamente.
No entanto, no quinto dia, o problema finalmente reapareceu, trazendo esperança de resolução.
Os arquivos de captura de pacotes são numerosos. Primeiro, peça aos desenvolvedores que forneçam o timestamp quando o problema ocorreu, depois pesquise nos extensos dados de captura de pacotes para identificar a consulta SQL que causou o problema. O resultado final é o seguinte:
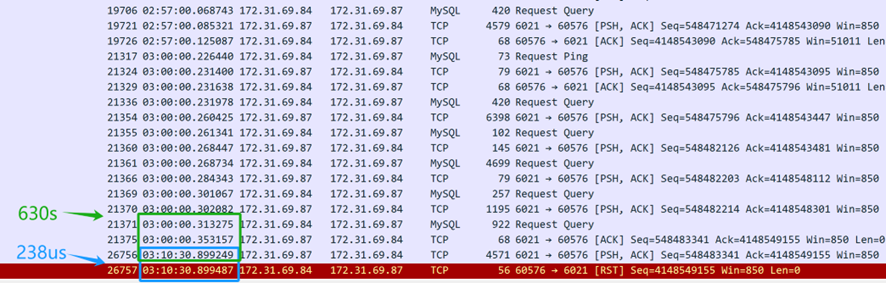
A partir do conteúdo da captura de pacotes acima (capturado do servidor), parece que a consulta SQL foi enviada às 3 da manhã. O middleware do banco de dados MySQL levou 630 segundos (03:10:30.899249-03:00:00.353157) para retornar a resposta SQL ao cliente, indicando que o middleware do banco de dados MySQL realmente respondeu à consulta SQL. No entanto, apenas 238 microssegundos depois (03:10:30.899487-03:10:30.899249), a camada TCP do servidor recebeu um pacote de redefinição, o que foi suspeitosamente rápido. É importante notar que este pacote de redefinição não pode ser imediatamente assumido como vindo do cliente.
Primeiramente, é necessário confirmar quem enviou o pacote de reset — se foi enviado pelo cliente ou por um dispositivo intermediário ao longo do caminho. Uma vez que a captura de pacotes foi realizada apenas no lado do servidor, informações sobre a situação do pacote do cliente não estão disponíveis. Ao analisar os arquivos de captura de pacotes do lado do servidor e aplicar o raciocínio lógico, o objetivo é identificar a causa raiz do problema.
Se for feita a suposição de que o cliente enviou um reset, isso implicaria que a camada TCP do cliente não reconhece mais o estado TCP desta conexão — passando de um estado estabelecido para um inexistente. Essa mudança de estado TCP notificaria a aplicação do cliente de um problema de conexão, fazendo com que o script do cliente apresente imediatamente um erro. No entanto, na realidade, o script do cliente ainda está aguardando o retorno da resposta. Portanto, a suposição de que o cliente enviou um reset não é verdadeira — o cliente não enviou um reset. A conexão do cliente ainda está ativa, mas no lado do servidor, a conexão correspondente foi encerrada pelo reset.
Quem enviou o reset, então? O principal suspeito é o ambiente de nuvem da Amazon. Com base nessa análise de captura de pacotes, as operações do DBA consultaram o serviço de atendimento ao cliente da Amazon e receberam as seguintes informações:
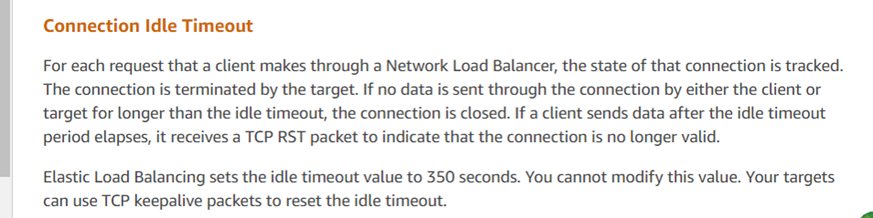
A resposta do serviço de atendimento ao cliente está alinhada com os resultados da análise, indicando que o ELB da Amazon (Balanceador de Carga Elástico, semelhante ao LVS) encerrou a sessão TCP de forma forçada. De acordo com o feedback deles, se uma resposta exceder o limite de 350 segundos (como observado na captura de pacotes como 630 segundos), o dispositivo ELB da Amazon envia um reset para a parte que responde (neste caso, o servidor). Os scripts do cliente desenvolvidos pelos programadores não receberam o reset e erroneamente assumiram que a conexão com o servidor ainda estava ativa. As recomendações oficiais para esses problemas incluem o uso de mecanismos de TCP keepalive para mitigar esses problemas.
Com a resposta oficial obtida, o problema foi considerado totalmente resolvido.
Este caso específico ilustra como os problemas online podem ser altamente complexos, exigindo a captura de informações críticas — neste caso, dados de captura de pacotes — para entender a situação conforme ocorreu. Através do raciocínio lógico e da aplicação do reductio ad absurdum, a causa raiz foi identificada.
Source:
https://dzone.com/articles/logical-reasoning-in-network-problems