













Brazilian Portuguese
Neste tutorial, aprenderemos sobre a função de ativação sigmoide. A função sigmoide sempre retorna uma saída entre 0 e 1.
Após este tutorial, você saberá:
- O que é uma função de ativação?
- Como implementar a função sigmoide em Python?
- Como plotar a função sigmoide em Python?
- Onde usamos a função sigmoide?
- Quais são os problemas causados pela função de ativação sigmoide?
- Melhores alternativas para a ativação sigmoide.
O que é uma função de ativação?
Uma função de ativação é uma função matemática que controla a saída de uma rede neural. Funções de ativação ajudam a determinar se um neurônio deve ser ativado ou não.
Algumas das funções de ativação populares são:
- Passo Binário
- Linear
- Sigmoide
- Tanh
- ReLU
- Leaky ReLU
- Softmax
A ativação é responsável por adicionar não-linearidade à saída de um modelo de rede neural. Sem uma função de ativação, uma rede neural é simplesmente uma regressão linear.
A equação matemática para calcular a saída de uma rede neural é:
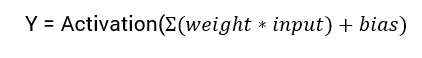
Neste tutorial, vamos focar na função de ativação sigmoidal. Esta função deriva da função sigmoide na matemática.
Vamos começar discutindo a fórmula da função.
A fórmula para a função de ativação sigmoidal
Matematicamente, você pode representar a função de ativação sigmoidal como:
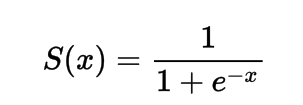
Você pode perceber que o denominador será sempre maior que 1, portanto, a saída estará sempre entre 0 e 1.
Implementando a Função de Ativação Sigmoidal em Python
Nesta seção, aprenderemos como implementar a função de ativação sigmoidal em Python.
Podemos definir a função em python da seguinte forma:
import numpy as np
def sig(x):
return 1/(1 + np.exp(-x))
Vamos tentar executar a função com alguns inputs.
import numpy as np
def sig(x):
return 1/(1 + np.exp(-x))
x = 1.0
print('Applying Sigmoid Activation on (%.1f) gives %.1f' % (x, sig(x)))
x = -10.0
print('Applying Sigmoid Activation on (%.1f) gives %.1f' % (x, sig(x)))
x = 0.0
print('Applying Sigmoid Activation on (%.1f) gives %.1f' % (x, sig(x)))
x = 15.0
print('Applying Sigmoid Activation on (%.1f) gives %.1f' % (x, sig(x)))
x = -2.0
print('Applying Sigmoid Activation on (%.1f) gives %.1f' % (x, sig(x)))
Saída :
Applying Sigmoid Activation on (1.0) gives 0.7
Applying Sigmoid Activation on (-10.0) gives 0.0
Applying Sigmoid Activation on (0.0) gives 0.5
Applying Sigmoid Activation on (15.0) gives 1.0
Applying Sigmoid Activation on (-2.0) gives 0.1
Plotando a Ativação Sigmoidal usando Python
Para traçar a ativação sigmoide, usaremos a biblioteca Numpy:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 50)
p = sig(x)
plt.xlabel("x")
plt.ylabel("Sigmoid(x)")
plt.plot(x, p)
plt.show()
Saída :
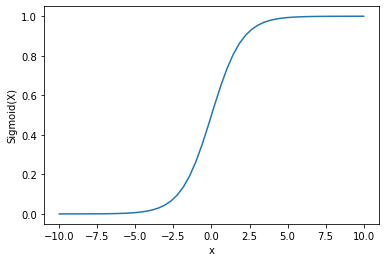
Podemos ver que a saída está entre 0 e 1.
A função sigmoide é comumente usada para prever probabilidades, uma vez que a probabilidade está sempre entre 0 e 1.
Uma das desvantagens da função sigmoide é que nas regiões finais os valores de Y respondem muito pouco às mudanças nos valores de X.
Isso resulta em um problema conhecido como o problema do gradiente desvanecente.
O gradiente desvanecente retarda o processo de aprendizado e, portanto, é indesejável.
Vamos discutir algumas alternativas que superam esse problema.
Função de ativação ReLu
A better alternative that solves this problem of vanishing gradient is the ReLu activation function.
A função de ativação ReLu retorna 0 se a entrada for negativa, caso contrário, retorna a entrada como está.
Matematicamente, é representada como:
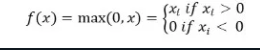
Você pode implementá-la em Python da seguinte forma:
def relu(x):
return max(0.0, x)
Vamos ver como ela funciona em algumas entradas.
def relu(x):
return max(0.0, x)
x = 1.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = -10.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = 0.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = 15.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = -20.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
Saída:
Applying Relu on (1.0) gives 1.0
Applying Relu on (-10.0) gives 0.0
Applying Relu on (0.0) gives 0.0
Applying Relu on (15.0) gives 15.0
Applying Relu on (-20.0) gives 0.0
O problema com ReLu é que o gradiente para entradas negativas é zero.
Isso novamente leva ao problema do gradiente desvanecente (gradiente zero) para entradas negativas.
Para resolver este problema, temos outra alternativa conhecida como a função de ativação Leaky ReLu.
Função de ativação Leaky ReLu
A Leaky ReLu aborda o problema dos gradientes zero para valores negativos, dando um componente linear extremamente pequeno de x para entradas negativas.
Matematicamente, podemos defini-la como:
f(x)= 0.01x, x<0
= x, x>=0
Você pode implementá-la em Python usando:
def leaky_relu(x):
if x>0 :
return x
else :
return 0.01*x
x = 1.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = -10.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = 0.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = 15.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = -20.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
Saída:
Applying Leaky Relu on (1.0) gives 1.0
Applying Leaky Relu on (-10.0) gives -0.1
Applying Leaky Relu on (0.0) gives 0.0
Applying Leaky Relu on (15.0) gives 15.0
Applying Leaky Relu on (-20.0) gives -0.2
Conclusão
Este tutorial abordou a função de ativação Sigmoid. Aprendemos como implementar e plotar a função em Python.
Source:
https://www.digitalocean.com/community/tutorials/sigmoid-activation-function-python