













De auteur heeft het Free and Open Source Fund geselecteerd om een donatie te ontvangen als onderdeel van het Write for DOnations-programma.
Inleiding
Database monitoring is het continue proces van systematisch volgen van verschillende metingen die laten zien hoe de database presteert. Door prestatiegegevens te observeren, kunt u waardevolle inzichten krijgen en mogelijke knelpunten identificeren, evenals aanvullende manieren vinden om de prestaties van de database te verbeteren. Dergelijke systemen implementeren vaak waarschuwingen die beheerders op de hoogte stellen wanneer er iets misgaat. Verzamelde statistieken kunnen worden gebruikt om niet alleen de configuratie en workflow van de database te verbeteren, maar ook die van clientapplicaties.
Het voordeel van het gebruik van de Elastic Stack (ELK stack) voor het monitoren van uw beheerde database is de uitstekende ondersteuning voor zoeken en het vermogen om nieuwe gegevens zeer snel in te nemen. Het blinkt niet uit in het bijwerken van de gegevens, maar deze afweging is acceptabel voor monitoring- en logdoeleinden, waarbij verleden gegevens vrijwel nooit worden gewijzigd. Elasticsearch biedt een krachtige manier om de gegevens te bevragen, die u kunt gebruiken via Kibana om een beter inzicht te krijgen in hoe de database presteert in verschillende tijdsperioden. Dit stelt u in staat om de databasebelasting te correleren met gebeurtenissen in het echte leven om inzicht te krijgen in hoe de database wordt gebruikt.
In deze tutorial importeert u databasemetrics, gegenereerd door het Redis INFO commando, in Elasticsearch via Logstash. Dit omvat het configureren van Logstash om periodiek het commando uit te voeren, de uitvoer te parsen en deze direct daarna naar Elasticsearch te sturen voor indexering. De geïmporteerde gegevens kunnen later worden geanalyseerd en gevisualiseerd in Kibana. Tegen het einde van de tutorial hebt u een geautomatiseerd systeem dat Redis-statistieken binnenhaalt voor latere analyse.
Vereisten
- Een Ubuntu 18.04 server met minimaal 8 GB RAM, rootprivileges en een secundair, niet-root account. Dit kun je instellen door de handleiding voor de initiële serverconfiguratie te volgen. Voor deze tutorial is de niet-root gebruiker
sammy. - Java 8 geïnstalleerd op je server. Voor installatie-instructies, bezoek Hoe Java te installeren met
aptop Ubuntu 18.04 en volg de commando’s zoals beschreven in de eerste stap. Je hoeft de Java Development Kit (JDK) niet te installeren. - Nginx geïnstalleerd op je server. Voor een handleiding hierover, zie de Handleiding voor het installeren van Nginx op Ubuntu 18.04.
- Elasticsearch en Kibana geïnstalleerd op je server. Voltooi de eerste twee stappen van de Handleiding voor het installeren van Elasticsearch, Logstash en Kibana (Elastic Stack) op Ubuntu 18.04.
- A Redis managed database provisioned from DigitalOcean with connection information available. Make sure that your server’s IP address is on the whitelist. For a guide on creating a Redis database using the DigitalOcean Control Panel, visit the Redis Quickstart guide.
- Redli geïnstalleerd op je server volgens de Handleiding voor het verbinden met een beheerde database op Ubuntu 18.04.
Stap 1 — Installeren en configureren van Logstash
In deze sectie installeer je Logstash en configureer je het om statistieken op te halen uit je Redis-databasecluster, en vervolgens parseer je ze om naar Elasticsearch te sturen voor indexering.
Begin met het installeren van Logstash met het volgende commando:
Zodra Logstash is geïnstalleerd, activeer de service dan om automatisch op te starten bij het opstarten:
Voordat je Logstash configureert om de statistieken op te halen, laten we eens kijken naar hoe de gegevens er zelf uitzien. Om verbinding te maken met je Redis-database, ga je naar je Beheerde Databasebeheerpaneel en onder het paneel Verbindingsgegevens selecteer je Vlaggen uit het dropdownmenu:
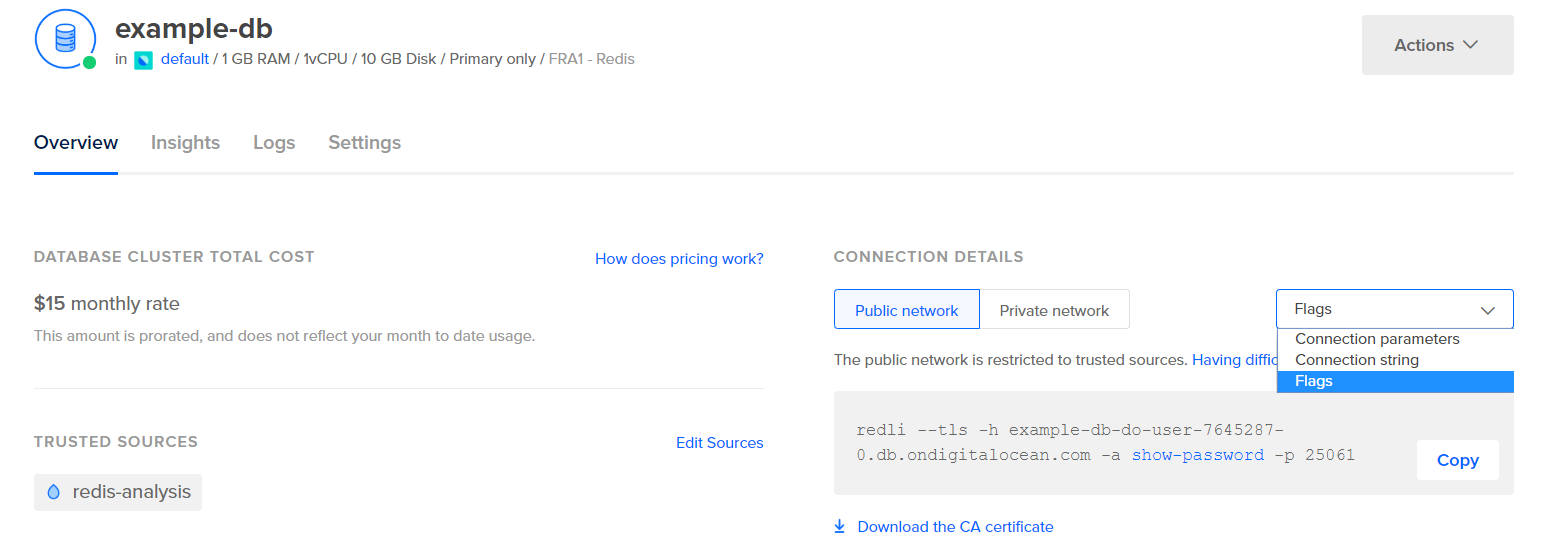
Je krijgt een vooraf geconfigureerd commando te zien voor de Redli-client, die je zult gebruiken om verbinding te maken met je database. Klik op Kopiëren en voer het volgende commando uit op je server, waarbij je redli_flags_command vervangt door het commando dat je zojuist hebt gekopieerd:
Aangezien de uitvoer van dit commando lang is, zullen we dit uitleggen in verschillende delen.
In de uitvoer van het Redis info-commando worden secties gemarkeerd met #, wat een opmerking aangeeft. De waarden worden ingevuld in de vorm van key:value, wat ze relatief eenvoudig te parseren maakt.
De Server sectie bevat technische informatie over de Redis build, zoals de versie en de Git commit waarop het is gebaseerd, terwijl de Clients sectie het aantal momenteel geopende verbindingen geeft.
Output# Server
redis_version:6.2.6
redis_git_sha1:4f4e829a
redis_git_dirty:1
redis_build_id:5861572cb79aebf3
redis_mode:standalone
os:Linux 5.11.12-300.fc34.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:11.2.1
process_id:79
process_supervised:systemd
run_id:b8a0aa25d8f49a879112a04a817ac2acd92e0c75
tcp_port:25060
server_time_usec:1640878632737564
uptime_in_seconds:1679
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:13488680
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
io_threads_active:0
# Clients
connected_clients:4
cluster_connections:0
maxclients:10032
client_recent_max_input_buffer:24
client_recent_max_output_buffer:0
...
Memory bevestigt hoeveel RAM Redis heeft toegewezen voor zichzelf, evenals de maximale hoeveelheid geheugen die het mogelijk kan gebruiken. Als het bijna geen geheugen meer heeft, zal het sleutels vrijmaken met behulp van de strategie die u heeft gespecificeerd in het Configuratiescherm (weergegeven in het maxmemory_policy veld in deze uitvoer).
Output...
# Memory
used_memory:977696
used_memory_human:954.78K
used_memory_rss:9977856
used_memory_rss_human:9.52M
used_memory_peak:977696
used_memory_peak_human:954.78K
used_memory_peak_perc:100.00%
used_memory_overhead:871632
used_memory_startup:810128
used_memory_dataset:106064
used_memory_dataset_perc:63.30%
allocator_allocated:947216
allocator_active:1273856
allocator_resident:3510272
total_system_memory:1017667584
total_system_memory_human:970.52M
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:455081984
maxmemory_human:434.00M
maxmemory_policy:noeviction
allocator_frag_ratio:1.34
allocator_frag_bytes:326640
allocator_rss_ratio:2.76
allocator_rss_bytes:2236416
rss_overhead_ratio:2.84
rss_overhead_bytes:6467584
mem_fragmentation_ratio:11.43
mem_fragmentation_bytes:9104832
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:61504
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
...
In de Persistence sectie kunt u zien wanneer Redis voor het laatst de sleutels die het opslaat naar schijf heeft opgeslagen, en of dit succesvol was. De Stats sectie biedt cijfers met betrekking tot client- en in-clusterverbindingen, het aantal keren dat de gevraagde sleutel wel of niet is gevonden, enzovoort.
Output...
# Persistence
loading:0
current_cow_size:0
current_cow_size_age:0
current_fork_perc:0.00
current_save_keys_processed:0
current_save_keys_total:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1640876954
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:217088
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
module_fork_in_progress:0
module_fork_last_cow_size:0
# Stats
total_connections_received:202
total_commands_processed:2290
instantaneous_ops_per_sec:0
total_net_input_bytes:38034
total_net_output_bytes:1103968
instantaneous_input_kbps:0.01
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:29
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:452
total_forks:1
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
total_error_replies:0
dump_payload_sanitizations:0
total_reads_processed:2489
total_writes_processed:2290
io_threaded_reads_processed:0
io_threaded_writes_processed:0
...
Door te kijken naar de role onder Replication, weet u of u verbonden bent met een primaire of replica-node. De rest van de sectie geeft het aantal momenteel verbonden replica’s en de hoeveelheid gegevens aan die de replica mist ten opzichte van de primaire. Er kunnen aanvullende velden zijn als de instantie waarmee u verbonden bent een replica is.
Opmerking: Het Redis-project gebruikt de termen “master” en “slave” in zijn documentatie en in verschillende commando’s. DigitalOcean geeft over het algemeen de voorkeur aan de alternatieve termen “primary” en “replica”. Deze handleiding zal standaard de termen “primary” en “replica” gebruiken waar mogelijk, maar merk op dat er enkele gevallen zijn waarin de termen “master” en “slave” onvermijdelijk ter sprake komen.
Output...
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:f727fad3691f2a8d8e593b087c468bbb83703af3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:45088768
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
...
Onder CPU zie je de hoeveelheid systeem (used_cpu_sys) en gebruiker (used_cpu_user) CPU-kracht die Redis op dit moment verbruikt. Het Cluster-gedeelte bevat slechts één uniek veld, cluster_enabled, dat aangeeft dat de Redis-cluster actief is.
Output...
# CPU
used_cpu_sys:1.617986
used_cpu_user:1.248422
used_cpu_sys_children:0.000000
used_cpu_user_children:0.001459
used_cpu_sys_main_thread:1.567638
used_cpu_user_main_thread:1.218768
# Modules
# Foutstatistieken
# Cluster
cluster_enabled:0
# Keyspace
Logstash zal worden belast met periodiek het info-commando uit te voeren op uw Redis-database (vergelijkbaar met hoe u zojuist hebt gedaan), de resultaten te parseren en ze naar Elasticsearch te sturen. Vervolgens kunt u ze later openen vanuit Kibana.
U slaat de configuratie voor het indexeren van Redis-statistieken in Elasticsearch op in een bestand met de naam redis.conf onder de /etc/logstash/conf.d-directory, waar Logstash configuratiebestanden opslaat. Wanneer het als service wordt gestart, wordt het automatisch op de achtergrond uitgevoerd.
Maak redis.conf met behulp van uw favoriete editor (bijvoorbeeld nano):
Voeg de volgende regels toe:
input {
exec {
command => "redis_flags_command info"
interval => 10
type => "redis_info"
}
}
filter {
kv {
value_split => ":"
field_split => "\r\n"
remove_field => [ "command", "message" ]
}
ruby {
code =>
"
event.to_hash.keys.each { |k|
if event.get(k).to_i.to_s == event.get(k) # is integer?
event.set(k, event.get(k).to_i) # convert to integer
end
if event.get(k).to_f.to_s == event.get(k) # is float?
event.set(k, event.get(k).to_f) # convert to float
end
}
puts 'Ruby filter finished'
"
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "%{type}"
}
}
Vergeet niet om redis_flags_command te vervangen door het commando dat wordt weergegeven in het bedieningspaneel dat u eerder in de stap hebt gebruikt.
U definieert een input, die een set filters is die zullen worden uitgevoerd op de verzamelde gegevens, en een output die de gefilterde gegevens naar Elasticsearch zal sturen. De input bestaat uit het exec-commando, dat periodiek een command op de server zal uitvoeren, na een ingestelde tijd interval (uitgedrukt in seconden). Het specificeert ook een type-parameter die het documenttype bepaalt bij indexering in Elasticsearch. Het exec-blok geeft een object door met twee velden, command en message string. Het veld command bevat het uitgevoerde commando en het veld message bevat de uitvoer ervan.
Er zijn twee filters die achtereenvolgens worden uitgevoerd op de verzamelde gegevens van de input. Het kv-filter staat voor sleutel-waarde filter en is ingebouwd in Logstash. Het wordt gebruikt voor het parsen van gegevens in de algemene vorm van sleutelwaarde_scheiderw aarde en biedt parameters om aan te geven wat als waarde- en veldscheiders worden beschouwd. De veldscheider heeft betrekking op strings die de gegevens opgemaakt in de algemene vorm van elkaar scheiden. In het geval van de uitvoer van het Redis INFO-commando is de veldscheider (veld_scheider) een nieuwe regel en de waarde scheider (w aarde_scheider) is :. Regels die niet voldoen aan de gedefinieerde vorm zullen worden verworpen, inclusief opmerkingen.
Om de kv-filter te configureren, geef je : door aan de value_split-parameter en \r\n (wat een nieuwe regel aanduidt) aan de field_split-parameter. Je geeft ook opdracht om de velden command en message uit het huidige gegevensobject te verwijderen door ze door te geven aan remove_field als elementen van een array, omdat ze gegevens bevatten die nu nutteloos zijn.
De kv-filter geeft de waarde die het heeft geanalyseerd als een tekenreeks (tekst) type opzettelijk weer. Dit veroorzaakt een probleem omdat Kibana stringtypes niet gemakkelijk kan verwerken, zelfs als het eigenlijk een nummer is. Om dit op te lossen, zul je aangepaste Ruby-code gebruiken om de nummer-alleen-strings om te zetten naar nummers, indien mogelijk. De tweede filter is een ruby-blok dat een code-parameter biedt die een tekenreeks accepteert die de uit te voeren code bevat.
event is een variabele die Logstash aan je code geeft, en bevat de huidige gegevens in de filterpipeline. Zoals eerder opgemerkt, worden filters na elkaar uitgevoerd, wat betekent dat het Ruby-filter de geparseerde gegevens van de kv-filter ontvangt. De Ruby-code zelf zet het event om naar een hash en doorloopt de sleutels, controleert vervolgens of de waarde die is geassocieerd met de sleutel kan worden gerepresenteerd als een geheel getal of als een float (een nummer met decimalen). Als dat kan, wordt de tekenreekswaarde vervangen door het geparseerde nummer. Wanneer de lus eindigt, wordt een bericht afgedrukt (Ruby filter finished) om de voortgang te rapporteren.
De uitvoer stuurt de verwerkte gegevens naar Elasticsearch voor indexering. Het resulterende document wordt opgeslagen in de redis_info index, gedefinieerd in de invoer en doorgegeven als een parameter aan het uitvoerblok.
Sla het bestand op en sluit het.
Je hebt Logstash geïnstalleerd met behulp van apt en geconfigureerd om periodiek statistieken op te vragen van Redis, deze te verwerken en naar je Elasticsearch-instantie te sturen.
Stap 2 — Testen van de Logstash-configuratie
Nu ga je de configuratie testen door Logstash uit te voeren om te controleren of het de gegevens correct zal ophalen.
Logstash ondersteunt het uitvoeren van een specifieke configuratie door het bestandspad door te geven aan de -f parameter. Voer het volgende commando uit om je nieuwe configuratie uit de vorige stap te testen:
Het kan even duren voordat de uitvoer wordt weergegeven, maar al snel zie je iets vergelijkbaars met het volgende:
OutputUsing bundled JDK: /usr/share/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[INFO ] 2021-12-30 15:42:08.887 [main] runner - Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
[INFO ] 2021-12-30 15:42:08.932 [main] settings - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
[INFO ] 2021-12-30 15:42:08.939 [main] settings - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
[WARN ] 2021-12-30 15:42:09.406 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2021-12-30 15:42:09.449 [LogStash::Runner] agent - No persistent UUID file found. Generating new UUID {:uuid=>"acc4c891-936b-4271-95de-7d41f4a41166", :path=>"/usr/share/logstash/data/uuid"}
[INFO ] 2021-12-30 15:42:10.985 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[INFO ] 2021-12-30 15:42:11.601 [Converge PipelineAction::Create<main>] Reflections - Reflections took 77 ms to scan 1 urls, producing 119 keys and 417 values
[WARN ] 2021-12-30 15:42:12.215 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.366 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.431 [Converge PipelineAction::Create<main>] elasticsearch - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:12.494 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2021-12-30 15:42:12.755 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2021-12-30 15:42:12.955 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2021-12-30 15:42:12.967 [[main]-pipeline-manager] elasticsearch - Elasticsearch version determined (7.16.2) {:es_version=>7}
[WARN ] 2021-12-30 15:42:12.968 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[WARN ] 2021-12-30 15:42:13.065 [[main]-pipeline-manager] kv - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:13.090 [Ruby-0-Thread-10: :1] elasticsearch - Using a default mapping template {:es_version=>7, :ecs_compatibility=>:disabled}
[INFO ] 2021-12-30 15:42:13.147 [Ruby-0-Thread-10: :1] elasticsearch - Installing Elasticsearch template {:name=>"logstash"}
[INFO ] 2021-12-30 15:42:13.192 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/etc/logstash/conf.d/redis.conf"], :thread=>"#<Thread:0x5104e975 run>"}
[INFO ] 2021-12-30 15:42:13.973 [[main]-pipeline-manager] javapipeline - Pipeline Java execution initialization time {"seconds"=>0.78}
[INFO ] 2021-12-30 15:42:13.983 [[main]-pipeline-manager] exec - Registering Exec Input {:type=>"redis_info", :command=>"redli --tls -h db-redis-fra1-68603-do-user-1446234-0.b.db.ondigitalocean.com -a hnpJxAgoH3Om3UwM -p 25061 info", :interval=>10, :schedule=>nil}
[INFO ] 2021-12-30 15:42:13.994 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
[INFO ] 2021-12-30 15:42:14.034 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
Ruby filter finished
Ruby filter finished
Ruby filter finished
...
Je ziet de boodschap Ruby-filter voltooid regelmatig worden afgedrukt (elke 10 seconden ingesteld in de vorige stap), wat betekent dat de statistieken worden verzonden naar Elasticsearch.
Je kunt Logstash afsluiten door op CTRL + C op je toetsenbord te klikken. Zoals eerder vermeld, zal Logstash automatisch alle configuratiebestanden uitvoeren die worden gevonden onder /etc/logstash/conf.d op de achtergrond wanneer het als een service wordt gestart. Voer het volgende commando uit om het te starten:
Je hebt Logstash uitgevoerd om te controleren of het verbinding kan maken met je Redis-cluster en gegevens kan verzamelen. Vervolgens zul je enkele van de statistische gegevens verkennen in Kibana.
Stap 3 — Verkennen van Geïmporteerde Gegevens in Kibana
In deze sectie zul je de statistische gegevens verkennen en visualiseren die de prestaties van je database beschrijven in Kibana.
Open in je webbrowser je domein waar je Kibana hebt blootgesteld als onderdeel van de vereisten. Je ziet de standaard welkomstpagina:
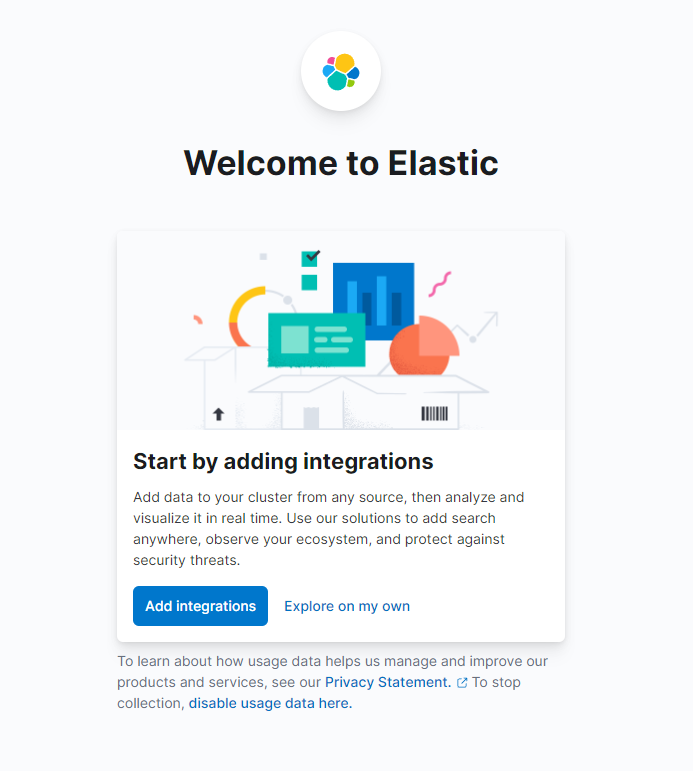
Voordat je de gegevens gaat verkennen die Logstash naar Elasticsearch stuurt, moet je eerst de redis_info-index toevoegen aan Kibana. Om dit te doen, selecteer eerst Verkennen op eigen houtje vanaf de welkomstpagina en open vervolgens het hamburgermenu in de linkerbovenhoek. Onder Analyse, klik op Ontdekken.
Kibana zal je dan vragen om een nieuw indexpatroon te maken:
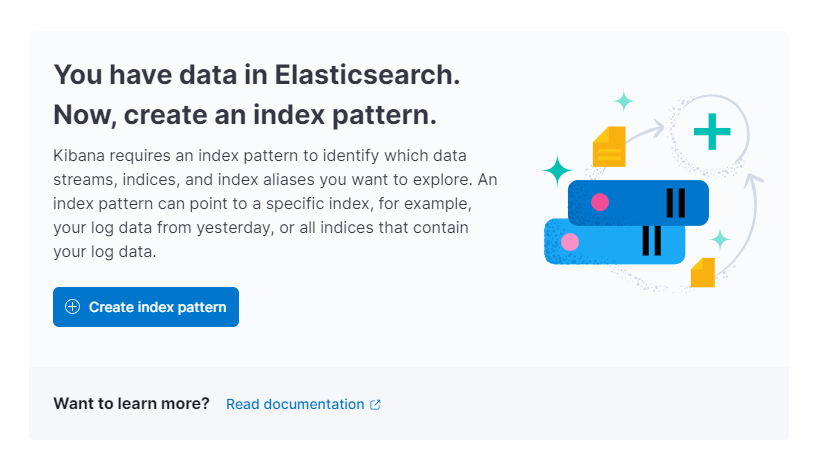
Druk op Indexpatroon maken. Je ziet dan een formulier voor het maken van een nieuw Indexpatroon. Indexpatronen in Kibana bieden een manier om gegevens uit meerdere Elasticsearch-indexen tegelijk te halen, en kunnen worden gebruikt om slechts één index te verkennen.

Aan de rechterkant geeft Kibana alle beschikbare indexen weer, zoals redis_info die je hebt geconfigureerd voor gebruik met Logstash. Typ het in het Naam tekstveld en selecteer @timestamp uit de dropdown als het Tijdstempelveld. Als je klaar bent, druk op de Maak indexpatroon aan knop hieronder.
Om visualisaties te maken en bestaande te bekijken, open het hamburgermenu. Onder Analyse, selecteer Dashboard. Wanneer het geladen is, druk op Maak visualisatie aan om een nieuwe te starten:
De linkerzijpaneel biedt een lijst van waarden die Kibana kan gebruiken om de visualisatie te tekenen, die op het centrale deel van het scherm wordt getoond. Aan de rechterbovenkant van het scherm bevindt zich de datumkiezer. Als het @timestamp veld wordt gebruikt in de visualisatie, zal Kibana alleen de gegevens tonen die behoren tot het tijdsinterval dat is gespecificeerd in de kiezer voor het bereik.
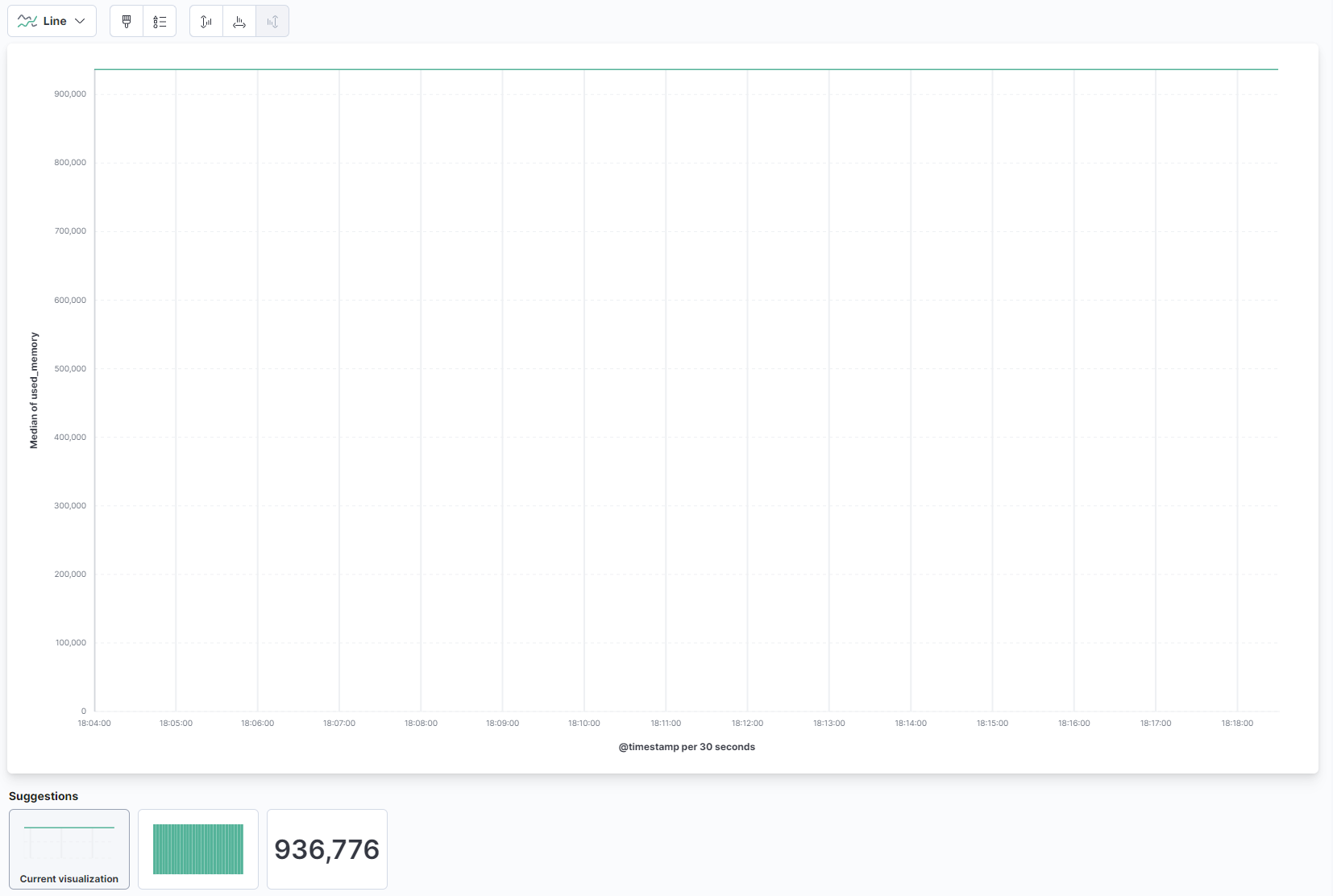
Selecteer vanuit de dropdown in het hoofddeel van de pagina Lijn onder de Lijn en gebied sectie. Vervolgens, vind het used_memory veld in de lijst aan de linkerkant en sleep het naar het centrale deel. Je zult snel een lijnvisualisatie zien van de mediane hoeveelheid gebruikte geheugen in de tijd:
Aan de rechterkant kun je configureren hoe de horizontale en verticale as worden verwerkt. Daar kun je de verticale as instellen om de gemiddelde waarden in plaats van de mediaan weer te geven door te drukken op de getoonde as:
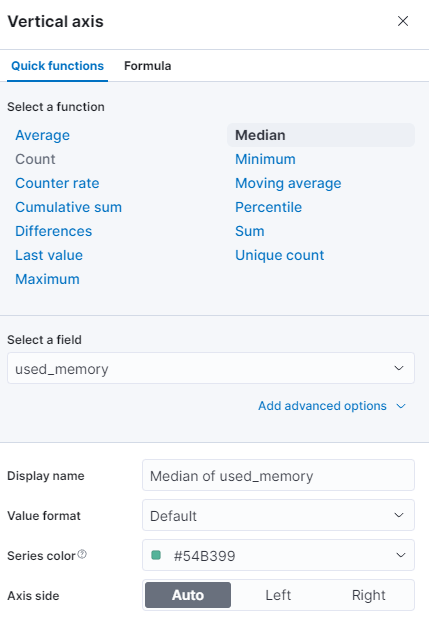
Je kunt een andere functie selecteren, of je eigen functie invoeren:
Het diagram wordt onmiddellijk vernieuwd met de bijgewerkte waarden.
In deze stap heb je het geheugengebruik van je beheerde Redis-database gevisualiseerd met behulp van Kibana. Dit zal je helpen een beter inzicht te krijgen in hoe je database wordt gebruikt, wat je zal helpen bij het optimaliseren van clienttoepassingen, evenals je database zelf.
Conclusie
Je hebt nu de Elastic-stack geïnstalleerd op je server en geconfigureerd om regelmatig statistische gegevens op te halen uit je beheerde Redis-database. Je kunt de gegevens analyseren en visualiseren met behulp van Kibana, of andere geschikte software, wat je zal helpen waardevolle inzichten te verzamelen en real-world correlaties over hoe je database presteert.
Voor meer informatie over wat je kunt doen met je beheerde Redis-database, bezoek de productdocumentatie. Als je de databasestatistieken wilt presenteren met behulp van een ander visualisatietype, bekijk dan de Kibana-documentatie voor verdere instructies.