













Big data is aanzienlijk geëvolueerd sinds de opkomst in het einde van de jaren 2000. Veel organisaties pasten zich snel aan de trend aan en bouwden hun big data-platforms met open-source tools zoals Apache Hadoop. Later begonnen deze bedrijven problemen te ondervinden bij het beheren van de snel evoluerende behoeften op het gebied van gegevensverwerking. Ze hebben uitdagingen ondervonden bij het omgaan met schemawijzigingen, evolutie van partitioneringsschema’s en het teruggaan in de tijd om naar de gegevens te kijken.
Ik ondervond vergelijkbare uitdagingen bij het ontwerpen van grootschalige gedistribueerde systemen in de jaren 2010 voor een groot technologiebedrijf en een klant uit de gezondheidszorg. Sommige industrieën hebben deze mogelijkheden nodig om te voldoen aan bank-, financiële en gezondheidszorgvoorschriften. Grote datagestuurde bedrijven zoals Netflix ondervonden ook vergelijkbare uitdagingen. Ze hebben een tabelindeling uitgevonden genaamd “Iceberg”, die bovenop de bestaande gegevensbestanden zit en belangrijke functies levert door gebruik te maken van zijn architectuur. Dit is snel het belangrijkste ASF-project geworden, omdat het snel belangstelling heeft gekregen in de datacommunity. In dit artikel zal ik de top 5 Apache Iceberg kernfuncties verkennen met voorbeelden en diagrammen.
1. Tijdreizen

Figuur 1: Tijdreizen in het Apache Iceberg tabelindeling (afbeelding gemaakt door auteur)
Deze functie stelt u in staat om uw gegevens op te vragen zoals ze op dat moment bestaan. Dit opent nieuwe mogelijkheden voor gegevens- en bedrijfsanalisten om trends te begrijpen en te zien hoe de gegevens in de loop van de tijd zijn geëvolueerd. U kunt moeiteloos teruggaan naar een eerdere staat in geval van fouten. Deze functie vergemakkelijkt ook auditcontroles door u in staat te stellen de gegevens op een specifiek tijdstip te analyseren.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. Schema-evolutie
De schema-evolutie van Apache Iceberg maakt wijzigingen in uw schema mogelijk zonder veel moeite of dure migraties. Naarmate uw zakelijke behoeften veranderen, kunt u:
- Kolommen toevoegen en verwijderen zonder downtime of tabelherschrijvingen.
- De kolom bijwerken (verbreden).
- De volgorde van kolommen wijzigen.
- Een bestaande kolom hernoemen.
Deze wijzigingen worden op metadataniveau afgehandeld zonder dat de onderliggende gegevens opnieuw moeten worden geschreven.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. Partitioneringsevolutie
Met het Apache Iceberg tabelformaat kunt u de tabelpartitioneringsstrategie wijzigen zonder de onderliggende tabel opnieuw te schrijven of de gegevens naar een nieuwe tabel te migreren. Dit is mogelijk omdat queries de partitiewaarden niet direct refereren zoals in Apache Hadoop. Iceberg houdt metadata-informatie voor elke partitieversie apart. Dit maakt het gemakkelijk om de splits te verkrijgen tijdens het opvragen van de gegevens. Bijvoorbeeld, het opvragen van een tabel op basis van het datumbereik, terwijl de tabel eerst de maand als een partitiekolom gebruikte (voorheen) als een split en de dag als een nieuwe partitiekolom (na) als een andere split. Dit wordt splitplanning genoemd. Zie het voorbeeld hieronder.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. ACID-transacties
Iceberg biedt robuuste ondersteuning voor transacties in termen van Atomiciteit, Consistentie, Isolatie en Duurzaamheid (ACID). Het staat meerdere gelijktijdige schrijfbewerkingen toe, wat een hoge doorvoer mogelijk maakt in zware data-intensieve taken zonder concessies te doen aan de dataconsistentie.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
Alle bewerkingen in Iceberg zijn transactioneel, wat betekent dat de gegevens consistent blijven ondanks fouten of wijzigingen in de gegevens die gelijktijdig plaatsvinden.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
Het ondersteunt ook verschillende isolatieniveaus, waardoor je prestaties en consistentie kunt afstemmen op basis van de vereisten.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
Hier is een samenvatting die laat zien hoe Iceberg rij-niveau updates en verwijderingen afhandelt.
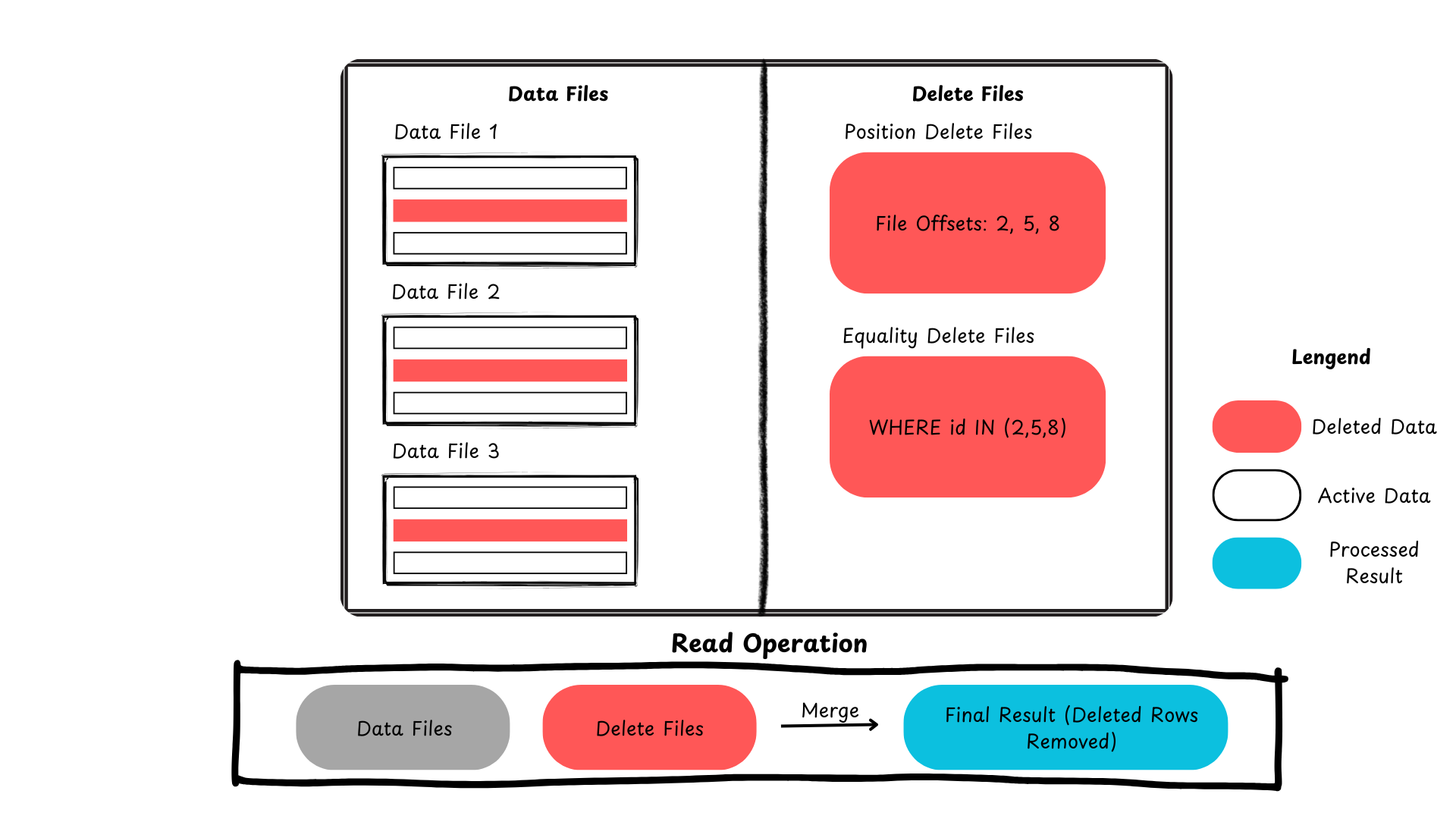
Figuur 2: Verwijderrecords proces in Apache Iceberg (afbeelding gemaakt door de auteur)
5. Geavanceerde Tabelbewerkingen
Iceberg ondersteunt geavanceerde tabelbewerkingen zoals:
- Tabel-snapshots maken/beheren: Dit biedt de mogelijkheid om robuuste versiecontrole te hebben.
- Snelle queryplanning en uitvoering met zijn sterk geoptimaliseerde metadata
- Ingebouwde tools voor tabelonderhoud, zoals compressie en opruimen van weesbestanden
Iceberg is ontworpen om te werken met alle belangrijke cloudopslag, zoals AWS S3, GCS en Azure Blob Storage. Ook integreert Iceberg eenvoudig met data-verwerkingsengines zoals Spark, Presto, Trino en Hive.
Slotgedachten
Deze gemarkeerde functies stellen bedrijven in staat om moderne, flexibele, schaalbare en efficiënte datalakes te bouwen, die kunnen tijdreizen, gemakkelijk omgaan met schema wijzigingen, ACID-transacties ondersteunen en partitie-evolutie.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes