













L’autore ha selezionato il Fondo per il Software Libero e Open Source per ricevere una donazione come parte del programma Scrivere per le Donazioni.
Introduzione
Il monitoraggio del database è il processo continuo di tracciamento sistematico di varie metriche che mostrano come il database si sta comportando. Osservando i dati sulle prestazioni, è possibile ottenere preziose informazioni e individuare possibili colli di bottiglia, oltre a trovare ulteriori modi per migliorare le prestazioni del database. Tali sistemi implementano spesso un sistema di allarme che avvisa gli amministratori quando le cose vanno storte. Le statistiche raccolte possono essere utilizzate non solo per migliorare la configurazione e il flusso di lavoro del database, ma anche quelli delle applicazioni client.
Il vantaggio dell’utilizzo dello stack Elastic (stack ELK) per il monitoraggio del tuo database gestito è il suo eccellente supporto per la ricerca e la capacità di ingerire rapidamente nuovi dati. Non eccelle nell’aggiornamento dei dati, ma questo compromesso è accettabile per scopi di monitoraggio e registrazione, dove i dati passati quasi mai vengono modificati. Elasticsearch offre un potente mezzo per interrogare i dati, che puoi utilizzare attraverso Kibana per avere una migliore comprensione di come il database si comporta attraverso periodi temporali diversi. Ciò ti consentirà di correlare il carico del database con eventi reali per ottenere una visione di come viene utilizzato il database.
In questo tutorial, importerai le metriche del database, generate dal comando INFO di Redis, in Elasticsearch tramite Logstash. Questo comporta la configurazione di Logstash per eseguire periodicamente il comando, analizzare il suo output e inviarlo subito dopo all’indicizzazione di Elasticsearch. I dati importati possono poi essere analizzati e visualizzati in Kibana. Alla fine del tutorial, avrai un sistema automatizzato che acquisisce le statistiche di Redis per un’analisi successiva.
Prerequisiti
- Un server Ubuntu 18.04 con almeno 8 GB di RAM, privilegi di root e un account secondario non di root. Puoi configurarlo seguendo questa guida iniziale alla configurazione del server. Per questo tutorial, l’utente non di root è
sammy. - Java 8 installato sul tuo server. Per le istruzioni di installazione, visita Come installare Java con
aptsu Ubuntu 18.04 e segui i comandi indicati nel primo passaggio. Non è necessario installare il Java Development Kit (JDK). - Nginx installato sul tuo server. Per una guida su come fare ciò, consulta il tutorial Come installare Nginx su Ubuntu 18.04.
- Elasticsearch e Kibana installati sul tuo server. Completa i primi due passaggi del tutorial Come installare Elasticsearch, Logstash e Kibana (Elastic Stack) su Ubuntu 18.04.
- A Redis managed database provisioned from DigitalOcean with connection information available. Make sure that your server’s IP address is on the whitelist. For a guide on creating a Redis database using the DigitalOcean Control Panel, visit the Redis Quickstart guide.
- Redli installato sul tuo server secondo il tutorial Come connettersi a un database gestito su Ubuntu 18.04.
Passaggio 1 — Installazione e Configurazione di Logstash
In questa sezione, installerai Logstash e lo configurerai per estrarre le statistiche dal tuo cluster di database Redis, quindi analizzarle per inviarle ad Elasticsearch per l’indicizzazione.
Inizia installando Logstash con il seguente comando:
Una volta installato Logstash, abilita il servizio per avviarsi automaticamente all’avvio:
Prima di configurare Logstash per estrarre le statistiche, vediamo com’è fatta la data stessa. Per connetterti al tuo database Redis, vai al Pannello di Controllo del Database Gestito e sotto il pannello Dettagli di Connessione, seleziona Flag dal menu a discesa:
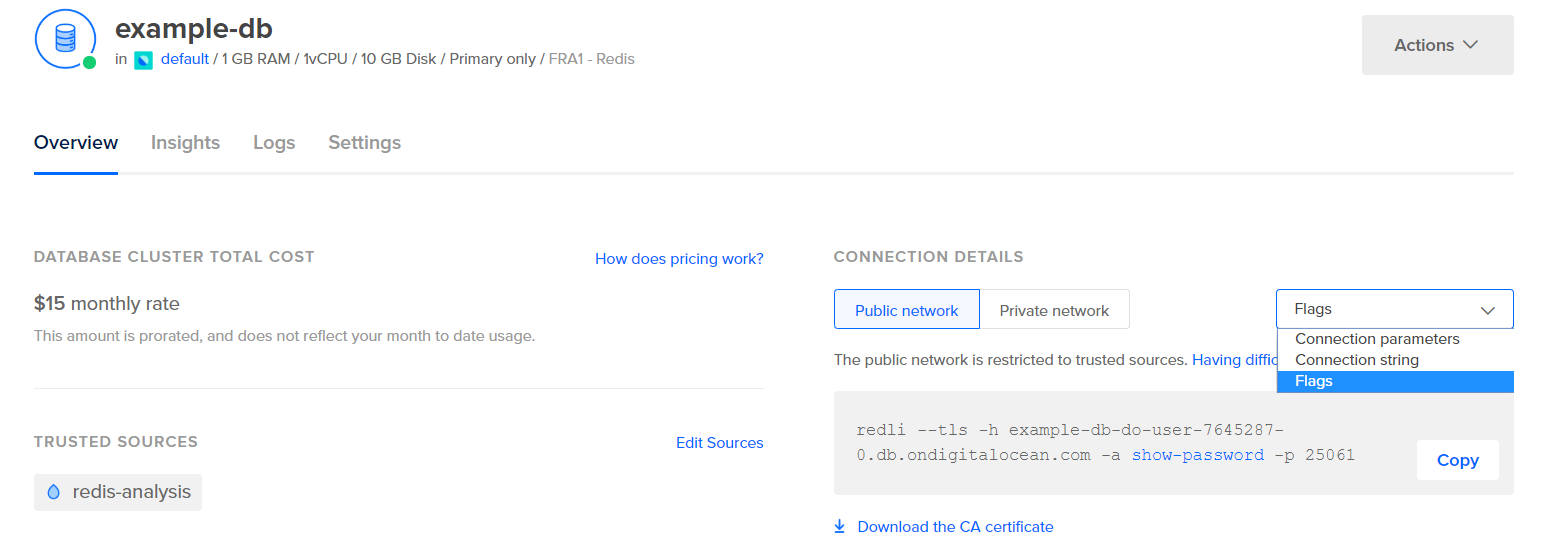
Ti verrà mostrato un comando preconfigurato per il client Redli, che userai per connetterti al tuo database. Clicca Copia ed esegui il seguente comando sul tuo server, sostituendo comando_flag_redli con il comando che hai appena copiato:
Dato che l’output di questo comando è lungo, spiegheremo questo suddiviso nelle sue diverse sezioni.
Nell’output del comando info di Redis, le sezioni sono contrassegnate con #, che indica un commento. I valori sono popolati nella forma chiave:valore, che li rende relativamente facili da analizzare.
La sezione Server contiene informazioni tecniche sulla build di Redis, come la sua versione e il commit Git su cui è basato, mentre la sezione Clients fornisce il numero di connessioni attualmente aperte.
Output# Server
redis_version:6.2.6
redis_git_sha1:4f4e829a
redis_git_dirty:1
redis_build_id:5861572cb79aebf3
redis_mode:standalone
os:Linux 5.11.12-300.fc34.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:11.2.1
process_id:79
process_supervised:systemd
run_id:b8a0aa25d8f49a879112a04a817ac2acd92e0c75
tcp_port:25060
server_time_usec:1640878632737564
uptime_in_seconds:1679
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:13488680
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
io_threads_active:0
# Clients
connected_clients:4
cluster_connections:0
maxclients:10032
client_recent_max_input_buffer:24
client_recent_max_output_buffer:0
...
Memory conferma quanta RAM Redis ha allocato per sé, così come la quantità massima di memoria che può eventualmente utilizzare. Se inizia a esaurire la memoria, libererà le chiavi utilizzando la strategia specificata nel Pannello di Controllo (mostrata nel campo maxmemory_policy in questo output).
Output...
# Memory
used_memory:977696
used_memory_human:954.78K
used_memory_rss:9977856
used_memory_rss_human:9.52M
used_memory_peak:977696
used_memory_peak_human:954.78K
used_memory_peak_perc:100.00%
used_memory_overhead:871632
used_memory_startup:810128
used_memory_dataset:106064
used_memory_dataset_perc:63.30%
allocator_allocated:947216
allocator_active:1273856
allocator_resident:3510272
total_system_memory:1017667584
total_system_memory_human:970.52M
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:455081984
maxmemory_human:434.00M
maxmemory_policy:noeviction
allocator_frag_ratio:1.34
allocator_frag_bytes:326640
allocator_rss_ratio:2.76
allocator_rss_bytes:2236416
rss_overhead_ratio:2.84
rss_overhead_bytes:6467584
mem_fragmentation_ratio:11.43
mem_fragmentation_bytes:9104832
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:61504
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
...
Nella sezione Persistence, puoi vedere l’ultima volta che Redis ha salvato le chiavi che memorizza su disco, e se è stato riuscito. La sezione Stats fornisce numeri relativi alle connessioni client e in-cluster, al numero di volte in cui la chiave richiesta è stata (o non è stata) trovata, e così via.
Output...
# Persistence
loading:0
current_cow_size:0
current_cow_size_age:0
current_fork_perc:0.00
current_save_keys_processed:0
current_save_keys_total:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1640876954
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:217088
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
module_fork_in_progress:0
module_fork_last_cow_size:0
# Stats
total_connections_received:202
total_commands_processed:2290
instantaneous_ops_per_sec:0
total_net_input_bytes:38034
total_net_output_bytes:1103968
instantaneous_input_kbps:0.01
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:29
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:452
total_forks:1
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
total_error_replies:0
dump_payload_sanitizations:0
total_reads_processed:2489
total_writes_processed:2290
io_threaded_reads_processed:0
io_threaded_writes_processed:0
...
Osservando il role sotto Replication, saprai se sei connesso a un nodo primario o replica. Il resto della sezione fornisce il numero di repliche attualmente collegate e la quantità di dati che mancano alla replica rispetto al primario. Potrebbero esserci campi aggiuntivi se l’istanza a cui sei connesso è una replica.
Nota: Il progetto Redis utilizza i termini “master” e “slave” nella sua documentazione e in vari comandi. DigitalOcean preferisce generalmente i termini alternativi “primario” e “replica”. Questa guida utilizzerà per impostazione predefinita i termini “primario” e “replica” quando possibile, ma nota che ci sono alcuni casi in cui i termini “master” e “slave” emergono inevitabilmente.
Output...
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:f727fad3691f2a8d8e593b087c468bbb83703af3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:45088768
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
...
Sotto CPU, vedrai la quantità di potenza di sistema (used_cpu_sys) e utente (used_cpu_user) che Redis sta consumando al momento. La sezione Cluster contiene solo un campo unico, cluster_enabled, che serve per indicare che il cluster Redis è in esecuzione.
Output...
# CPU
used_cpu_sys:1.617986
used_cpu_user:1.248422
used_cpu_sys_children:0.000000
used_cpu_user_children:0.001459
used_cpu_sys_main_thread:1.567638
used_cpu_user_main_thread:1.218768
# Modules
# Errorstats
# Cluster
cluster_enabled:0
# Keyspace
Logstash sarà incaricato di eseguire periodicamente il comando info sul tuo database Redis (simile a quanto hai appena fatto), analizzare i risultati e inviarli a Elasticsearch. Potrai poi accedervi in seguito da Kibana.
Memorizzerai la configurazione per l’indicizzazione delle statistiche di Redis in Elasticsearch in un file chiamato redis.conf nella directory /etc/logstash/conf.d, dove Logstash memorizza i file di configurazione. Quando avviato come servizio, verrà eseguito automaticamente in background.
Crea redis.conf utilizzando il tuo editor preferito (ad esempio, nano):
Aggiungi le seguenti righe:
input {
exec {
command => "redis_flags_command info"
interval => 10
type => "redis_info"
}
}
filter {
kv {
value_split => ":"
field_split => "\r\n"
remove_field => [ "command", "message" ]
}
ruby {
code =>
"
event.to_hash.keys.each { |k|
if event.get(k).to_i.to_s == event.get(k) # is integer?
event.set(k, event.get(k).to_i) # convert to integer
end
if event.get(k).to_f.to_s == event.get(k) # is float?
event.set(k, event.get(k).to_f) # convert to float
end
}
puts 'Ruby filter finished'
"
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "%{type}"
}
}
Ricorda di sostituire redis_flags_command con il comando mostrato nel pannello di controllo che hai usato in precedenza nello step.
Si definisce un input, che è un insieme di filtri che verranno eseguiti sui dati raccolti, e un output che invierà i dati filtrati a Elasticsearch. L’input consiste nel comando exec, che eseguirà un comando sul server periodicamente, dopo un intervallo di tempo impostato intervallo (espresso in secondi). Specifica anche un parametro tipo che definisce il tipo di documento quando viene indicizzato in Elasticsearch. Il blocco exec passa un oggetto contenente due campi, comando e una stringa messaggio. Il campo comando conterrà il comando eseguito e il messaggio conterrà il suo output.
Ci sono due filtri che verranno eseguiti sequenzialmente sui dati raccolti dall’input. Il filtro kv sta per filtro chiave-valore ed è integrato in Logstash. Viene utilizzato per il parsing dei dati nella forma generale di chiaveseparatore_valorevalore e fornisce parametri per specificare cosa sono considerati separatori di valore e di campo. Il separatore di campo riguarda le stringhe che separano i dati formattati nella forma generale l’uno dall’altro. Nel caso dell’output del comando INFO di Redis, il separatore di campo (field_split) è una nuova riga, e il separatore di valore (value_split) è :. Le righe che non seguono la forma definita verranno scartate, compresi i commenti.
Per configurare il filtro kv, passi : al parametro value_split, e \r\n (indicante una nuova riga) al parametro field_split. Ordini anche di rimuovere i campi command e message dall’oggetto dati attuale passandoli a remove_field come elementi di un array, poiché contengono dati che ora sono inutili.
Il filtro kv rappresenta il valore che ha analizzato come un tipo stringa (testo) per progetto. Questo solleva un problema perché Kibana non può facilmente elaborare i tipi di stringa, anche se in realtà si tratta di un numero. Per risolvere questo problema, userai del codice Ruby personalizzato per convertire le stringhe contenenti solo numeri in numeri, quando possibile. Il secondo filtro è un blocco ruby che fornisce un parametro code accettando una stringa contenente il codice da eseguire.
event è una variabile che Logstash fornisce al tuo codice e contiene i dati correnti nella pipeline dei filtri. Come è stato notato in precedenza, i filtri vengono eseguiti uno dopo l’altro, il che significa che il filtro Ruby riceverà i dati analizzati dal filtro kv. Il codice Ruby stesso converte l’event in un Hash e attraversa le chiavi, quindi controlla se il valore associato alla chiave potrebbe essere rappresentato come un intero o come un float (un numero con decimali). Se può, il valore della stringa viene sostituito con il numero analizzato. Quando il ciclo finisce, stampa un messaggio (Ruby filter finished) per segnalare il progresso.
L’output invia i dati elaborati a Elasticsearch per l’indicizzazione. Il documento risultante verrà memorizzato nell’indice redis_info, definito nell’input e passato come parametro al blocco di output.
Salva e chiudi il file.
Hai installato Logstash usando apt e lo hai configurato per richiedere periodicamente le statistiche da Redis, elaborarle e inviarle alla tua istanza Elasticsearch.
Passaggio 2 — Test della Configurazione di Logstash
Ora testerai la configurazione eseguendo Logstash per verificare che estrarrà correttamente i dati.
Logstash supporta l’esecuzione di una specifica configurazione passando il percorso del file al parametro -f. Esegui il seguente comando per testare la nuova configurazione dall’ultimo passaggio:
Potrebbe richiedere del tempo per mostrare l’output, ma presto vedrai qualcosa di simile a quanto segue:
OutputUsing bundled JDK: /usr/share/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[INFO ] 2021-12-30 15:42:08.887 [main] runner - Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
[INFO ] 2021-12-30 15:42:08.932 [main] settings - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
[INFO ] 2021-12-30 15:42:08.939 [main] settings - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
[WARN ] 2021-12-30 15:42:09.406 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2021-12-30 15:42:09.449 [LogStash::Runner] agent - No persistent UUID file found. Generating new UUID {:uuid=>"acc4c891-936b-4271-95de-7d41f4a41166", :path=>"/usr/share/logstash/data/uuid"}
[INFO ] 2021-12-30 15:42:10.985 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[INFO ] 2021-12-30 15:42:11.601 [Converge PipelineAction::Create<main>] Reflections - Reflections took 77 ms to scan 1 urls, producing 119 keys and 417 values
[WARN ] 2021-12-30 15:42:12.215 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.366 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.431 [Converge PipelineAction::Create<main>] elasticsearch - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:12.494 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2021-12-30 15:42:12.755 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2021-12-30 15:42:12.955 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2021-12-30 15:42:12.967 [[main]-pipeline-manager] elasticsearch - Elasticsearch version determined (7.16.2) {:es_version=>7}
[WARN ] 2021-12-30 15:42:12.968 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[WARN ] 2021-12-30 15:42:13.065 [[main]-pipeline-manager] kv - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:13.090 [Ruby-0-Thread-10: :1] elasticsearch - Using a default mapping template {:es_version=>7, :ecs_compatibility=>:disabled}
[INFO ] 2021-12-30 15:42:13.147 [Ruby-0-Thread-10: :1] elasticsearch - Installing Elasticsearch template {:name=>"logstash"}
[INFO ] 2021-12-30 15:42:13.192 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/etc/logstash/conf.d/redis.conf"], :thread=>"#<Thread:0x5104e975 run>"}
[INFO ] 2021-12-30 15:42:13.973 [[main]-pipeline-manager] javapipeline - Pipeline Java execution initialization time {"seconds"=>0.78}
[INFO ] 2021-12-30 15:42:13.983 [[main]-pipeline-manager] exec - Registering Exec Input {:type=>"redis_info", :command=>"redli --tls -h db-redis-fra1-68603-do-user-1446234-0.b.db.ondigitalocean.com -a hnpJxAgoH3Om3UwM -p 25061 info", :interval=>10, :schedule=>nil}
[INFO ] 2021-12-30 15:42:13.994 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
[INFO ] 2021-12-30 15:42:14.034 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
Ruby filter finished
Ruby filter finished
Ruby filter finished
...
Vedrai il messaggio Filtro Ruby completato essere stampato a intervalli regolari (impostato su 10 secondi nel passaggio precedente), il che significa che le statistiche vengono inviate a Elasticsearch.
Puoi uscire da Logstash cliccando CTRL + C sulla tastiera. Come già menzionato, Logstash eseguirà automaticamente tutti i file di configurazione trovati sotto /etc/logstash/conf.d in background quando avviato come servizio. Esegui il seguente comando per avviarlo:
Hai eseguito Logstash per verificare se può connettersi al tuo cluster Redis e raccogliere dati. Successivamente, esplorerai alcuni dei dati statistici in Kibana.
Passaggio 3 — Esplorare i Dati Importati in Kibana
In questa sezione, esplorerai e visualizzerai i dati statistici che descrivono le prestazioni del tuo database in Kibana.
Nel tuo browser web, vai al tuo dominio dove hai esposto Kibana come parte dei prerequisiti. Vedrai la pagina di benvenuto predefinita:
Prima di esplorare i dati che Logstash sta inviando a Elasticsearch, dovrai prima aggiungere l’indice redis_info a Kibana. Per farlo, seleziona prima Esplora da solo dalla pagina di benvenuto e poi apri il menu hamburger nell’angolo in alto a sinistra. Sotto Analisi, fai clic su Scopri.
Kibana ti chiederà quindi di creare un nuovo modello di indice:
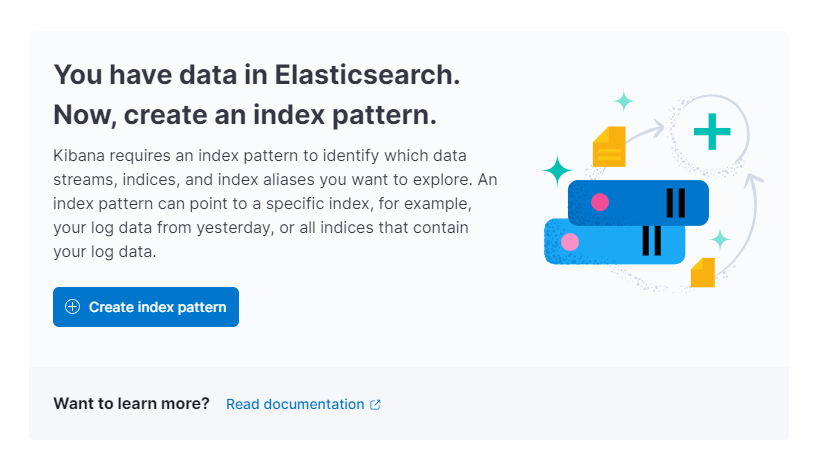
Premi su Crea modello di indice. Vedrai un modulo per creare un nuovo Modello di Indice. I Modelli di Indice in Kibana forniscono un modo per estrarre dati da più indici Elasticsearch contemporaneamente e possono essere utilizzati per esplorare solo un indice.

A destra, Kibana elenca tutti gli indici disponibili, come redis_info che hai configurato Logstash per utilizzare. Digita nel campo di testo Nome e seleziona @timestamp dal menu a discesa come Campo di Timestamp. Quando hai finito, premi sul pulsante Crea modello di indice qui sotto.
Per creare e visualizzare visualizzazioni esistenti, apri il menu a hamburger. Sotto Analitica, seleziona Dashboard. Quando si carica, premi su Crea visualizzazione per iniziare a creare una nuova:
Il pannello laterale sinistro fornisce un elenco di valori che Kibana può utilizzare per disegnare la visualizzazione, che verrà mostrata nella parte centrale dello schermo. Nell’angolo in alto a destra dello schermo si trova il selettore dell’intervallo di date. Se il campo @timestamp viene utilizzato nella visualizzazione, Kibana mostrerà solo i dati appartenenti all’intervallo di tempo specificato nel selettore dell’intervallo.
Dal menu a discesa nella parte principale della pagina, seleziona Linea sotto la sezione Linea e area. Quindi, trova il campo used_memory dall’elenco a sinistra e trascinalo nella parte centrale. Vedrai presto una visualizzazione a linee della quantità mediana di memoria utilizzata nel tempo:
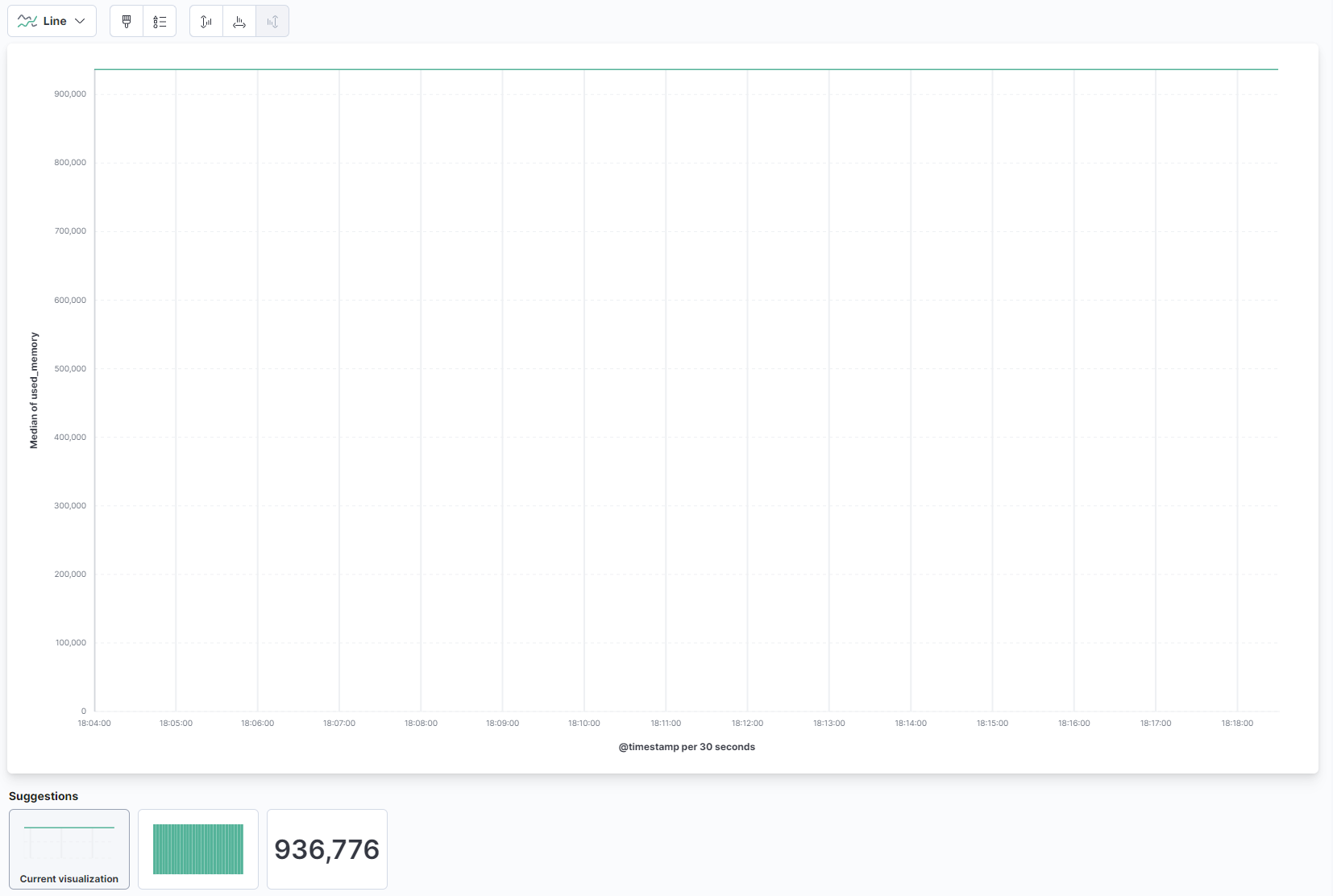
A destra, puoi configurare come sono elaborati gli assi orizzontali e verticali. Lì, puoi impostare l’asse verticale per mostrare i valori medi invece della mediana premendo sull’asse mostrato:
Puoi selezionare una funzione diversa o fornire la tua:
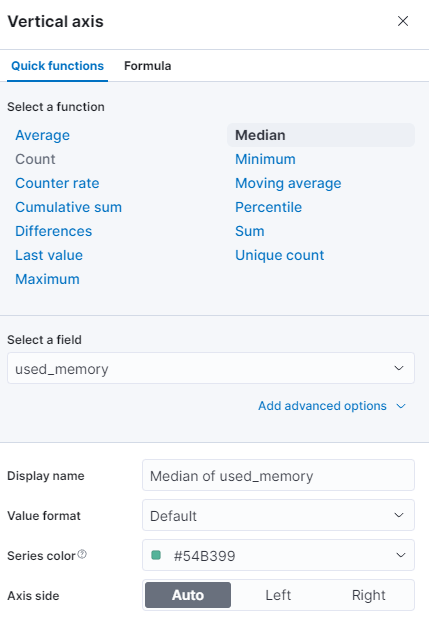
Il grafico verrà immediatamente aggiornato con i valori aggiornati.
In questo passaggio, hai visualizzato l’utilizzo della memoria del tuo database Redis gestito utilizzando Kibana. Ciò ti permetterà di avere una migliore comprensione di come viene utilizzato il tuo database, il che ti aiuterà ad ottimizzare le applicazioni client, così come il database stesso.
Conclusion
Ora hai installato lo stack Elastic sul tuo server e configurato per estrarre dati statistici dal tuo database Redis gestito regolarmente. Puoi analizzare e visualizzare i dati utilizzando Kibana, o qualche altro software adatto, che ti aiuterà a raccogliere preziose informazioni e correlazioni reali su come si sta comportando il tuo database.
Per ulteriori informazioni su cosa puoi fare con il tuo database Redis gestito, visita la documentazione del prodotto. Se desideri presentare le statistiche del database utilizzando un altro tipo di visualizzazione, consulta la documentazione di Kibana per ulteriori istruzioni.