













הנתונים הגדולים התפתחו באופן משמעותי מאז שהחלו בסוף שנות ה-2000. רבות מהארגונים ערכו התאמות מהירות למגמה זו ובנו את הפלטפורמות שלהם לנתונים גדולים באמצעות כלים קוד פתוח כמו Apache Hadoop. בהמשך, החברות הללו החלו להתמודד עם קשיים בניהול הצרכים המתרקמים במהירות של עיבוד הנתונים. הם נתפסו באתגרים בניהול שינויים ברמות הסכימה, התפתחות סכמות הפיצול, וחזרה בזמן כדי לבדוק את הנתונים.
נתקלתי באתגרים דומים בזמן שיצרתי מערכות מופצות בקנה מידה גדול בשנות ה-2010 עבור חברה טכנולוגית גדולה וללקוח בתחום הבריאות. כמה תעשיות זקוקות ליכולות אלו כדי לעמוד בתקנות בנקאות, פיננסים ובריאות. חברות כבדות מונעות נתונים כמו Netflix נתפסו גם באתגרים דומים. הם המציאו פורמט טבלאי שנקרא "Iceberg," אשר נמצא מעל קבצי הנתונים הקיימים ומספק תכונות מפתח על ידי ניצול הארכיטקטורה שלו. זה הפך במהרה לפרויקט המוביל של ASF כשהוא זכה לעניין מהיר בקהילת הנתונים. אחקור את 5 התכונות המפתח של Apache Iceberg במאמר זה עם דוגמאות ודיאגרמות.
1. מסע בזמן

איור 1: מסע בזמן בפורמט הטבלה של Apache Iceberg (תמונה שנוצרה על ידי המחבר)
תכונה זו מאפשרת לך לשאול את הנתונים שלך כפי שהם קיימים בכל נקודה. זה יפתח אפשרויות חדשות לניתוחנים ולניתוח עסקיים להבין מגמות וכיצד הנתונים התפתחו לאורך הזמן. אתה יכול לחזור בקלות למצב קודם במקרה של טעויות. תכונה זו גם מקלה על בדיקות אודיט על ידי הרשאתך לנתח את הנתונים בנקודה מסוימת בזמן.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. אבולוציית סכימה
אבולוציית סכימה של Apache Iceberg מאפשרת שינויים בסכימה שלך ללא כל מאמץ גדול או העברות יקרות. כשצרכי העסק שלך מתפתחים, אתה יכול:
- להוסיף ולהסיר עמודות בלי כל הפסקת שירות או כתיבת טבלה מחדש.
- לעדכן את העמודה (הרחבה).
- לשנות את סדר העמודות.
- לשנות את שם העמודה הקיימת.
השינויים הללו נמצאים בשלב המטא-נתונים מבלי לצורך לכתוב מחדש את הנתונים הבסיסיים.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. אבולוציית מחיצה
באמצעות פורמט טבלת Apache Iceberg, אתה יכול לשנות את אסטרטגיית המחיצה של הטבלה ללא צורך לכתוב מחדש את הטבלה הבסיסית או להעביר את הנתונים לטבלה חדשה. זה נעשה אפשרי מאחר ושאילתות לא מתייחסות ישירות לערכי המחיצה כמו ב־Apache Hadoop. Iceberg שומרת מידע על מגרסאות המחיצה לכל פריט בנפרד. זה עושה את התהליך פשוט לקבלת החלוקות בזמן ששואלים את הנתונים. לדוגמה, לשאילתת טבלה על פי טווח תאריכים, בזמן שהטבלה השתמשה בחודש כעמודת מחיצה (לפני) כחלוקה אחת ויום כעמודת מחיצה חדשה (אחרי) כחלוקה אחרת. זה נקרא תכנון פיצולים. ראה את הדוגמה למטה.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. עסקאות ACID
Iceberg מספקת תמיכה חזקה לעסקאות במונחים של אטומיות, עקביות, בידוד ועמידות (ACID). היא מאפשרת פעולות כתיבה רבות במקביל, מה שיאפשר תפוקה גבוהה בעבודות כבדות על נתונים מבלי לפגוע בעקביות הנתונים.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
כל הפעולות ב-Iceberg הן עסקאות, כלומר הנתונים נשארים עקביים למרות תקלות או שינויים בנתונים במקביל.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
כמו כן, היא תומכת ברמות בידוד שונות, מה שמאפשר לך לאזן בין ביצועים לעקביות בהתאם לדרישה.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
הנה סיכום המראה כיצד Iceberg מנהלת עדכונים ומחיקות ברמת השורה.
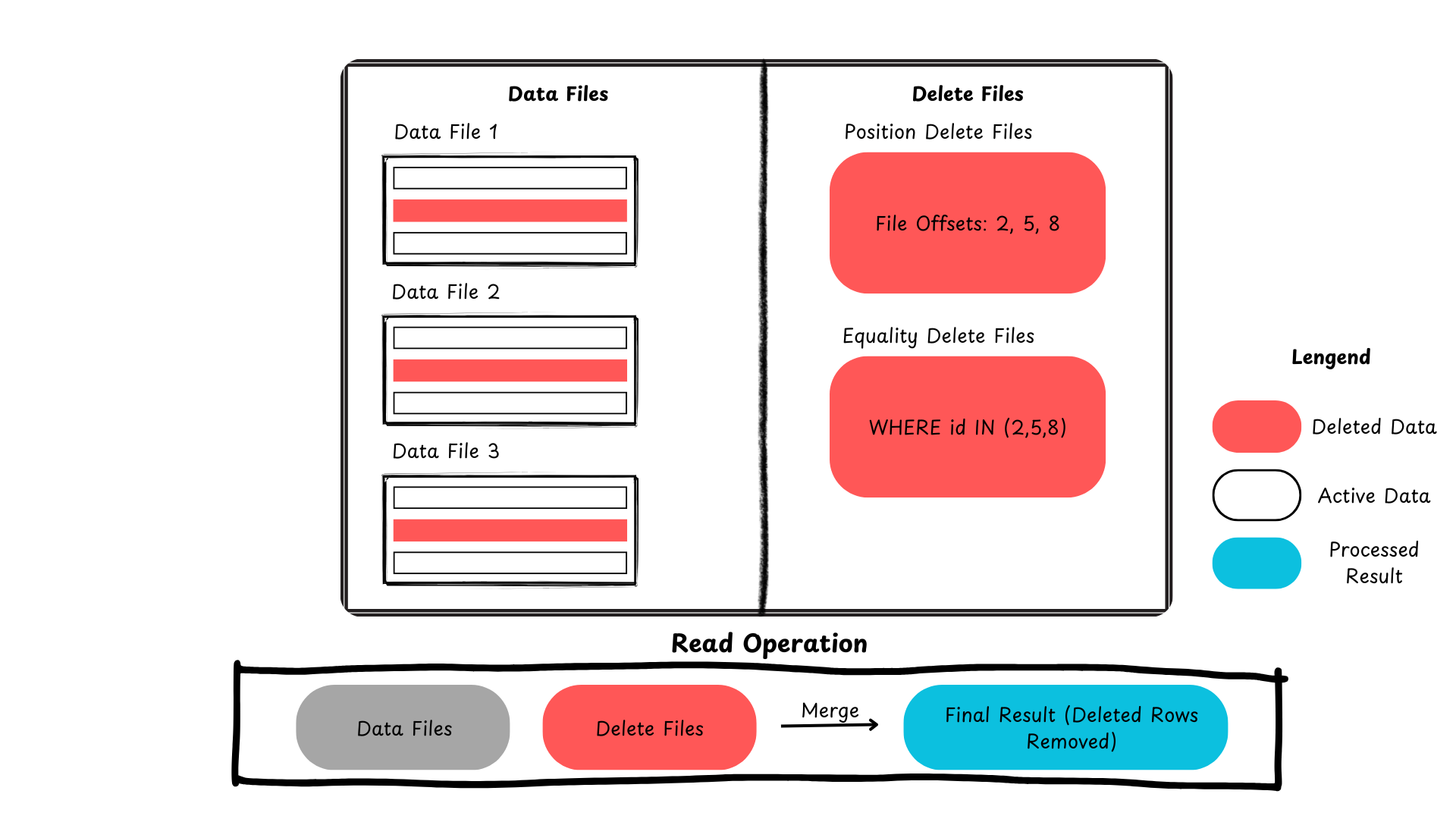
איור 2: תהליך מחיקת רשומות ב-Apache Iceberg (תמונה שנוצרה על ידי המחבר)
5. פעולות מתקדמות על טבלאות
Iceberg תומכת בפעולות מתקדמות על טבלאות כגון:
- יצירה/ניהול של תמונות מצב של טבלאות: זה מעניק את היכולת לשלוט בגרסאות באופן חזק.
- תכנון וביצוע שאילתות מהיר עם מטא-דאטה אופטימלי מאוד
- כלים מובנים לתחזוקת טבלאות, כגון הידוק וניקוי קבצים יתומים
Iceberg מיועדת לעבוד עם כל שירותי האחסון הגדולים בענן, כגון AWS S3, GCS ואחסון ב-Azure Blob. כמו כן, Iceberg משתלבת בקלות עם מנועי עיבוד נתונים כגון Spark, Presto, Trino ו-Hive.
מחשבות סופיות
התכונות המודגשות הללו מאפשרות לחברות לבנות אגמי נתונים מודרניים, גמישים, נפחיים, ויעילים, שיכולים לנסוע בזמן, לטפל בשינויי סכמה בקלות, לתמוך בעסקאות ACID, ולהתפתח במבנה המחיצה.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes