













Contexte
Qu’est-ce que le PL/SQL ?
PL/SQL est un langage procédural conçu spécifiquement pour intégrer des instructions SQL dans sa syntaxe. Il inclut des éléments de langage procédural tels que des conditions et des boucles, et peut gérer les exceptions (erreurs d’exécution).
PL/SQL est natif des bases de données Oracle, et des bases de données telles que IBM DB2, PostgreSQL et MySQL prennent en charge les constructions PL/SQL grâce à des fonctionnalités de compatibilité.
Qu’est-ce qu’une UDF JavaScript ?
Une UDF JavaScript est l’alternative de Couchbase au PL/SQL.
Les UDF JavaScript apportent la flexibilité de script généraliste de JavaScript aux bases de données, permettant des opérations dynamiques et puissantes sur les systèmes de bases de données modernes et renforçant la flexibilité dans la requête, le traitement et la transformation des données.
La plupart des bases de données modernes comme Couchbase, MongoDB, Snowflake et Google BigQuery prennent en charge les UDF JavaScript.
Le Problème
Un problème courant rencontré par les utilisateurs migrant d’Oracle vers Couchbase est de transposer leurs scripts PL/SQL. Au lieu de prendre en charge le PL/SQL, Couchbase permet aux utilisateurs de construire des fonctions définies par l’utilisateur en JavaScript (pris en charge depuis 2021).
Les UDF JavaScript permettent une manipulation facile et intuitive des données variées et JSON. Les objets variés passés à une UDF sont transformés en types et valeurs JavaScript natifs.
La conséquence involontaire de ceci est que la majorité des SGBDR qui existent depuis les dix dernières années ont fortement encouragé les développeurs à accéder à la base de données en utilisant leurs extensions procédurales à SQL (PL/pgSQL, PL/SQL), qui supportent les constructions procédurales, l’intégration avec SQL, la gestion des erreurs, les fonctions et procédures, les déclencheurs, et les curseurs, ou au moins, les fonctions et procédures (comme Sakila). Pour toute tentative de s’en éloigner, tous leurs scripts devraient être réécrits.
Réécrire du code est souvent une tâche fastidieuse, surtout lorsqu’il s’agit de scripts PL/SQL écrits dans les années 2000 et maintenus depuis. Ces scripts peuvent être complexes, s’étendant souvent sur des milliers de lignes, ce qui peut être accablant pour l’utilisateur moyen en entreprise.
Solution
L’approche idéale consisterait à développer un tout nouvel évaluateur PL/SQL, mais cela nécessiterait un nombre excessif d’heures d’ingénierie, et pour le même cas d’utilisation, nous disposons déjà d’un évaluateur JsEvaluator moderne, stable et rapide – alors pourquoi soutenir un autre évaluateur?
Cela fait du problème un cas d’utilisation parfait pour tirer parti des avancées en cours en matière d’IA et de LLMs – et c’est ce que nous avons fait ici. Nous avons utilisé des modèles d’IA génératifs pour automatiser la conversion de PL/SQL en JSUDF.
En juin 2024, les modèles ont une fenêtre contextuelle limitée, ce qui signifie que les PL/SQL plus longs rencontrent l’erreur :
« La longueur maximale du contexte de ce modèle est de 8192 jetons. Cependant, vos messages ont résulté en <Plus-de-8192> jetons. Veuillez réduire la longueur des messages. »
- Notez que cela concerne GPT4.
Alors, attendons-nous que l’IA devienne plus puissante et permette plus de jetons (comme la loi de Moore, mais pour la longueur de contexte de l’IA par rapport à la précision) ?
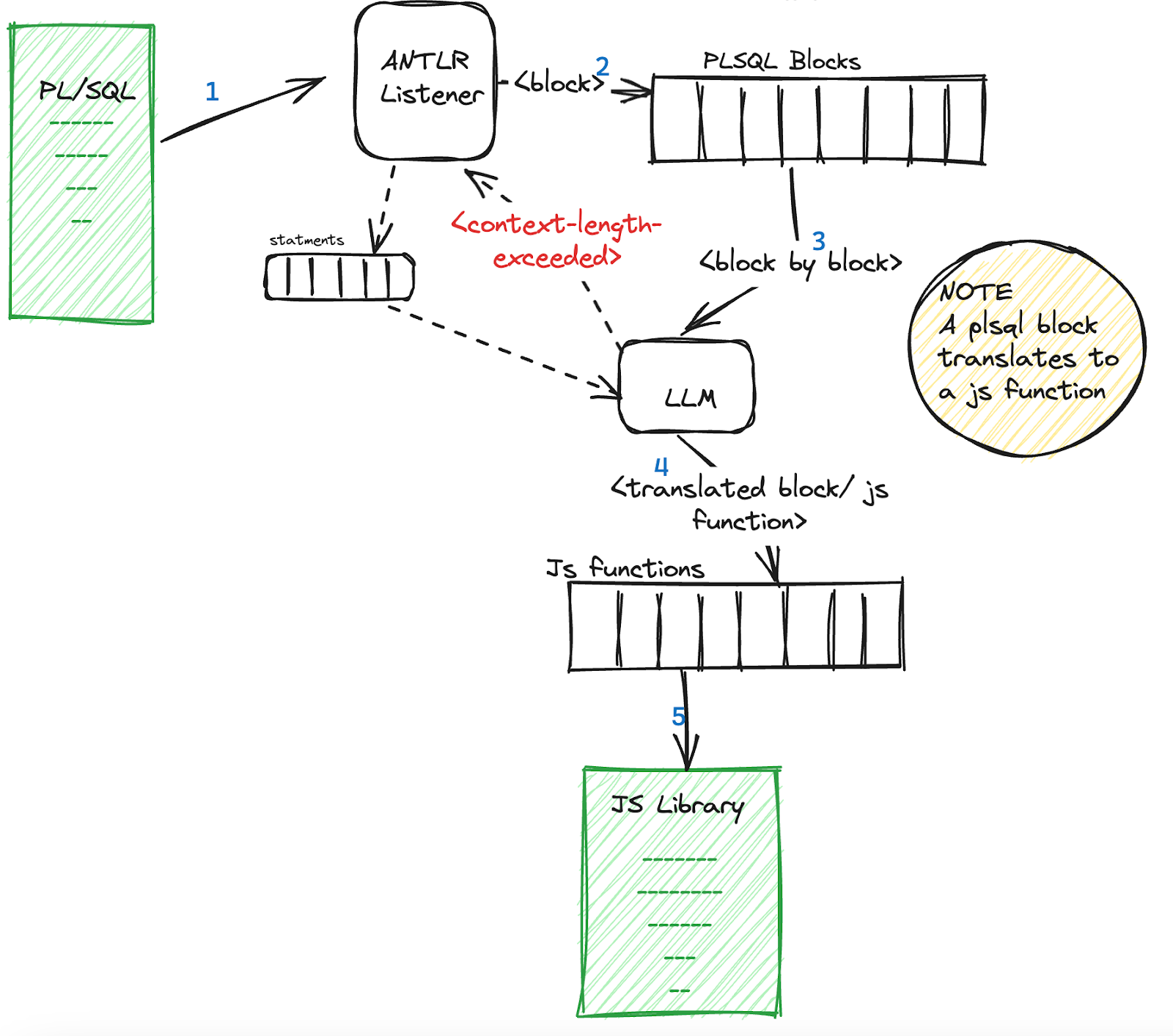
Non : c’est là que l’outil générateur de parseur ANTLR entre en jeu. ANTLR est bien connu pour être utilisé dans le développement de compilateurs et d’interpréteurs. De cette manière, nous pouvons diviser le grand script en unités plus petites qui peuvent être traduites indépendamment.
Alors maintenant, construisons-nous un transpileur ? Eh bien, oui et non.
Les étapes d’un transpileur sont les suivantes :
- Analyse lexicale (tokenisation)
- Analyse syntaxique (parsing)
- Analyse sémantique
- Génération de Représentation Intermédiaire (RI)
- Optimisation (optionnelle)
- Génération de code cible
Comment fonctionne le traducteur IA
Les étapes 1 et 2 sont faites en utilisant ANTLR.
Nous utilisons l’interface Listener d’ANTLR pour saisir les blocs de Procédure/Fonction/Anonyme individuels, car ce sont des blocs de code indépendants. Dans un cas où les blocs de Procédure/Fonction/Anonyme eux-mêmes dépassent la fenêtre de contexte, nous traduisons au niveau des instructions (où le LLM suppose l’existence d’utilisation de variables/appels de fonction qui ne sont pas définis ici mais quelque part auparavant).
Ensuite, les étapes 3, 4, 5 et 6 sont laissées à la LLM (GPT), c’est-à-dire, traduire chaque bloc PL/SQL en une fonction JavaScript du mieux possible qui préserve également la sémantique opérationnelle du bloc et qui est syntaxiquement correcte.
Les résultats sont étonnamment assez positifs : la traduction est précise à 80-85%.
Un autre avantage de la solution est que nous réduisons l’hallucination en nous concentrant sur une tâche à la fois, ce qui se traduit par des traductions plus précises.
Pour visualiser :
Comment Utiliser l’Outil
L’exécutable attend les arguments de la ligne de commande suivants :
-u: Adresse e-mail de connexion à Capella-p: Mot de passe de connexion à Capella-cpaddr: URL de Capella pour l’API de complétion de chat-orgid: ID de l’organisation dans le chemin de l’API de complétion de chat-cbhost: node-ip: Noeudcbcluster-cbuser: cluster-user-name: Utilisateurcbcluster, ajouté via l’accès à la base de données-cbpassword: cluster-password: Mot de passecbcluster, ajouté via l’accès à la base de données-cbport: port TLS duquery-service(généralement 18093)filepath, c’est-à-dire le chemin vers le script PL/SQL à traduireoutput->: Dans le répertoire de sortie, un fichier avec le même nom que le fichier plsql est généré avec le code de la bibliothèque JavaScript traduit.
Par exemple, cat example1.sql :
DECLARE
x NUMBER := 0;
counter NUMBER := 0;
BEGIN
FOR i IN 1..4 LOOP
x := x + 1000;
counter := counter + 1;
INSERT INTO temp VALUES (x, counter, 'in OUTER loop');
--démarrer un bloc interne
DECLARE
x NUMBER := 0; -- this is a local version of x
BEGIN
FOR i IN 1..4 LOOP
x := x + 1; -- this increments the local x
counter := counter + 1;
INSERT INTO temp VALUES (x, counter, 'inner loop');
END LOOP;
END;
END LOOP;
COMMIT;
END;
Pour expliquer brièvement le script ci-dessus, une boucle externe s’exécute pendant 4 itérations, incrémentant x de 1000, le compteur de 1. La boucle interne s’exécute pendant 4 itérations, incrémentant x de 1, le compteur de 1.
Exécution du traducteur sur le test PL/SQL :
./plsql-to-jsudf -u «capella-signin-mailid» -p «capella-signin-password» -cpaddr https://api.cloud.couchbase.com -orgid «capella-organisation-id» -cbhost «hostname of data node» -cbuser «cbcluster username» -cbpassword «cbcluster password» -cbport 18093 ./translator/test/plsql/example1.sql
Sortie JsUDF : cat output/example1.js :
function nestedloop(){
var x = 0;
var counter = 0;
var querybegin = BEGIN WORK;
querybegin.close();
for (var i = 1; i <= 4; i++){
x = x + 1000;
counter = counter + 1;
var params = [x, counter];
var query = N1QL('INSERT INTO test.testscope.temp VALUES (uuid(),{"val1":$1,"val2":$2,"val3":"in OUTER loop"})',params);
query.close();
var x_inner = 0;
for (var j = 1; j <= 4; j++){
x_inner = x_inner + 1;
counter = counter + 1;
var params_inner = [x_inner, counter];
var query_inner = N1QL('INSERT INTO test.testscope.temp VALUES (uuid(),{"val1":$1,"val2":$2,"val3":"inner loop"})',params_inner);
query_inner.close();
}
}
var querycommit = COMMIT WORK;
querycommit.close();
}Le script traduit a une fonction nestedloop (nom généré par LLM) qui fait exactement ce que spécifie le bloc PL/SQL anonyme original.
- Remarque : Pour les fonctions/procédures nommées, les fonctions JS traduites porteront le même nom. Pour les blocs anonymes, le LLM utilise un nom qu’il invente.
Problèmes connus
PL/SQL et JS sont deux langages différents, et la manière dont ils sont pris en charge dans Oracle et Couchbase ne permet pas un mapping direct propre entre les deux. Voici quelques limitations que nous avons découvertes et les solutions de contournement que nous avons mises en œuvre :
1. console.log n’est pas pris en charge
La procédure intégrée DBMS_OUTPUT.PUT et deux autres procédures similaires, DBMS_OUTPUT.PUT_LINE et DBMS_OUTPUT.NEW_LINE, sont traduites en console.log(), mais console.log est une API de navigateur et n’est pas pris en charge par l’implémentation d’évaluation JavaScript de Couchbase. Cela a été une demande fréquente, étant donné que la fonction d’événement de Couchbase prend en charge les instructions print() mais pas dans les UDF JavaScript.
Solution de contournement
Il est attendu que les utilisateurs créent un seau de logging.
Les journaux sont insérés en tant que partie d’un document INSERT dans la collection `default`.`default`. Le document ressemblerait à ceci :
{
"udf": «func-name»,
"log": «argument to console.log», // the actual log line
"time": «current ISO time string»
}L’utilisateur peut consulter ses journaux en sélectionnant logging:
SELECT * FROM logging WHERE udf= "«func-name»";
SELECT * FROM logging WHERE time BETWEEN "«date1»" AND "«date2»";Exemple:
- Original
BEGIN
DBMS.OUTPUT.PUT("Hello world!");
END;
/
- Traduction
function helloWorld() {
// solution de contournement pour console.log("Bonjour le monde!");
var currentDate = new Date();
var utcISOString = currentDate.toISOString();
var params = [utcISOString,'anonymousblock1',"Hello world!"];
var logquery = N1QL('INSERT INTO logging VALUES(UUID(),{"udf":$2, "log":$3, "time":$1}, {"expiration": 5*24*60*60 })', params);
logquery.close();
}Ceci est déjà implémenté dans l’outil.
Pour voir le journal :
EXECUTE FUNCTION helloWorld();
"results": [
null
]
CREATE PRIMARY INDEX ON logging;
"results": [
]
SELECT * FROM logging;
"results": [
{"logging":{"log":"Hello world!","time":"2024-06-26T09:20:56.000Z","udf":"anonymousblock1"}}
]2. Appels de Fonctions entre Packages
Les procédures/fonctions répertoriées dans la spécification de package sont globales et peuvent être utilisées à partir d’autres packages via «package_name».«public_procedure/function». Cependant, il en va autrement pour une bibliothèque JavaScript dans Couchbase, car les constructions d’import-export ne sont pas prises en charge par l’implémentation d’évaluation JavaScript de Couchbase.
Solution de contournement
- En cas d’appel de fonction interbibliothèques
«lib_name».«function»(), il est attendu que l’utilisateur ait déjà créé la bibliothèque référencée«lib_name»; vous pouvez vérifier cela viaGET /evaluator/v1/libraries. - Il est également attendu que la fonction référencée
«function»soit créée en tant que UDF global; cela peut être vérifié viaGET /admin/functions_cacheou en sélectionnant l’espace de cléssystem:functions. De cette manière, nous pouvons accéder à la fonction vian1ql.
Exemple :
Package math_utils
CREATE OR REPLACE PACKAGE math_utils AS
-- Fonction publique pour additionner deux nombres
FUNCTION add_numbers(p_num1 NUMBER, p_num2 NUMBER) RETURN NUMBER;
END math_utils;
/
CREATE OR REPLACE PACKAGE BODY math_utils AS
FUNCTION add_numbers(p_num1 NUMBER, p_num2 NUMBER) RETURN NUMBER IS
BEGIN
RETURN p_num1 + p_num2;
END add_numbers;
END math_utils;
/Package show_sum
CREATE OR REPLACE PACKAGE show_sum AS
-- Procédure publique pour afficher la somme de deux nombres
PROCEDURE display_sum(p_num1 NUMBER, p_num2 NUMBER);
END show_sum;
/
CREATE OR REPLACE PACKAGE BODY show_sum AS
PROCEDURE display_sum(p_num1 NUMBER, p_num2 NUMBER) IS
v_sum NUMBER;
BEGIN
-- Appel de la fonction add_numbers du package math_utils
v_sum := math_utils.add_numbers(p_num1, p_num2);
-- Affichage de la somme en utilisant DBMS_OUTPUT.PUT_LINE
DBMS_OUTPUT.PUT_LINE('The sum of ' || p_num1 || ' and ' || p_num2 || ' is ' || v_sum);
END display_sum;
END show_sum;
/
- Code traduit :
function show_sum(a, b) {
var sum_result;
// Solution de contournement pour l'appel de fonction entre bibliothèques math_utils.add_numbers(a, b)
var crossfunc = N1QL("EXECUTE FUNCTION add_numbers($1,$2)",[a, b])
var crossfuncres = []
for(const doc of crossfunc) {
crossfuncres.push(doc);
}
// remplacement réel pour math_utils.add_numbers(a, b)
sum_result = crossfuncres[0];
// solution de contournement pour console.log('La somme de ' + a + ' et ' + b + ' est : ' + sum_result);
var currentDate = new Date();
var utcISOString = currentDate.toISOString();
var params = [utcISOString,'SHOW_SUM','The sum of ' + a + ' and ' + b + ' is: ' + sum_result];
var logquery = N1QL('INSERT INTO logging VALUES(UUID(),{"udf":$2, "log":$3, "time":$1}, {"expiration": 5*24*60*60 })', params);
logquery.close();
}Cela est géré automatiquement par le programme — avec un avertissement selon lequel cela devrait être vérifié par un être humain !
3. Variables globales
PL/SQL prend en charge les variables globales au niveau du package et de la session, mais les variables globales ne sont pas prises en charge dans JsUDF délibérément par conception, car cela suscite des inquiétudes quant aux fuites de mémoire.
Solution de contournement
Le contournement suggéré nécessite un ajustement manuel de la traduction générée. Par exemple :
CREATE OR REPLACE PACKAGE global_vars_pkg AS
-- Déclarations de variables globales
g_counter NUMBER := 0;
g_message VARCHAR2(100) := 'Initial Message';
-- Déclarations de procédures publiques
PROCEDURE increment_counter;
PROCEDURE set_message(p_message VARCHAR2);
PROCEDURE show_globals;
END global_vars_pkg;
/
CREATE OR REPLACE PACKAGE BODY global_vars_pkg AS
-- Procédure pour incrémenter le compteur
PROCEDURE increment_counter IS
BEGIN
g_counter := g_counter + 1;
END increment_counter;
-- Procédure pour définir le message global
PROCEDURE set_message(p_message VARCHAR2) IS
BEGIN
g_message := p_message;
END set_message;
-- Procédure pour afficher les valeurs actuelles des variables globales
PROCEDURE show_globals IS
BEGIN
DBMS_OUTPUT.PUT_LINE('g_counter = ' || g_counter);
DBMS_OUTPUT.PUT_LINE('g_message = ' || g_message);
END show_globals;
END global_vars_pkg;
/Toute fonction qui modifie une variable globale doit l’accepter comme argument et la retourner à l’appelant.
increment_counter:
function increment_counter(counter){
counter = counter + 1;
return counter
}Toute fonction qui ne fait que lire une globale peut l’accepter comme argument.
show_globals:
function show_globals(counter, message){
// contournement pour console.log(counter);
var currentDate = new Date();
var utcISOString = currentDate.toISOString();
var params = [utcISOString,'SHOW_GLOBALS',couter];
var logquery = N1QL('INSERT INTO logging VALUES(UUID(),{"udf":$2, "log":$3, "time":$1}, {"expiration": 5*24*60*60 })', params);
logquery.close();
// contournement pour console.log(message);
var currentDate = new Date();
var utcISOString = currentDate.toISOString();
var params = [utcISOString,'SHOW_GLOBALS',message];
var logquery = N1QL('INSERT INTO logging VALUES(UUID(),{"udf":$2, "log":$3, "time":$1}, {"expiration": 5*24*60*60 })', params);
logquery.close();
}
Package à Bibliothèque
Cette section montre une conversion de package à bibliothèque de bout en bout utilisant l’outil.
- Exemple de package PL/SQL :
CREATE OR REPLACE PACKAGE emp_pkg IS
PROCEDURE insert_employee(
p_emp_id IN employees.emp_id%TYPE,
p_first_name IN employees.first_name%TYPE,
p_last_name IN employees.last_name%TYPE,
p_salary IN employees.salary%TYPE
);
PROCEDURE update_employee(
p_emp_id IN employees.emp_id%TYPE,
p_first_name IN employees.first_name%TYPE,
p_last_name IN employees.last_name%TYPE,
p_salary IN employees.salary%TYPE
);
PROCEDURE delete_employee(
p_emp_id IN employees.emp_id%TYPE
);
PROCEDURE get_employee(
p_emp_id IN employees.emp_id%TYPE,
p_first_name OUT employees.first_name%TYPE,
p_last_name OUT employees.last_name%TYPE,
p_salary OUT employees.salary%TYPE
);
END emp_pkg;
/
CREATE OR REPLACE PACKAGE BODY emp_pkg IS
PROCEDURE insert_employee(
p_emp_id IN employees.emp_id%TYPE,
p_first_name IN employees.first_name%TYPE,
p_last_name IN employees.last_name%TYPE,
p_salary IN employees.salary%TYPE
) IS
BEGIN
INSERT INTO employees (emp_id, first_name, last_name, salary)
VALUES (p_emp_id, p_first_name, p_last_name, p_salary);
END insert_employee;
PROCEDURE update_employee(
p_emp_id IN employees.emp_id%TYPE,
p_first_name IN employees.first_name%TYPE,
p_last_name IN employees.last_name%TYPE,
p_salary IN employees.salary%TYPE
) IS
BEGIN
UPDATE employees
SET first_name = p_first_name,
last_name = p_last_name,
salary = p_salary
WHERE emp_id = p_emp_id;
END update_employee;
PROCEDURE delete_employee(
p_emp_id IN employees.emp_id%TYPE
) IS
BEGIN
DELETE FROM employees
WHERE emp_id = p_emp_id;
END delete_employee;
PROCEDURE get_employee(
p_emp_id IN employees.emp_id%TYPE,
p_first_name OUT employees.first_name%TYPE,
p_last_name OUT employees.last_name%TYPE,
p_salary OUT employees.salary%TYPE
) IS
BEGIN
SELECT first_name, last_name, salary
INTO p_first_name, p_last_name, p_salary
FROM employees
WHERE emp_id = p_emp_id;
END get_employee;
END emp_pkg;
/
- Traduction :
./plsql-to-jsudf -u «capella-signin-mailid» -p «capella-signin-password» -cpaddr https://api.cloud.couchbase.com -orgid «capella-organisation-id» -cbhost «hostname of data node» -cbuser «cbcluster username» -cbpassword «cbcluster password» -cbport 18093 translator/test/plsql/blog_test.sql- Code :
function insert_employee(p_emp_id, p_first_name, p_last_name, p_salary){
var params = [p_emp_id, p_first_name, p_last_name, p_salary];
var query = N1QL('INSERT INTO test.testscope.employees VALUES ($1, {"emp_id":$1, "first_name":$2, "last_name":$3, "salary":$4})', params);
query.close();
}
function update_employee(p_emp_id, p_first_name, p_last_name, p_salary){
var params = [p_first_name, p_last_name, p_salary, p_emp_id];
var query = N1QL('UPDATE test.testscope.employees SET first_name = $1, last_name = $2, salary = $3 WHERE emp_id = $4', params);
query.close();
}
function delete_employee(p_emp_id){
var querybegin=BEGIN WORK;
var params = [p_emp_id];
var query= N1QL('DELETE FROM test.testscope.employees WHERE emp_id = $1',params);
query.close();
var querycommit=COMMIT WORK;
querycommit.close();
}
function get_employee(p_emp_id){
var query = N1QL('SELECT first_name, last_name, salary FROM test.testscope.employees WHERE emp_id = $1', [p_emp_id]);
var rs = [];
for (const row of query) {
rs.push(row);
}
query.close();
var p_first_name = rs[0]['first_name'];
var p_last_name = rs[0]['last_name'];
var p_salary = rs[0]['salary'];
return {first_name: p_first_name, last_name: p_last_name, salary: p_salary};
}
Insérons un nouveau document d’employé.
- Créer une collection d’employés :
curl -u Administrator:password http://127.0.0.1:8091/pools/default/buckets/test/scopes/testscope/collections -d name=employees Insérer un employé
curl -u Administrator:password https://127.0.0.1:18093/query/service -d 'statement=EXECUTE FUNCTION insert_employee(1, "joe", "briggs", 10000)' -k
{
"requestID": "2c0854c1-d221-42e9-af47-b6aa0801a46c",
"signature": null,
"results": [
],
"errors": [{"code":10109,"msg":"Error executing function 'insert_employee' (blog_test:insert_employee)","reason":{"details":{"Code":" var query = N1QL('INSERT INTO test.testscope.employees VALUES ($1, {\"emp_id\":$1, \"first_name\":$2, \"last_name\":$3, \"salary\":$4})', params);","Exception":{"_level":"exception","caller":"insert_send:207","code":5070,"key":"execution.insert_key_type_error","message":"Cannot INSERT non-string key 1 of type value.intValue."},"Location":"functions/blog_test.js:5","Stack":" at insert_employee (functions/blog_test.js:5:17)"},"type":"Exceptions from JS code"}}],
"status": "fatal",
"metrics": {"elapsedTime": "104.172666ms","executionTime": "104.040291ms","resultCount": 0,"resultSize": 0,"serviceLoad": 2,"errorCount": 1}
}Cela échoue, et c’est normal — nous pouvons le corriger manuellement.
Lire la raison et l’exception : Cannot INSERT non-string key 1 of type value.intValue, ah ! La clé est toujours censée être une chaîne : passer insert_employee("1", "joe", "briggs", 10000) ferait l’affaire, mais il n’est pas intuitif de s’attendre à ce que employee_id soit une chaîne.
Modifions le code généré :
function insert_employee(p_emp_id, p_first_name, p_last_name, p_salary){
var params = [p_emp_id.toString(), p_emp_id, p_first_name, p_last_name, p_salary];
var query = N1QL('INSERT INTO test.testscope.employees VALUES ($1, {"emp_id":$2, "first_name":$3, "last_name":$4, "salary":$5})', params);
query.close();
}Et recréons la UDF :
curl -u Administrator:password https://127.0.0.1:18093/query/service -d 'statement=CREATE OR REPLACE FUNCTION insert_employee(p_emp_id, p_first_name, p_last_name, p_salary) LANGUAGE JAVASCRIPT AS "insert_employee" AT "blog_test"' -k
{
"requestID": "89df65ac-2026-4f42-8839-b1ce7f0ea2be",
"signature": null,
"results": [
],
"status": "success",
"metrics": {"elapsedTime": "27.730875ms","executionTime": "27.620083ms","resultCount": 0,"resultSize": 0,"serviceLoad": 2}
}Essayons de l’insérer à nouveau:
curl -u Administrator:password https://127.0.0.1:18093/query/service -d 'statement=EXECUTE FUNCTION insert_employee(1, "joe", "briggs", 10000)' -k
{
"requestID": "41fb76bf-a87f-4472-b8ba-1949789ae74b",
"signature": null,
"results": [
null
],
"status": "success",
"metrics": {"elapsedTime": "62.431667ms","executionTime": "62.311583ms","resultCount": 1,"resultSize": 4,"serviceLoad": 2}
}
Mettre à jour un employé
Zut ! Il y a une erreur : l’employé 1 n’est pas Joe, c’est Emily.
Mettons à jour l’employé 1 :
curl -u Administrator:password https://127.0.0.1:18093/query/service -d 'statement=EXECUTE FUNCTION update_employee(1, "Emily", "Alvarez", 10000)' -k
{
"requestID": "92a0ca70-6d0d-4eb1-bf8d-0b4294ae987d",
"signature": null,
"results": [
null
],
"status": "success",
"metrics": {"elapsedTime": "100.967708ms","executionTime": "100.225333ms","resultCount": 1,"resultSize": 4,"serviceLoad": 2}
}Voir l’employé
curl -u Administrator:password https://127.0.0.1:18093/query/service -d 'statement=EXECUTE FUNCTION get_employee(1)' -k
{
"requestID": "8f180e27-0028-4653-92e0-606c80d5dabb",
"signature": null,
"results": [
{"first_name":"Emily","last_name":"Alvarez","salary":10000}
],
"status": "success",
"metrics": {"elapsedTime": "101.995584ms","executionTime": "101.879ms","resultCount": 1,"resultSize": 59,"serviceLoad": 2}
}
Supprimer l’employé
Emily est partie.
curl -u Administrator:password https://127.0.0.1:18093/query/service -d 'statement=EXECUTE FUNCTION delete_employee(1)' -k
{
"requestID": "18539991-3d97-40e2-bde3-6959200791b1",
"signature": null,
"results": [
],
"errors": [{"code":10109,"msg":"Error executing function 'delete_employee' (blog_test:delete_employee)","reason":{"details":{"Code":" var querycommit=N1QL('COMMIT WORK;', {}, false); ","Exception":{"_level":"exception","caller":"txcouchbase:240","cause":{"cause":{"bucket":"test","collection":"_default","document_key":"_txn:atr-988-#1b0","error_description":"Durability requirements are impossible to achieve","error_name":"DurabilityImpossible","last_connection_id":"eda95f8c35df6746/d275e8398a49e515","last_dispatched_from":"127.0.0.1:50069","last_dispatched_to":"127.0.0.1:11210","msg":"durability impossible","opaque":7,"scope":"_default","status_code":161},"raise":"failed","retry":false,"rollback":false},"code":17007,"key":"transaction.statement.commit","message":"Commit Transaction statement error"},"Location":"functions/blog_test.js:29","Stack":" at delete_employee (functions/blog_test.js:29:21)"},"type":"Exceptions from JS code"}}],
"status": "fatal",
"metrics": {"elapsedTime": "129.02975ms","executionTime": "128.724ms","resultCount": 0,"resultSize": 0,"serviceLoad": 2,"errorCount": 1}
}Encore une fois, nous avons une erreur avec le code généré. En examinant la raison et l’exception, nous pouvons confirmer que le code traduit englobe delete dans une transaction, ce qui n’était pas le cas dans l’original.
Pour les transactions, les buckets doivent avoir la durabilité définie, mais cela nécessite plus d’un serveur de données ; d’où l’erreur.
La solution ici est de modifier le code pour supprimer la traduction englobante.
function delete_employee(p_emp_id){
var params = [p_emp_id];
var query= N1QL('DELETE FROM test.testscope.employees WHERE emp_id = $1',params);
query.close();
}curl -u Administrator:password https://127.0.0.1:18093/query/service -d 'statement=CREATE OR REPLACE FUNCTION delete_employee(p_emp_id) LANGUAGE JAVASCRIPT AS "delete_employee" AT "blog_test"' -k
{
"requestID": "e7432b82-1af8-4dc4-ad94-c34acea59334",
"signature": null,
"results": [
],
"status": "success",
"metrics": {"elapsedTime": "31.129459ms","executionTime": "31.022ms","resultCount": 0,"resultSize": 0,"serviceLoad": 2}
}curl -u Administrator:password https://127.0.0.1:18093/query/service -d 'statement=EXECUTE FUNCTION delete_employee(1)' -k
{
"requestID": "d440913f-58ff-4815-b671-1a72b75bb7eb",
"signature": null,
"results": [
null
],
"status": "success",
"metrics": {"elapsedTime": "33.8885ms","executionTime": "33.819042ms","resultCount": 1,"resultSize": 4,"serviceLoad": 2}
}
Maintenant, toutes les fonctions du PL/SQL d’origine fonctionnent dans Couchbase via des UDF JS. Oui, l’exemple est assez trivial, mais vous avez saisi l’idée de comment utiliser l’outil pour migrer vos scripts PL/SQL avec peu de supervision manuelle.
Rappelez-vous que l’outil est censé vous faire gagner 80 % : les 20 % restants doivent encore être faits par vous, mais c’est bien mieux que d’écrire tout ce code vous-même !
Le Futur
Ce projet est open-source, alors n’hésitez pas à contribuer. Certaines idées qui nous ont été suggérées incluent :
- Une IA critique qui peut critiquer le code généré pour s’assurer qu’aucune intervention manuelle n’est nécessaire
- Actuellement, le code source est un code qui fonctionne simplement ; aucune réflexion sur le parallélisme ou la réutilisation du code n’a été mise en œuvre.
Et inclure également les limites discutées précédemment.
Finalement, je tiens à remercier Kamini Jagtiani de m’avoir guidé et Pierre Regazzoni de m’avoir aidé à tester l’outil de conversion.
Source:
https://dzone.com/articles/oracle-plsqls-to-couchbase-jsudfs-tool