













Les grandes données ont considérablement évolué depuis leur création à la fin des années 2000. De nombreuses organisations se sont rapidement adaptées à cette tendance et ont construit leurs plateformes de grandes données en utilisant des outils open-source comme Apache Hadoop. Par la suite, ces entreprises ont commencé à rencontrer des difficultés à gérer les besoins de traitement des données en évolution rapide. Elles ont été confrontées à des défis pour gérer les changements au niveau du schéma, l’évolution des schémas de partition et le retour en arrière pour examiner les données.
J’ai rencontré des défis similaires lors de la conception de systèmes distribués à grande échelle dans les années 2010 pour une grande entreprise technologique et un client du secteur de la santé. Certaines industries ont besoin de ces capacités pour se conformer aux réglementations bancaires, financières et sanitaires. Les entreprises fortement axées sur les données comme Netflix ont également rencontré des défis similaires. Elles ont inventé un format de table appelé « Iceberg », qui se superpose aux fichiers de données existants et offre des fonctionnalités clés en tirant parti de son architecture. Cela est rapidement devenu le principal projet ASF, suscitant un vif intérêt dans la communauté des données. Dans cet article, je vais explorer les 5 principales fonctionnalités clés d’Apache Iceberg avec des exemples et des diagrammes.
1. Voyage dans le temps

Figure 1 : Voyage dans le temps au format de table Apache Iceberg (image créée par l’auteur)
Cette fonctionnalité vous permet d’interroger vos données telles qu’elles existent à tout moment. Cela ouvrira de nouvelles possibilités pour les analystes de données et les analystes commerciaux afin de comprendre les tendances et comment les données ont évolué au fil du temps. Vous pouvez facilement revenir à un état précédent en cas d’erreurs. Cette fonctionnalité facilite également les vérifications d’audit en vous permettant d’analyser les données à un moment donné.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. Évolution du schéma
L’évolution du schéma d’Apache Iceberg permet des modifications de votre schéma sans aucun effort considérable ni migrations coûteuses. À mesure que les besoins de votre entreprise évoluent, vous pouvez :
- Ajouter et supprimer des colonnes sans temps d’arrêt ni réécriture de table.
- Mettre à jour la colonne (élargissement).
- Changer l’ordre des colonnes.
- Renommer une colonne existante.
Ces changements sont gérés au niveau des métadonnées sans avoir besoin de réécrire les données sous-jacentes.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. Évolution des partitions
En utilisant le format de table Apache Iceberg, vous pouvez changer la stratégie de partitionnement de la table sans réécrire la table sous-jacente ni migrer les données vers une nouvelle table. Cela est rendu possible car les requêtes ne font pas référence aux valeurs de partition directement comme dans Apache Hadoop. Iceberg conserve séparément les informations de métadonnées pour chaque version de partition. Cela facilite l’obtention des séparations lors de l’interrogation des données. Par exemple, interroger une table en fonction de la plage de dates, tandis que la table utilisait le mois comme colonne de partition (avant) comme une séparation et le jour comme nouvelle colonne de partition (après) comme une autre séparation. Cela s’appelle la planification des séparations. Voir l’exemple ci-dessous.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. Transactions ACID
Iceberg fournit un support robuste pour les transactions en termes de Atomicité, Cohérence, Isolation et Durabilité (ACID). Il permet plusieurs opérations d’écriture concurrentes, ce qui permet un haut débit dans des tâches lourdes en données sans compromettre la cohérence des données.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
Toutes les opérations dans Iceberg sont transactionnelles, ce qui signifie que les données restent cohérentes malgré les pannes ou les modifications des données de manière concurrente.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
Il prend également en charge différents niveaux d’isolation, ce qui vous permet d’équilibrer performance et cohérence en fonction des exigences.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
Voici un résumé montrant comment Iceberg gère les mises à jour et suppressions au niveau des lignes.
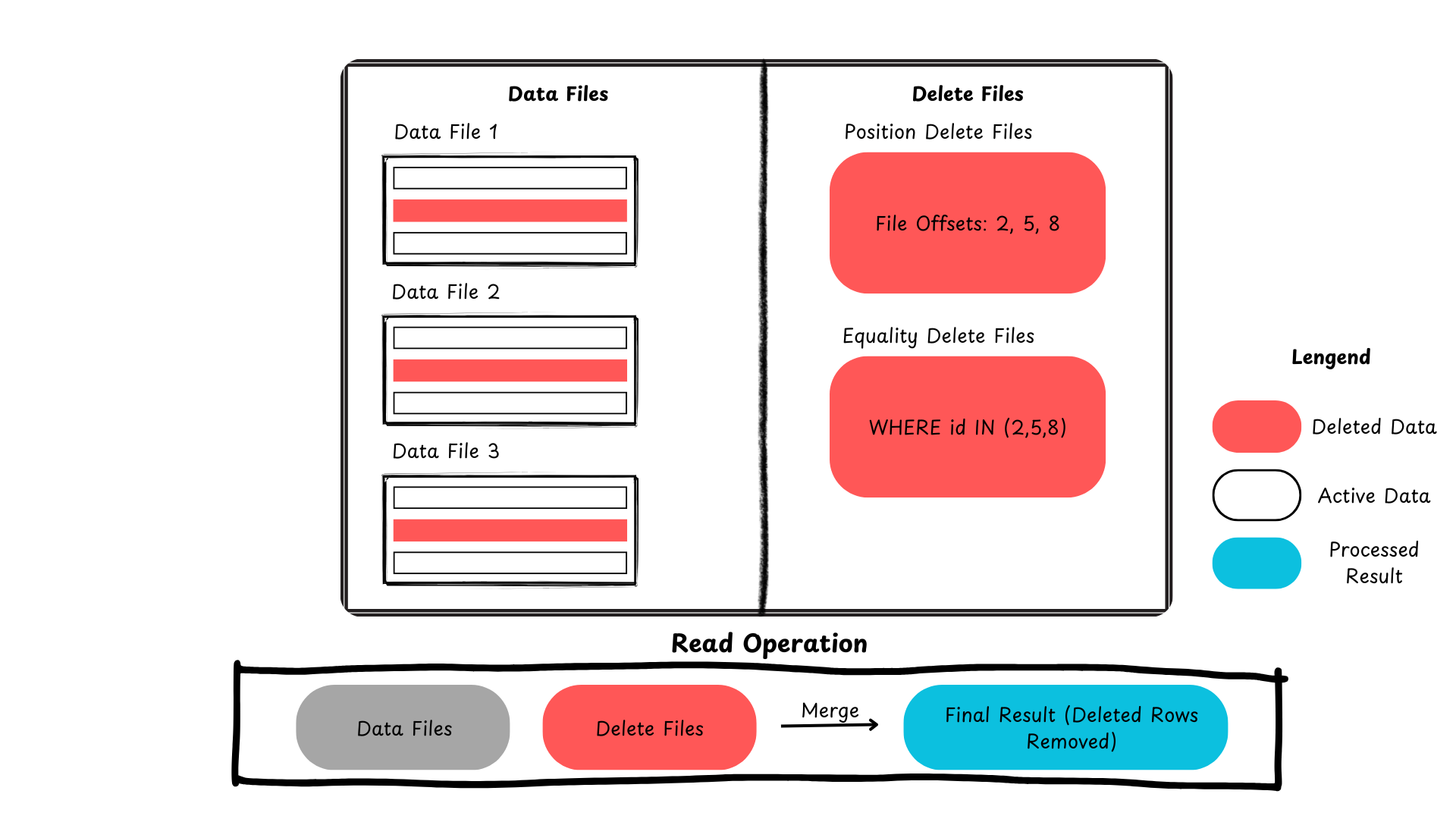
Figure 2 : Processus de suppression des enregistrements dans Apache Iceberg (image créée par l’auteur)
5. Opérations avancées sur les tables
Iceberg prend en charge des opérations avancées sur les tables telles que :
- Création/gestion des instantanés de table : Cela donne la possibilité d’avoir un contrôle de version robuste.
- Planification et exécution de requêtes rapides grâce à ses métadonnées hautement optimisées
- Outils intégrés pour la maintenance des tables, tels que la compactage et le nettoyage des fichiers orphelins
Iceberg est conçu pour fonctionner avec tous les principaux services de stockage cloud, tels que AWS S3, GCS et Azure Blob Storage. De plus, Iceberg s’intègre facilement avec des moteurs de traitement de données tels que Spark, Presto, Trino et Hive.
Réflexions finales
Ces fonctionnalités mises en avant permettent aux entreprises de construire des lacs de données modernes, flexibles, évolutifs et efficaces, capables de voyager dans le temps, de gérer facilement les changements de schéma, de supporter les transactions ACID et d’évoluer en partition.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes