













Existen muchas situaciones en las que puede necesitar exportar datos de XML a MongoDB.
A pesar de que los formatos XML y JSON(B) utilizados en MongoDB tienen mucho en común, también presentan algunas diferencias que los hacen no intercambiables.
Por lo tanto, antes de enfrentarse a la tarea de exportar datos de XML a MongoDB, necesitará:
- Es necesario escribir sus propios scripts de análisis XML;
- Utilizar herramientas ETL.
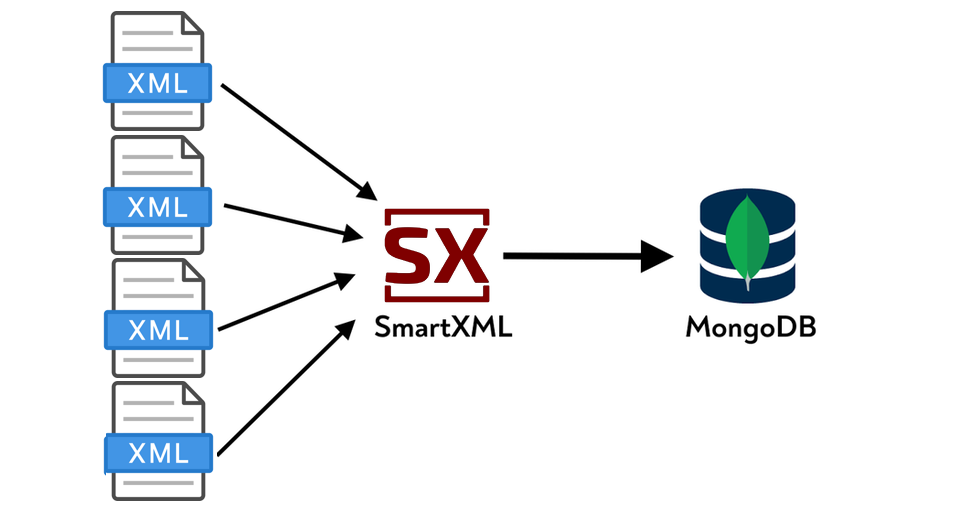
Aunque los modelos de lenguaje modernos pueden escribir scripts de análisis bastante bien en lenguajes como Python, estos scripts tendrán un problema grave: no estarán unificados. Para cada tipo de archivo, los modelos de lenguaje modernos generarán un script separado. Si tiene más de un tipo de XML, esto ya crea problemas significativos en el mantenimiento de más de un script de análisis.
El problema anterior suele resolverse utilizando herramientas ETL especializadas. En este artículo, analizaremos una herramienta ETL llamada SmartXML. Aunque SmartXML también admite la conversión de XML a una representación relacional, solo veremos el proceso de carga de XML en MongoDB.
El XML real puede ser extremadamente grande y complejo. Este artículo es introductorio, por lo que analizaremos una situación en la que:
- Todo el XML tiene la misma estructura;
- El modelo lógico del XML es el mismo que el modelo de almacenamiento en MongoDB;
- Los campos extraídos no necesitan un procesamiento complejo;
Cubriremos esos casos más adelante, pero primero, examinemos un ejemplo sencillo:
<marketingData>
<customer>
<name>John Smith</name>
<email>[email protected]</email>
<purchases>
<purchase>
<product>Smartphone</product>
<category>Electronics</category>
<price>700</price>
<store>TechWorld</store>
<location>New York</location>
<purchaseDate>2025-01-10</purchaseDate>
</purchase>
<purchase>
<product>Wireless Earbuds</product>
<category>Audio</category>
<price>150</price>
<store>GadgetStore</store>
<location>New York</location>
<purchaseDate>2025-01-11</purchaseDate>
</purchase>
</purchases>
<importantInfo>
<loyaltyStatus>Gold</loyaltyStatus>
<age>34</age>
<gender>Male</gender>
<membershipID>123456</membershipID>
</importantInfo>
<lessImportantInfo>
<browser>Chrome</browser>
<deviceType>Mobile</deviceType>
<newsletterSubscribed>true</newsletterSubscribed>
</lessImportantInfo>
</customer>
<customer>
<name>Jane Doe</name>
<email>[email protected]</email>
<purchases>
<purchase>
<product>Laptop</product>
<category>Electronics</category>
<price>1200</price>
<store>GadgetStore</store>
<location>San Francisco</location>
<purchaseDate>2025-01-12</purchaseDate>
</purchase>
<purchase>
<product>USB-C Adapter</product>
<category>Accessories</category>
<price>30</price>
<store>TechWorld</store>
<location>San Francisco</location>
<purchaseDate>2025-01-13</purchaseDate>
</purchase>
<purchase>
<product>Keyboard</product>
<category>Accessories</category>
<price>80</price>
<store>OfficeMart</store>
<location>San Francisco</location>
<purchaseDate>2025-01-14</purchaseDate>
</purchase>
</purchases>
<importantInfo>
<loyaltyStatus>Silver</loyaltyStatus>
<age>28</age>
<gender>Female</gender>
<membershipID>654321</membershipID>
</importantInfo>
<lessImportantInfo>
<browser>Safari</browser>
<deviceType>Desktop</deviceType>
<newsletterSubscribed>false</newsletterSubscribed>
</lessImportantInfo>
</customer>
<customer>
<name>Michael Johnson</name>
<email>[email protected]</email>
<purchases>
<purchase>
<product>Headphones</product>
<category>Audio</category>
<price>150</price>
<store>AudioZone</store>
<location>Chicago</location>
<purchaseDate>2025-01-05</purchaseDate>
</purchase>
</purchases>
<importantInfo>
<loyaltyStatus>Bronze</loyaltyStatus>
<age>40</age>
<gender>Male</gender>
<membershipID>789012</membershipID>
</importantInfo>
<lessImportantInfo>
<browser>Firefox</browser>
<deviceType>Tablet</deviceType>
<newsletterSubscribed>true</newsletterSubscribed>
</lessImportantInfo>
</customer>
<customer>
<name>Emily Davis</name>
<email>[email protected]</email>
<purchases>
<purchase>
<product>Running Shoes</product>
<category>Sportswear</category>
<price>120</price>
<store>FitShop</store>
<location>Los Angeles</location>
<purchaseDate>2025-01-08</purchaseDate>
</purchase>
<purchase>
<product>Yoga Mat</product>
<category>Sportswear</category>
<price>40</price>
<store>FitShop</store>
<location>Los Angeles</location>
<purchaseDate>2025-01-09</purchaseDate>
</purchase>
</purchases>
<importantInfo>
<loyaltyStatus>Gold</loyaltyStatus>
<age>25</age>
<gender>Female</gender>
<membershipID>234567</membershipID>
</importantInfo>
<lessImportantInfo>
<browser>Edge</browser>
<deviceType>Mobile</deviceType>
<newsletterSubscribed>false</newsletterSubscribed>
</lessImportantInfo>
</customer>
<customer>
<name>Robert Brown</name>
<email>[email protected]</email>
<purchases>
<purchase>
<product>Smartwatch</product>
<category>Wearable</category>
<price>250</price>
<store>GadgetPlanet</store>
<location>Boston</location>
<purchaseDate>2025-01-07</purchaseDate>
</purchase>
<purchase>
<product>Fitness Band</product>
<category>Wearable</category>
<price>100</price>
<store>HealthMart</store>
<location>Boston</location>
<purchaseDate>2025-01-08</purchaseDate>
</purchase>
</purchases>
<importantInfo>
<loyaltyStatus>Silver</loyaltyStatus>
<age>37</age>
<gender>Male</gender>
<membershipID>345678</membershipID>
</importantInfo>
<lessImportantInfo>
<browser>Chrome</browser>
<deviceType>Mobile</deviceType>
<newsletterSubscribed>true</newsletterSubscribed>
</lessImportantInfo>
</customer>
</marketingData>
En este ejemplo, subiremos al MongoDB solo los campos que sirven a un propósito práctico, en lugar de todo el XML.
Crear un nuevo proyecto
Se recomienda crear un nuevo proyecto desde la interfaz gráfica. Esto creará automáticamente la estructura de carpetas necesaria y las reglas de análisis. Una descripción completa de la estructura del proyecto se puede encontrar en la documentación oficial.
Todos los parámetros descritos en este artículo se pueden configurar en modo gráfico, pero para mayor claridad, nos enfocaremos en la representación textual.
Además del archivo config.txt con la configuración del proyecto, job.txt para trabajos por lotes, el proyecto en sí consta de:
- Plantilla de vista interna interna
SmartDOM, ubicada en la carpeta del proyectotemplates/data-templates.red. - Reglas para el procesamiento y transformación del
SmartDOMen sí, ubicadas en la carpetarules.
Consideremos la estructura de data-templates.red:
#[
sample: #[
marketing_data: #[
customers: [
customer: [
name: none
email: none
purchases: [
purchase: [
product: none
category: none
price: none
store: none
location: none
purchase_date: none
]
]
]
]
]
]
]
Nota
- El nombre
samplees el nombre de la categoría y no importa. - El
marketing_dataes el nombre de la subcategoría. Necesitamos al menos una subcategoría de código (subtipo). - Los nombres de vista intermedios no requieren coincidencias exactas con los nombres de las etiquetas XML. En este ejemplo, usamos intencionalmente el estilo
snake_case.
Extraer Reglas
Las reglas se encuentran en el directorio rules en la carpeta del proyecto.
Cuando trabajamos con MongoDB, solo nos interesan dos reglas:
tags-matching-rules.red– establece las coincidencias entre el árbol de etiquetas XML y SmartDOMgrow-rules.red– describe la relación entre los nodos de SmartDOM y los nodos reales de XML
sample: [
purchase: ["purchase"]
customer: ["customer"]
]
La clave será el nombre del nodo en SmartDOM; el valor será una matriz que contiene las variantes de escritura del nodo del archivo XML real. En nuestro ejemplo, estos nombres son iguales.
Etiquetas Ignoradas
Para evitar cargar datos menores en MongoDB en el ejemplo anterior, creamos archivos en la carpeta ignores – uno por sección, nombrado según cada sección. Estos archivos contienen listas de etiquetas para omitir durante la extracción. Para nuestro ejemplo, tendremos un archivo sample.txt que contiene:
["marketingData" "customer" "lessImportantInfo" "browser"]
["marketingData" "customer" "lessImportantInfo" "deviceType"]
["marketingData" "customer" "lessImportantInfo" "newsletterSubscribed"]
Como resultado, al analizar la morfología, la representación intermedia tomará la siguiente forma:
customers: [
customer: [
name: "John Smith"
email: "[email protected]"
loyalty_status: "Gold"
age: "34"
gender: "Male"
membership_id: "123456"
purchases: [
purchase: [
product: "Smartphone"
category: "Electronics"
price: "700"
store: "TechWorld"
location: "New York"
purchase_date: "2025-01-10"
]
]
]
]
Tenga en cuenta que después del análisis morfológico, solo se muestra una representación mínima que contiene datos de los nodos encontrados en primer lugar.
Aquí está el archivo JSON que se generará:
{
"customers": [
{
"name": "John Smith",
"email": "[email protected]",
"loyalty_status": "Gold",
"age": "34",
"gender": "Male",
"membership_id": "123456",
"purchases": [
{
"product": "Smartphone",
"category": "Electronics",
"price": "700",
"store": "TechWorld",
"location": "New York",
"purchase_date": "2025-01-10"
},
{
"product": "Wireless Earbuds",
"category": "Audio",
"price": "150",
"store": "GadgetStore",
"location": "New York",
"purchase_date": "2025-01-11"
}
]
},
{
"name": "Jane Doe",
"email": "[email protected]",
"loyalty_status": "Silver",
"age": "28",
"gender": "Female",
"membership_id": "654321",
"purchases": [
{
"product": "Laptop",
"category": "Electronics",
"price": "1200",
"store": "GadgetStore",
"location": "San Francisco",
"purchase_date": "2025-01-12"
},
{
"product": "USB-C Adapter",
"category": "Accessories",
"price": "30",
"store": "TechWorld",
"location": "San Francisco",
"purchase_date": "2025-01-13"
},
{
"product": "Keyboard",
"category": "Accessories",
"price": "80",
"store": "OfficeMart",
"location": "San Francisco",
"purchase_date": "2025-01-14"
}
]
},
{
"name": "Michael Johnson",
"email": "[email protected]",
"loyalty_status": "Bronze",
"age": "40",
"gender": "Male",
"membership_id": "789012",
"purchases": [
{
"product": "Headphones",
"category": "Audio",
"price": "150",
"store": "AudioZone",
"location": "Chicago",
"purchase_date": "2025-01-05"
}
]
},
{
"name": "Emily Davis",
"email": "[email protected]",
"loyalty_status": "Gold",
"age": "25",
"gender": "Female",
"membership_id": "234567",
"purchases": [
{
"product": "Running Shoes",
"category": "Sportswear",
"price": "120",
"store": "FitShop",
"location": "Los Angeles",
"purchase_date": "2025-01-08"
},
{
"product": "Yoga Mat",
"category": "Sportswear",
"price": "40",
"store": "FitShop",
"location": "Los Angeles",
"purchase_date": "2025-01-09"
}
]
},
{
"name": "Robert Brown",
"email": "[email protected]",
"loyalty_status": "Silver",
"age": "37",
"gender": "Male",
"membership_id": "345678",
"purchases": [
{
"product": "Smartwatch",
"category": "Wearable",
"price": "250",
"store": "GadgetPlanet",
"location": "Boston",
"purchase_date": "2025-01-07"
},
{
"product": "Fitness Band",
"category": "Wearable",
"price": "100",
"store": "HealthMart",
"location": "Boston",
"purchase_date": "2025-01-08"
}
]
}
]
}
Configurando Conexión a MongoDB
Dado que MongoDB no admite la inserción directa de datos HTTP, se requerirá un servicio intermedio.
Instalemos las dependencias: pip install flask pymongo.
El servicio en sí:
from flask import Flask, request, jsonify
from pymongo import MongoClient
import json
app = Flask(__name__)
# Connection to MongoDB
client = MongoClient('mongodb://localhost:27017')
db = client['testDB']
collection = db['testCollection']
.route('/insert', methods=['POST'])
def insert_document():
try:
# Flask will automatically parse JSON if Content-Type: application/json
data = request.get_json()
if not data:
return jsonify({"error": "Empty JSON payload"}), 400
result = collection.insert_one(data)
return jsonify({"insertedId": str(result.inserted_id)}), 200
except Exception as e:
import traceback
print(traceback.format_exc())
return jsonify({"error": str(e)}), 500
if __name__ == '__main__':
app.run(port=3000)
Vamos a configurar los ajustes de conexión a MongoDB en el archivo config.txt (ver nosql-url):
job-number: 1
root-xml-folder: "D:/data/data-samples"
xml-filling-stat: false ; table: filling_percent_stat should exists
ignore-namespaces: false
ignore-tag-attributes: false
use-same-morphology-for-same-file-name-pattern: false
skip-schema-version-tag: true
use-same-morphology-for-all-files-in-folder: false
delete-data-before-insert: none
connect-to-db-at-project-opening: true
source-database: "SQLite" ; available values: PostgreSQL/SQLite
target-database: "SQLite" ; available values: PostgreSQL/SQLite/NoSQL
bot-chatID: ""
bot-token: ""
telegram-notifications: true
db-driver: ""
db-server: "127.0.0.1"
db-port: ""
db-name: ""
db-user: ""
db-pass: ""
sqlite-driver-name: "SQLite3 ODBC Driver"
sqlite-db-path: ""
nosql-url: "http://127.0.0.1:3000/insert"
append-subsection-name-to-nosql-url: false
no-sql-login: "" ; login and pass are empty
no-sql-pass: ""
Recuerda que MongoDB creará automáticamente una base de datos y una colección del mismo nombre si no existen. Sin embargo, este comportamiento puede causar errores, por lo que se recomienda deshabilitarlo de forma predeterminada.
¡Vamos a ejecutar el servicio en sí!
python .\app.py
Siguiente, haz clic en Parse, , luego Envía JSON a NoSQL.

Ahora conecta a la consola de MongoDB de cualquier manera conveniente y ejecuta los siguientes comandos:
show databases
admin 40.00 KiB
config 72.00 KiB
local 72.00 KiB
testDB 72.00 KiB
use testDB
switched to db testDB
db.testCollection.find().pretty()
El resultado debería lucir como sigue:
{
_id: ObjectId('278e1b2c7c1823d4fde120ef'),
customers: [
{
name: 'John Smith',
email: '[email protected]',
loyalty_status: 'Gold',
age: '34',
gender: 'Male',
membership_id: '123456',
purchases: [
{
product: 'Smartphone',
category: 'Electronics',
price: '700',
store: 'TechWorld',
location: 'New York',
purchase_date: '2025-01-10'
},
{
product: 'Wireless Earbuds',
category: 'Audio',
price: '150',
store: 'GadgetStore',
location: 'New York',
purchase_date: '2025-01-11'
}
]
},
{
name: 'Jane Doe',
email: '[email protected]',
loyalty_status: 'Silver',
age: '28',
gender: 'Female',
membership_id: '654321',
purchases: [
{
product: 'Laptop',
category: 'Electronics',
price: '1200',
store: 'GadgetStore',
location: 'San Francisco',
purchase_date: '2025-01-12'
},
{
product: 'USB-C Adapter',
category: 'Accessories',
price: '30',
store: 'TechWorld',
location: 'San Francisco',
purchase_date: '2025-01-13'
},
{
product: 'Keyboard',
category: 'Accessories',
price: '80',
store: 'OfficeMart',
location: 'San Francisco',
purchase_date: '2025-01-14'
}
]
},
{
name: 'Michael Johnson',
email: '[email protected]',
loyalty_status: 'Bronze',
age: '40',
gender: 'Male',
membership_id: '789012',
purchases: [
{
product: 'Headphones',
category: 'Audio',
price: '150',
store: 'AudioZone',
location: 'Chicago',
purchase_date: '2025-01-05'
}
]
},
{
name: 'Emily Davis',
email: '[email protected]',
loyalty_status: 'Gold',
age: '25',
gender: 'Female',
membership_id: '234567',
purchases: [
{
product: 'Running Shoes',
category: 'Sportswear',
price: '120',
store: 'FitShop',
location: 'Los Angeles',
purchase_date: '2025-01-08'
},
{
product: 'Yoga Mat',
category: 'Sportswear',
price: '40',
store: 'FitShop',
location: 'Los Angeles',
purchase_date: '2025-01-09'
}
]
},
{
name: 'Robert Brown',
email: '[email protected]',
loyalty_status: 'Silver',
age: '37',
gender: 'Male',
membership_id: '345678',
purchases: [
{
product: 'Smartwatch',
category: 'Wearable',
price: '250',
store: 'GadgetPlanet',
location: 'Boston',
purchase_date: '2025-01-07'
},
{
product: 'Fitness Band',
category: 'Wearable',
price: '100',
store: 'HealthMart',
location: 'Boston',
purchase_date: '2025-01-08'
}
]
}
]
}
Conclusión
En este ejemplo, hemos visto cómo podemos automatizar la carga de archivos XML a MongoDB sin necesidad de escribir ningún código. Aunque el ejemplo solo considera un archivo, es posible dentro del marco de un proyecto tener una gran cantidad de tipos y subtipos de archivos con estructuras diferentes, así como realizar manipulaciones bastante complejas, como la conversión de tipos y el uso de servicios externos para procesar valores de campos en tiempo real. Esto permite no solo la descarga de datos desde XML, sino también el procesamiento de algunos de los valores a través de una API externa, incluido el uso de grandes modelos de lenguaje.