













Kong Gateway ist ein quelloffenes API-Gateway, das sicherstellt, dass nur die richtigen Anfragen hereingelassen werden, während es Sicherheit, Rate Limiting, Logging und mehr verwaltet. OPA (Open Policy Agent) ist ein quelloffener Policy-Engine, der die Kontrolle über Ihre Sicherheits- und Zugriffsbeschlüsse übernimmt. Stellen Sie sich ihn als das Gehirn vor, das die Policy-Enforcement von Ihrer App ablöst, sodass Ihre Dienste sich keine Sorgen machen müssen, um Regeln durchzusetzen. Stattdessen übernimmt OPA die Denkarbeit mit seiner Rego-Sprache, wodurch Policies über APIs, Microservices oder sogar Kubernetes evaluiert werden. Es ist flexibel und sicher und macht die Aktualisierung von Policys mühelos. OPA arbeitet, indem es drei Schlüsselaspekte evaluiert: Input (Echtzeitdaten wie Anfragen), Daten (externe Informationen wie Benutzerrollen) und Policy (die Logik in Rego, die entscheidet, ob „erlaubt“ oder „verweigert“ wird). Gemeinsam ermöglichen diese Komponenten OPA, Ihre Sicherheit auf hohem Niveau zu halten, während die Dinge einfach und konsistent bleiben.
 Was möchten wir erreichen oder lösen?
Was möchten wir erreichen oder lösen?
Oftentimes, die Daten in OPA sind wie ein treuer alter Freund – statisch oder langsam veränderlich. Sie werden zusammen mit den ständig wechselnden Eingabedaten verwendet, um intelligente Entscheidungen zu treffen. Aber stellen Sie sich ein System mit einem ausgedehnten Netz von Mikroservices, vielen Benutzern und einer riesigen Datenbank wie PostgreSQL vor. Dieses System handhabt einen hohen Transaktionsvolumen pro Sekunde und muss seine Geschwindigkeit und Leistung ohne Probleme aufrecht erhalten.
Eine feine Zugriffssteuerung in solch einem System ist schwierig, aber mit OPA können Sie die arbeitige Last von Ihren Mikroservices abtragen und diese auf dem Gateway-Niveau abarbeiten. Durch die Zusammenarbeit mit dem Kong API Gateway und OPA erhalten Sie sowohl hervorragende Durchsatz als auch präzise Zugriffssteuerung.
Wie können Sie accurate User Data aufrecht erhalten, ohne dass die Dinge langsamer werden? Der ständige Zugriff auf diese PostgreSQL Datenbank, um Millionen von Daten zu holen, ist sowohl kostenintensiv als auch langsam. Der Erhalt von Genauigkeit und Geschwindigkeit erfordert normalerweise eine Kompromissicherung zwischen beiden. Lassen Sie uns eine praktische Balance finden, indem wir ein benutzerdefiniertes Plugin (auf Gateway-Niveau) entwickeln, das häufig Daten laden und lokal im Cache von OPA ablegt, um diese in der Evaluierung ihrer Strategien zu verwenden.
Demo
Für die Demo habe ich in PostgreSQL ein Beispieldatenbanken erstellt, die Benutzerinformationen wie Name, E-Mail und Rolle enthalten. Wenn ein Benutzer versucht, ein Dienst über eine bestimmte URL aufzurufen, bewertet OPA, ob der Anfrage zugelassen wird. Die Rego-Richtlinie prüft die Anfrage-URL (Ressource), den Methoden und die Rolle des Benutzers und gibt entweder true oder false basierend auf den Regeln zurück. Wenn wahr, ist der Zugriff zulässig; wenn falsch, wird der Zugriff verweigert. Bis jetzt ist es eine einfache Einrichtung. Lassen Sie uns im nächsten Abschnitt zu dem benutzerdefinierten Plugin springen. Um die Implementierung bessere zu verstehen, verwende bitte den Diagramm unten.
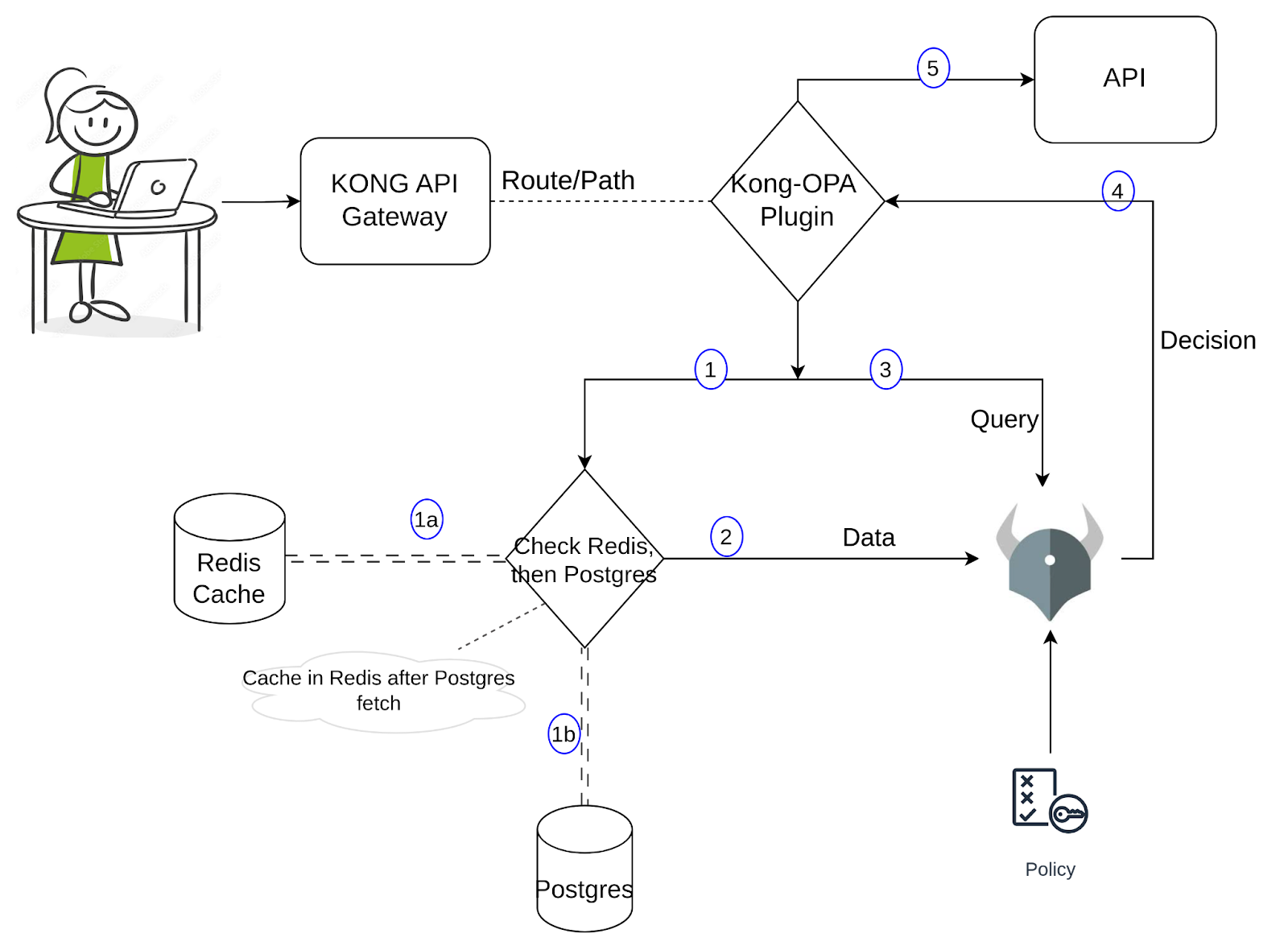
Wenn eine Anfrage durch den Kong-Proxy kommt, wird der Kong- benutzerdefinierte Plugin aktiviert. Der Plugin holt die erforderlichen Daten und sendet sie zusammen mit der Eingabe/Anfrage an OPA. Diese Datenerfassung umfasst zwei Teile: Der erste Teil besteht darin, Redis auf die erforderlichen Werte zu suchen und, wenn gefunden, sie an OPA weiterzugeben; andernfalls sucht er die Postgres weiter und holt die Daten und cacht sie in Redis, bevor er sie an OPA weitergibt. Wir können dies wieder anschauen, wenn wir in der nächsten Abschnitt Befehle ausführen und die Logs beobachten. OPA trifft eine Entscheidung (basierend auf der Politik, der Eingabe und den Daten) und wenn es erlaubt ist, sendet Kong die Anfrage an die API weiter. Mit dieser Methode wird die Anzahl der Abfragen an Postgres erheblich reduziert, wobei die OPA zur Verfügung stehenden Daten recht genau sind und die Latenzzeit niedrig bleibt.
Um mit der Erstellung eines benutzerdefinierten Plugins zu beginnen, brauchen wir eine handler.lua, in der die Kernlogik des Plugins implementiert ist, und eine schema.lua, die, wie der Name vermuten lässt, das Schema für die Konfiguration des Plugins definiert. Wenn du anfängst, zu lernen, wie du benutzerdefinierte Plugins für Kong schreibst, beziehst bitte diesen Link für weitere Informationen. Die Dokumentation erklärt auch, wie du das Plugin paketieren und installieren kannst. Lasst uns fortfahren und die Logik dieses Plugins zu verstehen.
Der erste Schritt der Demo besteht darin, OPA, Kong, Postgres und Redis auf deinem lokalen Setup oder einem Cloud-Setup zu installieren. Bitte klonen Sie in dieses Repositorys.
Prüfen Sie die docker-compose YAML, die die Konfigurationen definiert, um alle vier Dienste oben genannt zu deployen. Beobachten Sie die Kong-Umgebungsvariablen, um zu sehen, wie das benutzerdefinierte Plugin geladen wird.
Führen Sie die folgenden Befehle aus, um die Dienste zu deployen:
docker-compose build
docker-compose up

Nachdem wir die Container verifiziert haben, die aufrechtgehalten und ausgeführt werden, stehen Kong Manager und OPA auf den entsprechenden Endpunkten https://localhost:8002 und https://localhost:8181 zur Verfügung, wie unten gezeigt:
Erstellen Sie einen Testdienst, eine Route und fügen Sie dieser Route unser benutzerdefiniertes Kong-Plugin hinzu, indem Sie den folgenden Befehl verwenden:
curl -X POST http://localhost:8001/config -F config=@config.yaml
Die OPA-Richtlinie, definiert in der authopa.rego Datei, wird veröffentlicht und mit dem Befehl unten aktualisiert:
curl -X PUT http://localhost:8181/v1/policies/mypolicyId -H "Content-Type: application/json" --data-binary @authopa.rego
Dieses Beispielpolitik gewährt Zugriff auf Benutzereingaben nur dann, wenn der Benutzer den Pfad /demo mit dem GET-Verfahren aufsucht und die Rolle des "Moderators" hat. Zusätzliche Regeln können gemäß Bedarf hinzugefügt werden, um Zugriffskontrollen basierend auf verschiedenen Kriterien anzupassen.
opa_policy = [
{
"path": "/demo",
"method": "GET",
"allowed_roles": ["Moderator"]
}
]
Der Setup ist nun fertiggestellt, aber vor dem Test ist es notwendig, Testdaten in Postgres hinzuzufügen. Ich habe einige Beispieldaten (Name, E-Mail und Rolle) für einige Angestellte hinzugefügt, wie unten gezeigt (vgl. PostgresReadme).
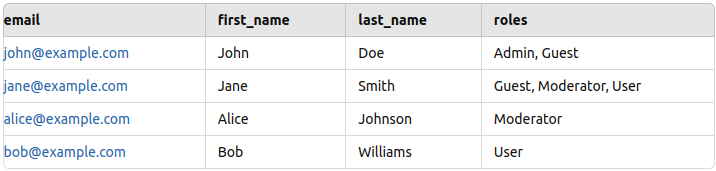
Hier ist ein Beispiel für einen fehlgeschlagenen und erfolgreichen Antrag:
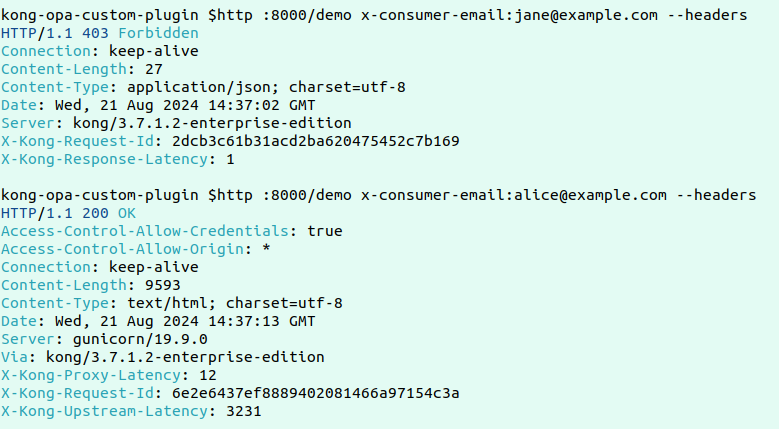
Nun, um die grundlegende Funktionalität dieses benutzerdefinierten Plugins zu testen, lassen Sie uns zwei aufeinanderfolgende Anträge tätigen und die Protokolle anschauen, um zu sehen, wie die Datenabfrage abläuft.
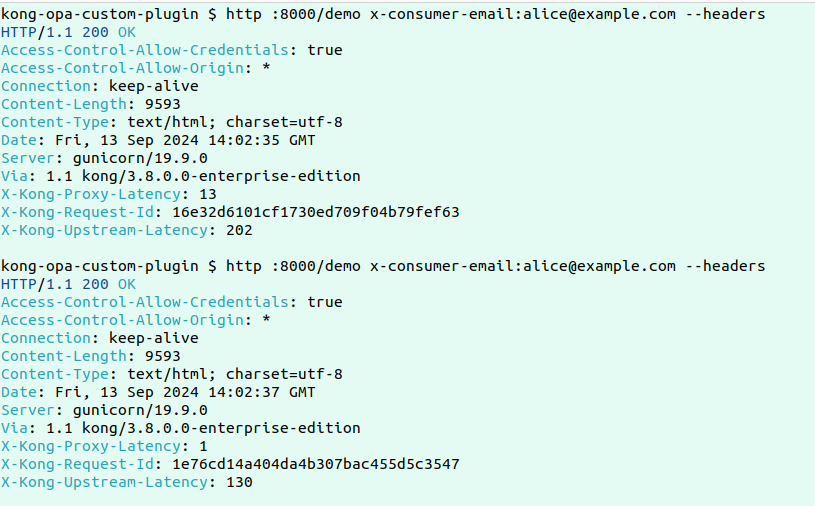 Hier sind die Protokolle:
Hier sind die Protokolle:
2024/09/13 14:05:05 [error] 2535#0: *10309 [kong] redis.lua:19 [authopa] No data found in Redis for key: [email protected], client: 192.168.96.1, server: kong, request: "GET /demo HTTP/1.1", host: "localhost:8000", request_id: "ebbb8b5b57ff4601ff194907e35a3002"
2024/09/13 14:05:05 [info] 2535#0: *10309 [kong] handler.lua:25 [authopa] Fetching roles from PostgreSQL for email: [email protected], client: 192.168.96.1, server: kong, request: "GET /demo HTTP/1.1", host: "localhost:8000", request_id: "ebbb8b5b57ff4601ff194907e35a3002"
2024/09/13 14:05:05 [info] 2535#0: *10309 [kong] postgres.lua:43 [authopa] Fetched roles: Moderator, client: 192.168.96.1, server: kong, request: "GET /demo HTTP/1.1", host: "localhost:8000", request_id: "ebbb8b5b57ff4601ff194907e35a3002"
2024/09/13 14:05:05 [info] 2535#0: *10309 [kong] handler.lua:29 [authopa] Caching user roles in Redis, client: 192.168.96.1, server: kong, request: "GET /demo HTTP/1.1", host: "localhost:8000", request_id: "ebbb8b5b57ff4601ff194907e35a3002"
2024/09/13 14:05:05 [info] 2535#0: *10309 [kong] redis.lua:46 [authopa] Data successfully cached in Redis, client: 192.168.96.1, server: kong, request: "GET /demo HTTP/1.1", host: "localhost:8000", request_id: "ebbb8b5b57ff4601ff194907e35a3002"
2024/09/13 14:05:05 [info] 2535#0: *10309 [kong] opa.lua:37 [authopa] Is Allowed by OPA: true, client: 192.168.96.1, server: kong, request: "GET /demo HTTP/1.1", host: "localhost:8000", request_id: "ebbb8b5b57ff4601ff194907e35a3002"
2024/09/13 14:05:05 [info] 2535#0: *10309 client 192.168.96.1 closed keepalive connection
------------------------------------------------------------------------------------------------------------------------
2024/09/13 14:05:07 [info] 2535#0: *10320 [kong] redis.lua:23 [authopa] Redis result: {"roles":["Moderator"],"email":"[email protected]"}, client: 192.168.96.1, server: kong, request: "GET /demo HTTP/1.1", host: "localhost:8000", request_id: "75bf7a4dbe686d0f95e14621b89aba12"
2024/09/13 14:05:07 [info] 2535#0: *10320 [kong] opa.lua:37 [authopa] Is Allowed by OPA: true, client: 192.168.96.1, server: kong, request: "GET /demo HTTP/1.1", host: "localhost:8000", request_id: "75bf7a4dbe686d0f95e14621b89aba12"
Die Protokolle zeigen, dass bei der ersten Anfrage, wenn keine Daten in Redis vorhanden sind, die Daten aus Postgres geholt und in Redis gecacht werden, bevor sie an OPA weitergeleitet werden für die Bewertung. Bei der nächsten Anfrage, da die Daten in Redis verfügbar sind, erfolgt die Antwort deutlich schneller.
Fazit
Zusammenfassend kann festgestellt werden, dass die Kombination von Kong Gateway mit OPA und die Implementierung eines benutzerdefinierten Plugins mit Redis-Caching eine effektive Ausgliederung von Genauigkeit und Geschwindigkeit für den Zugriffsschutz in hochlastigen Umgebungen ermöglicht. Das Plugin minimiert die Anzahl der kostspieligen Postgres-Abfragen, indem die Benutzerrollen in Redis nach der ersten Abfrage zwischengespeichert werden. Bei späteren Anfragen wird die Datenbank aus Redis gelesen, was die Latenzsignale deutlich reduziert, während aktuelle und genaue Benutzerinformationen für OPA-Policyschätzungen gewahrt werden. Dieser Ansatz stellt sicher, dass feine Zugriffskontrollen effizient auf Gateway-Ebene behandelt werden und keine Leistung oder Sicherheit opfern, was sie zu einer idealen Lösung für die Skalierung von Mikroservices macht, während präzise Zugriffsrichtlinien durchgesetzt werden.
Source:
https://dzone.com/articles/enhanced-api-security-fine-grained-access-control